



一、学习过程
今天讲了spark的安装和spark的运行机制,然后老师重点将了下spark中的RDD然后就是我们自己联系word上的实例和例子的时间了
二、总结
Spark我感觉用一天时远远不够的,老师文档就给我们发了七八个,这一下午也就看完了一个,今天我把RDD的20多个基本的函数看了一遍,然后按照word上的例子进行了总结,感觉RDD就是在用一些别人写好的mapreduce函数,他的代码量要比直接写mapreduce少的多,也正因为这个,对于RDD的一些函数的参数理解起来有一点点困难,不过一下午也不是白过的,对于那二十多个常用函数我已经基本上了解,这也是今天最主要的收获。
三、问题汇总
Spark的内容很多,感觉今天学到的东西离可以实际的去写一个简单的实际需求还差的很远,spark中的RDD与其他大数据模块的数据传递连接,以及他们之间的区别还没有弄清楚
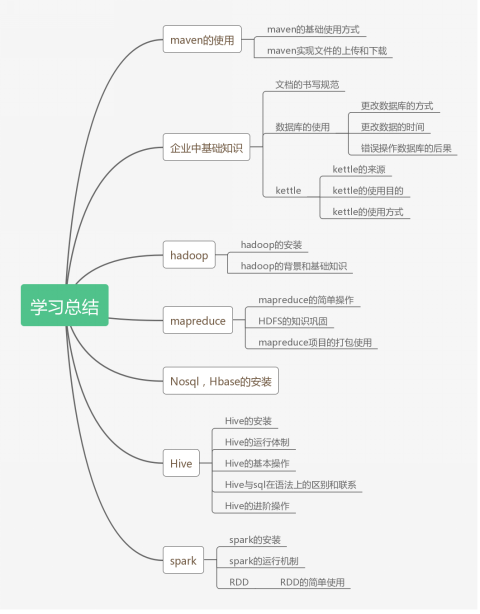
三、思维导图

















 1252
1252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









