




 本文介绍了特征处理中的标准化和归一化,包括它们的计算方法、适用范围以及不同情况下的选择。标准化适合数据存在异常值和噪音的情况,而归一化适用于对输出范围有要求的场景。在某些模型如SVM、KNN和神经网络中,标准化通常是首选。文章还提到,在数据集规模变化时,标准化的稳定性优于归一化。
本文介绍了特征处理中的标准化和归一化,包括它们的计算方法、适用范围以及不同情况下的选择。标准化适合数据存在异常值和噪音的情况,而归一化适用于对输出范围有要求的场景。在某些模型如SVM、KNN和神经网络中,标准化通常是首选。文章还提到,在数据集规模变化时,标准化的稳定性优于归一化。
特征处理方法总览:

标准化和归一化介绍:
(1)标准化
标准化需要计算特征的均值和标准差,公式表达为:

使用preproccessing库的StandardScaler类对数据进行标准化的代码如下
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
iris=load_iris()
#标准化,返回值为标准化后的数据
StandardScaler().fit_transform(iris.data)
(2)归一化

使用preproccessing库的Normalizer类对数据进行归一化的代码如下:
from sklearn.preprocessing import Normalizer
#归一化,返回值为归一化后的数据
Normalizer().fit_transform(iris.data)
区间缩放法其实是归一化的一种:
区间缩放法的思路有多种,常见的一种为利用两个最值进行缩放,公式表达为:
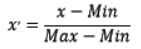
使用preproccessing库的MinMaxScaler类对数据进行区间缩放的代码如下:
from sklearn.preprocessing import MinMaxScaler
#区间缩放,返回值为缩放到[0, 1]区间的数据
MinMaxScaler().fit_transform(iris.data)
标准化和归一化适用范围
几条说明:
(1)如果对输出结果范围有要求,用归一化。
(2)如果数据较为稳定,不存在极端的最大最小值,用归一化。
(3)如果数据存在异常值和较多噪音,用标准化,可以间接通过中心化避免异常值和极端值的影响。
(4)SVM、KNN(K近邻)、神经网络、PCA等模型必须先标准化、归一化
优先使用标准化。对于输出有要求时再尝试别的方法,如归一化或者更加复杂的方法。很多方法都可以将输出范围调整到[0, 1],如果我们对于数据的分布有假设的话,更加有效的方法是使用相对应的概率密度函数来转换。
举个例子:
在大论文的计算中,我需要不断增加预测集的数量,但相对于训练集增加的个数相当少,此时只能用标准化。如果采用区间缩放法(归一化),则Max,Min值可能会变化,进而改变缩放的空间,但标准化是均值和标准差所以几乎不变。
归一化作用
详见链接
归一化的作用.


















 1255
1255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









