




 这篇博客介绍了Pandas的层次化索引,包括设置索引字段和多级索引的用法。接着讲解了Pandas数据合并的多种方式,如外连接、左连接、右连接,并展示了如何创建查询表。最后,重点讨论了Pandas读取和保存Excel文件的方法,包括使用pd.read_excel()和data.to_csv()。文章提供了实际的代码示例和注意事项。
这篇博客介绍了Pandas的层次化索引,包括设置索引字段和多级索引的用法。接着讲解了Pandas数据合并的多种方式,如外连接、左连接、右连接,并展示了如何创建查询表。最后,重点讨论了Pandas读取和保存Excel文件的方法,包括使用pd.read_excel()和data.to_csv()。文章提供了实际的代码示例和注意事项。
本文内容来自网易云课堂微专业数据分析学习笔记,授课为毕滢老师
安装更新pandas:pip install pandas --upgrade i https://mirrors.163.com/pypi/simple/
Pandas的层次化索引
同一个轴可以用多种方式索引(有类似于excel排序第1关键字第2关键字的意思)
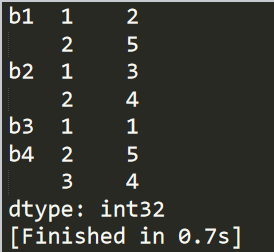
book_ratings=pd.Series(
np.random.randint(1,6,size=7),#待查询理解
index=[
['b1','b1','b2','b2','b3','b4','b4'],
[1,2,1,2,1,2,3]#有类似于excel排序第1关键字第2关键字的意思
]
)
print(book_ratings)给一个DataFrame指定索引字段
data.set_index(['指定索引字段名']) #当字段被指定为索引之后,在col里就视为没有了.
lookup=data2.set_index(['book_id','best_book_id']) #当索引字段是一个的时候,加不加方括号不影响,但有2个,则只有加了[]才有效.
Pandas数据合并
1.两个DataFrame进行合并(类似集合的操作)
book_name=pd.DataFrame({
'book_name':['a','b','c','d','e','f'],
'book_id':[11,22,33,44,55,66] #两者都有'book_id'
})
id_rating=pd.DataFrame({
'book_id':[11,22,22,44,55,66,33,11,55], #两者都有'book_id'
'rating':[1,3,5,2,4,3,2,4,5]
})
print(pd.merge(book_name,id_rating))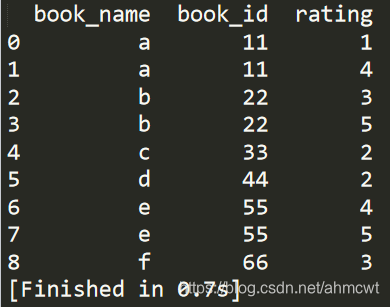
2.两个DataFrame进行合并,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 684
684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









