






 本文详细介绍了如何在Windows服务器上安装Zabbix-agent,实现CPU使用率、磁盘IO性能及磁盘空间监控,并配置邮件报警功能。此外,还提供了监控阈值调整、网卡自动发现规则优化的方法。
本文详细介绍了如何在Windows服务器上安装Zabbix-agent,实现CPU使用率、磁盘IO性能及磁盘空间监控,并配置邮件报警功能。此外,还提供了监控阈值调整、网卡自动发现规则优化的方法。

- Windows安装zabbix-agent
- 监控Windows-CPU使用率
-
监控Windows-磁盘IO性能监控
- 监控Windows/Linux-磁盘触发器阈值更改
- 监控Windows-网卡自动发现规则
- 配置服务端邮件报警功能
1、Windows服务器需要先安装zabbix-agent代理
概况
Zabbix agent部署在监控的目标上,主动监测本地的资源和应用(硬件驱动,内存,处理器统计等)。
Zabbix agent收集本地的操作信息并将数据报告给Zabbix server用于进一步处理。一旦出现异常 (比如硬盘空间已满或者有崩溃的服务进程), Zabbix server会主动警告管理员指定机器上的异常。
Zabbix agents的极端高效缘于它可以利用本地系统调用来完成统计数据的收集。
被动(passive)和主动(active)检查
Zabbix agents可以执行被动和主动两种检查方式。
Windows上的Zabbix agent是以Windows服务的形式运行的。
您可以在主机上运行Zabbix agent的单个实例或多个实例。
单个实例可以使用默认配置文件或命令行中指定的配置文件。
在多个实例的情况下,每个agent实例必须有自己独立的配置文件(其中一个实例可以使用默认配置文件)。
以下命令参数可以在Zabbix agent中使用:
| 参数 | 描述n |
|---|---|
| UNIX 和 Windows agent | |
| -c --config <config-file> | 配置文件的绝对路径。 您可以使用此选项来制定配置文件,而不是使用默认文件。\\在UNIX中, 默认文件是/usr/local/etc/zabbix_agentd.conf 要么通过 compile-time 变量 --sysconfdir 或者 --prefix来设置 在Windows中,默认文件是 c:\zabbix_agentd.conf |
| -p --print | 显示已知监控项并推出 Note: 为了同时返回用户参数user parameter 您必须制定配置文件 (如果不是在指定位置的话). |
| -t --test <item key> | 测试指定监控项并退出。 Note:为了同时返回用户参数 user parameter 您必须制定配置文件 (如果不是在指定位置的话). |
| -h --help | 显示帮助信息 |
| -V --version | 显示版本号 |
| 仅UNIX agent | |
| -R --runtime-control <option> | 执行管理功能。参见 运行时控制. runtime control. |
| 仅Windows agent | |
| -m --multiple-agents | 使用多agent实例 (使用 -i,-d,-s,-x )。 T为了区分实例的服务名称,每项服务名都会包涵来自配置文件里的主机名值。 |
| 仅Windows agent (功能) | |
| -i --install | 以服务的形式安装Zabbix Windows agent |
| -d --uninstall | 卸载Zabbix indows agent服务 |
| -s --start | 开始Zabbix Windows agent服务 |
| -x --stop | 停止bbix Windows agent 服务 |
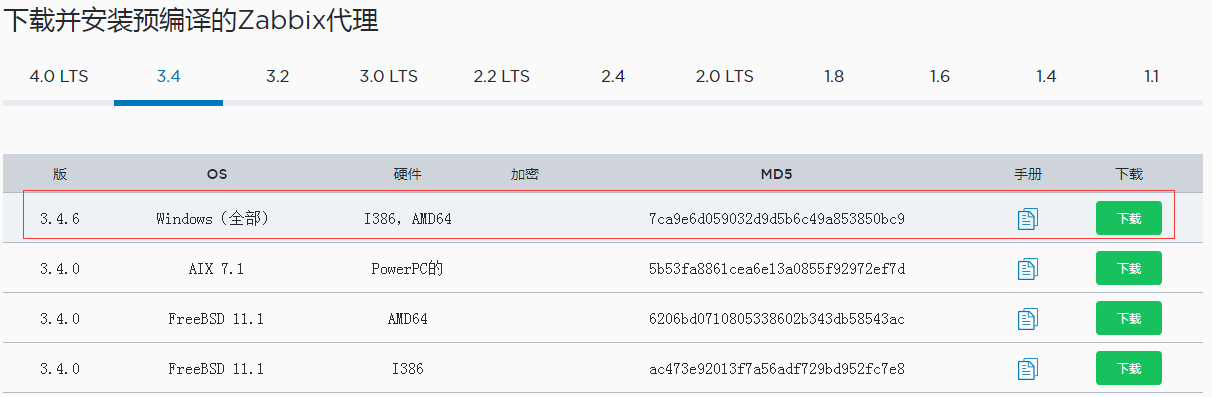
将上面下载的zabbix_agents_3.4.6.win.zip文件解压放到c盘里面
然后需要修改conf里面的zabbix_agentd.win.conf这个是配置文件
需要修改的配置选项:
LogFile=C:\zabbix_agents_3.4.6.win\log\zabbix_agentd.log ##这个是日志存放的地址
Server=192.168.10.10 ##这个是zabbix服务端的地址
ServerActive=192.168.10.10:10050 ##10050是zabbix-server和zabbix-agent通信的端口
Hostname=192.168.10.11 ##这个填写需要监控的Windows服务器IP
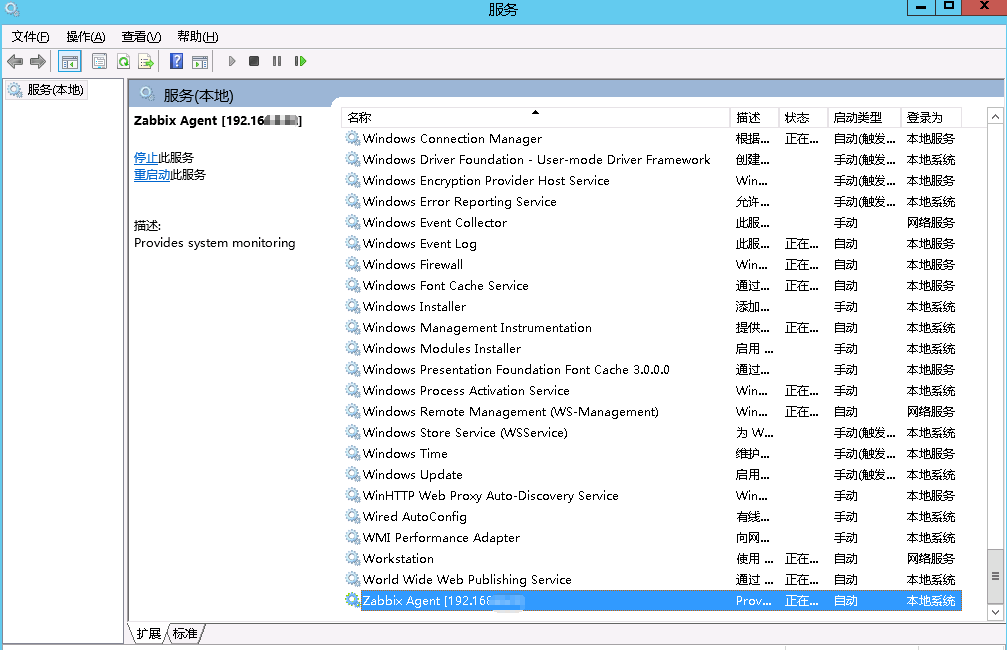
管理员权限运行cmd,如下图显示installed successfully代表成功了,再去服务里面启动zabbix-agent
##下面这一串命令是把agentd服务启动
C:\zabbix_agents_3.4.6.win\bin\win64\zabbix_agentd -i -m -c C:\zabbix_agents_3.4.6.win\conf\zabbix_agentd.win.conf

2、监控Windows-CPU使用率
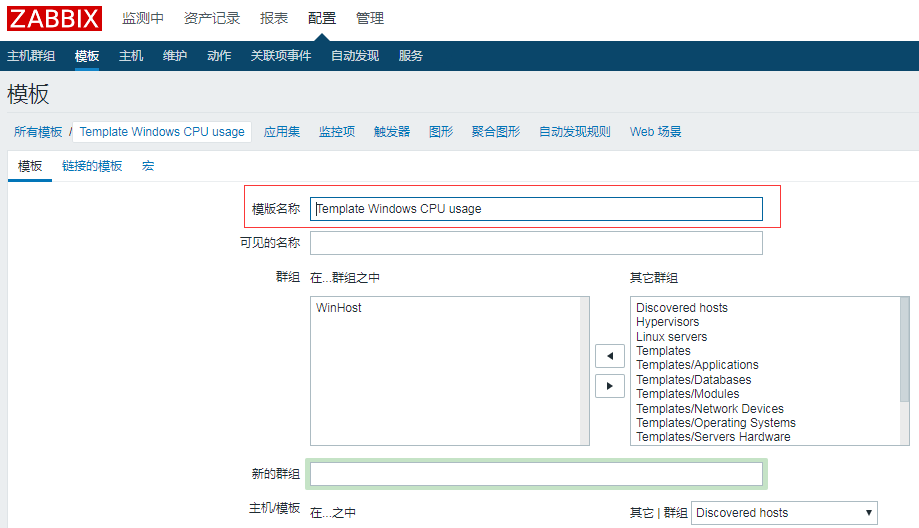
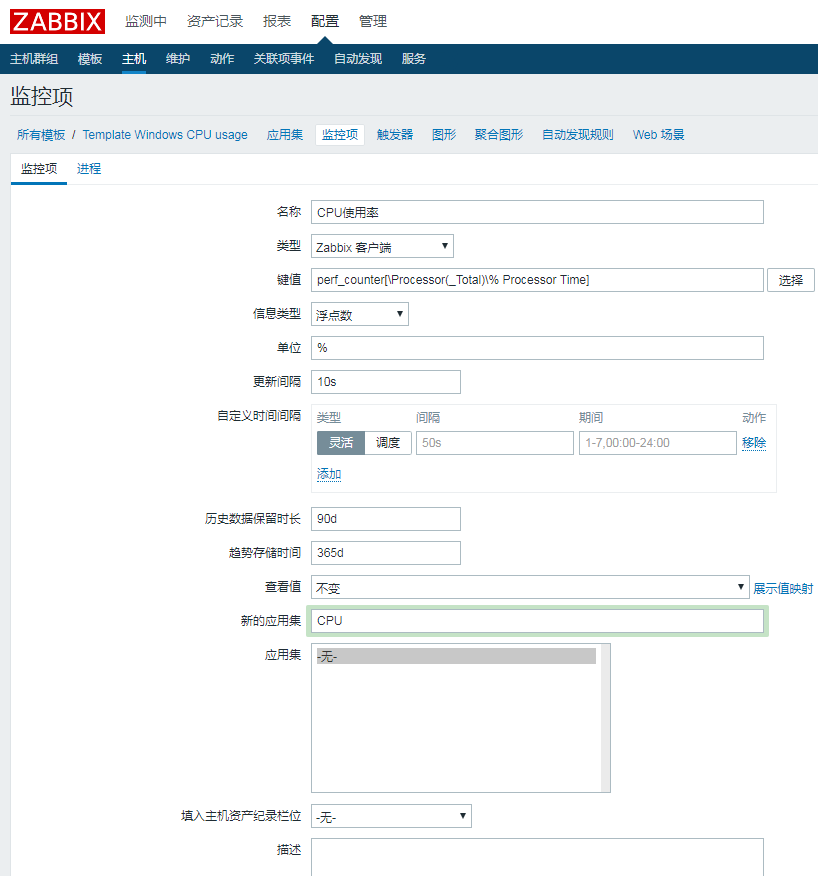
创建完监控项以后新建触发器,可以在表达式构造器测试这个触发器是否有用
名称:cpu used is more than 80%
严重性:一般严重
表达式:{Template Windows CPU usage:perf_counter[\Processor(_Total)\% Processor Time].avg(5m)}>80
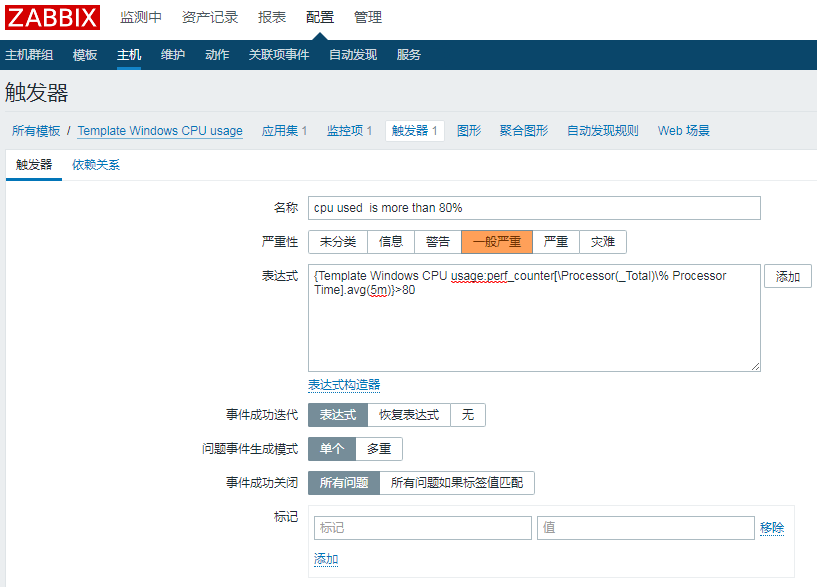
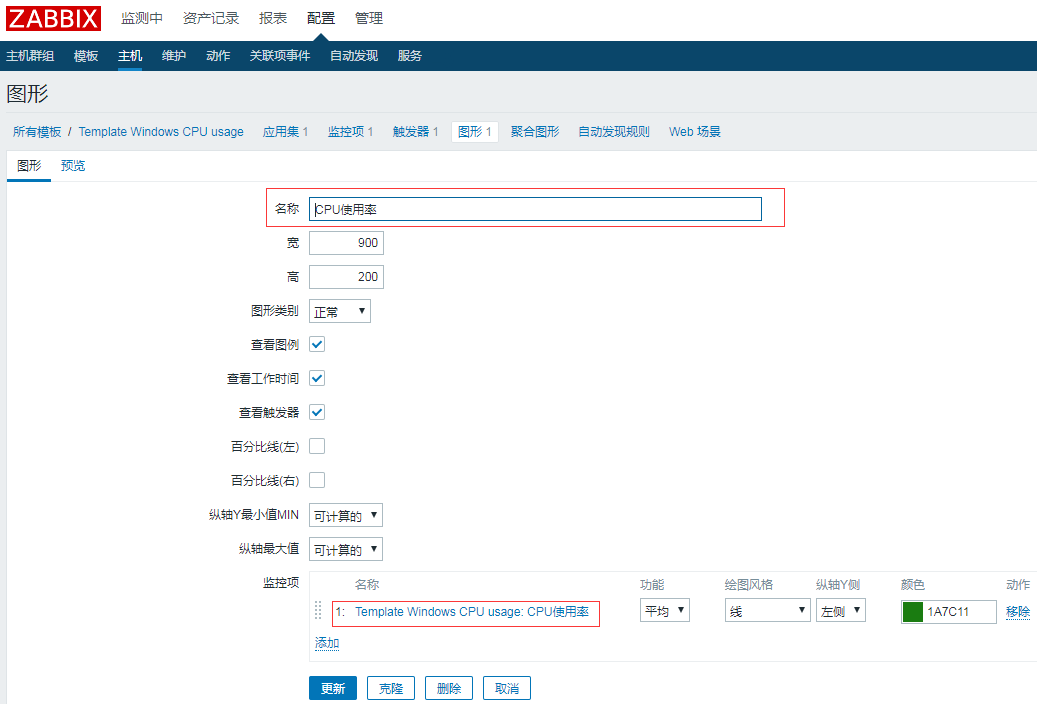
创建完触发器再添加一个图形查看cpu使用率图表
名称:CPU使用率
监控项:Template Windows CPU usage: CPU使用率
添加成功以后可以查看CPU图形表了,有数据代表成功监控了!
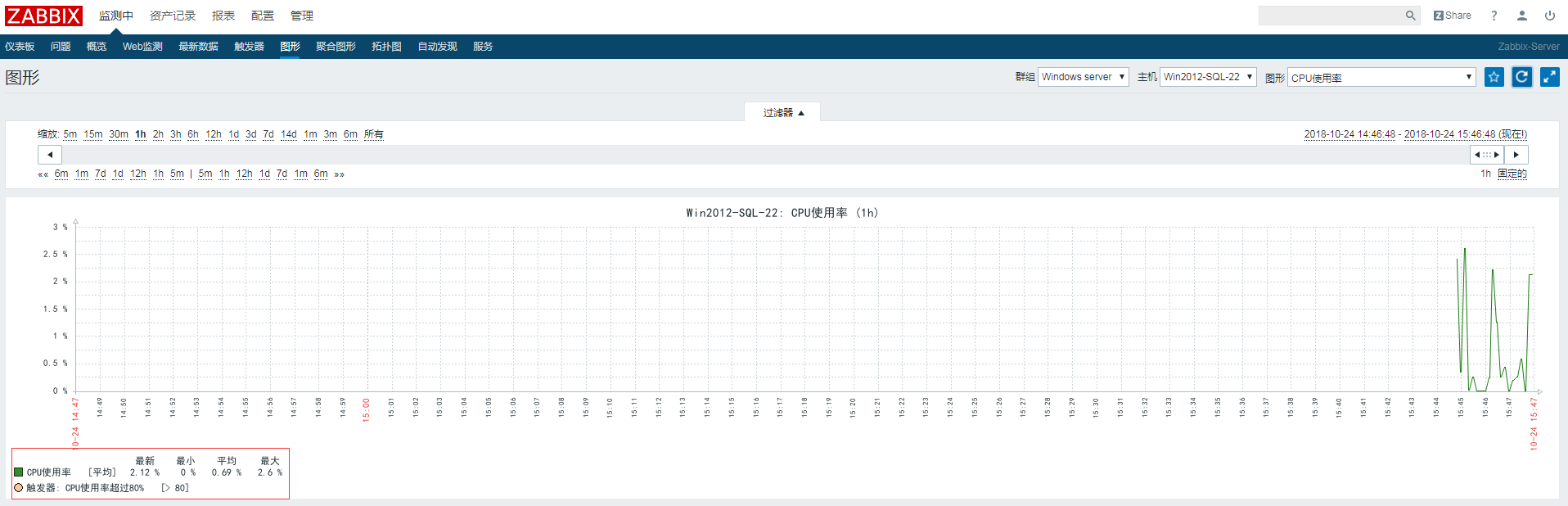
3、监控Windows-磁盘IO性能监控
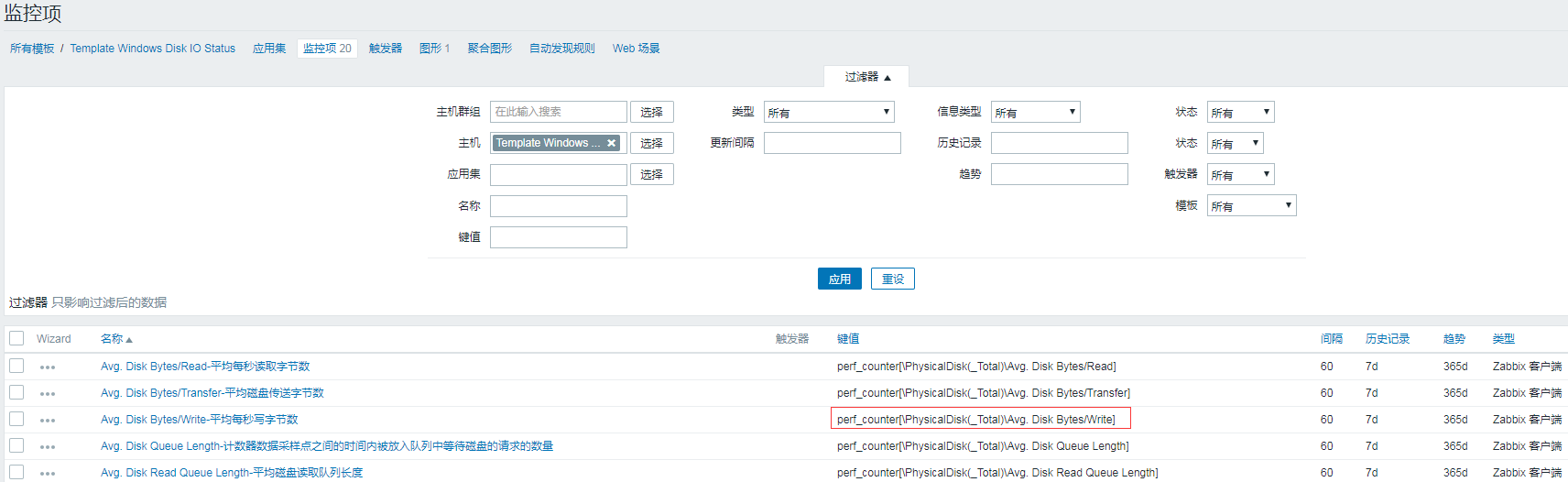
WIN下的IO性能监控,是通过调用性能计数器中的参数来获取
目前已经统计成模板,可直接使用,模板包括了图形和上图所示的监控项
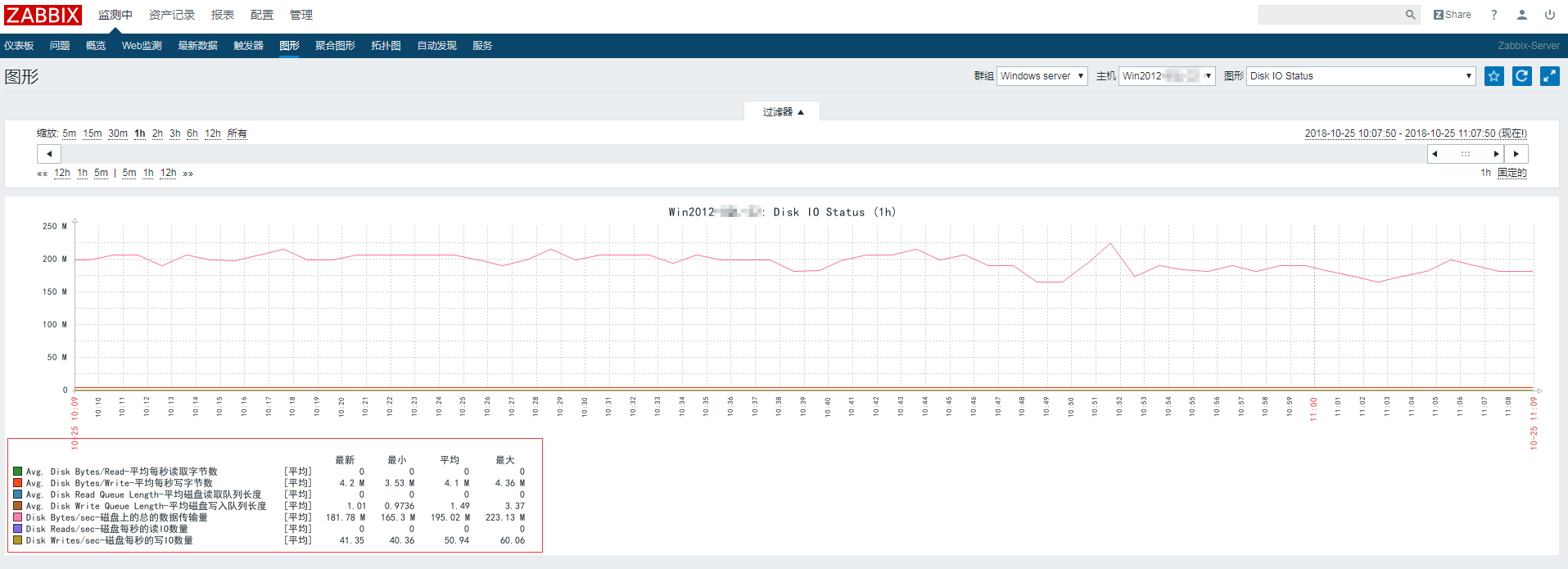
4、监控Windows-磁盘触发器阈值更改
选择配置--->模板--->(Template OS Linux/Template OS Windows)
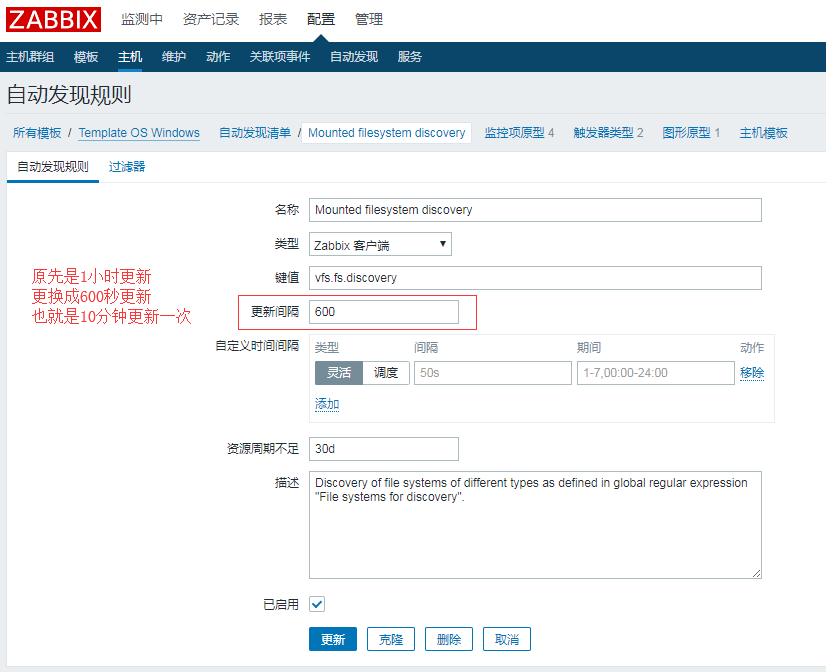
我这边是监控Windows所以修改Windows的模板,如果是监控Linux可以修改Linux的模板
默认是1小时更新一次,修改成600秒,就是10分钟更新一次,10分钟后就能看到网卡和磁盘的监控值了!

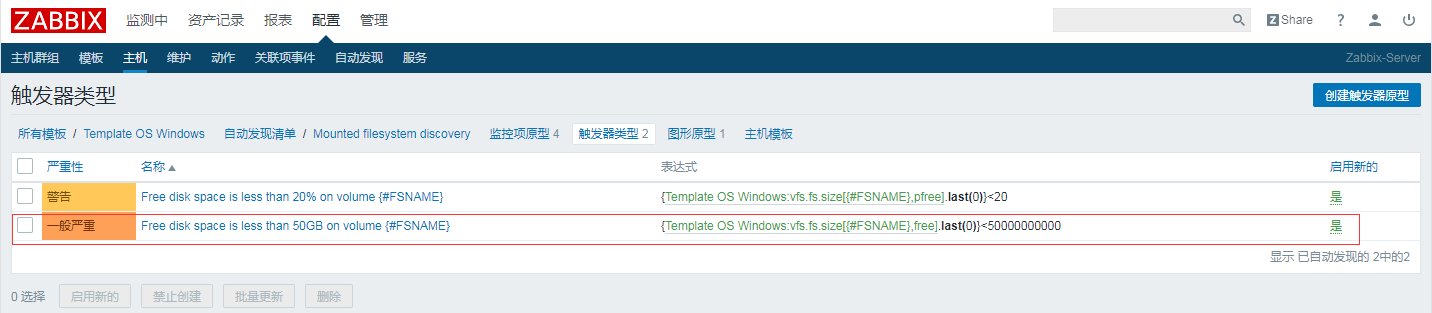
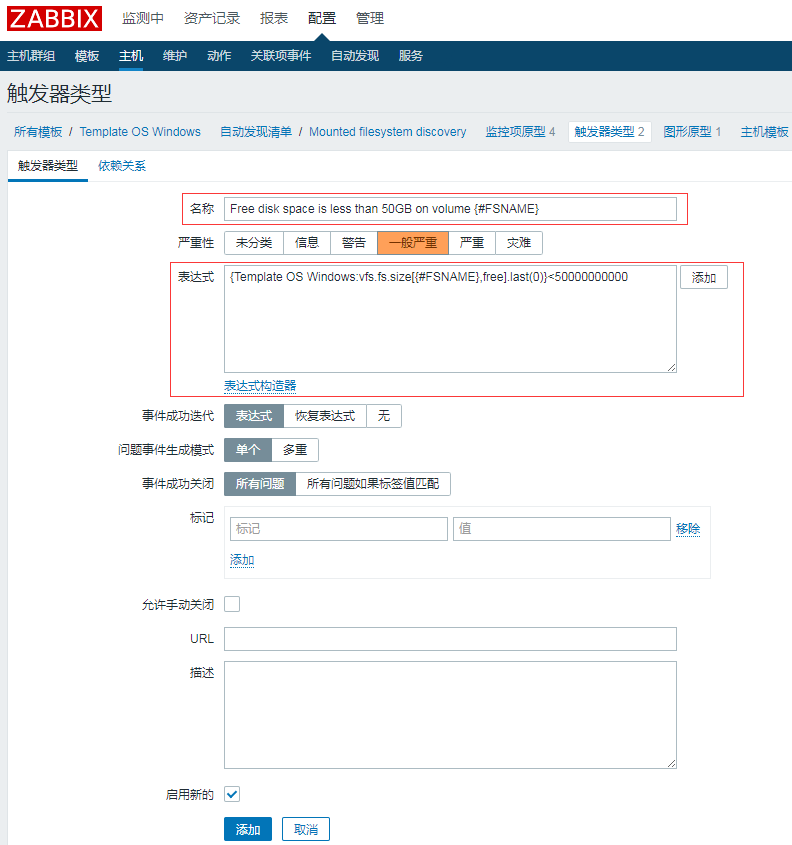
选择配置--->模板--->(Template OS Linux/Template OS Windows)--->Mounted filesystem discovery--->触发器类型
我这边是已经修改好的了,没有修改的或者没有这一触发项的,可以点击右上角(创建触发器原型)
名称:Free disk space is less than 50GB on volume {#FSNAME}
表达式:{Template OS Windows:vfs.fs.size[{#FSNAME},free].last(0)}<50000000000
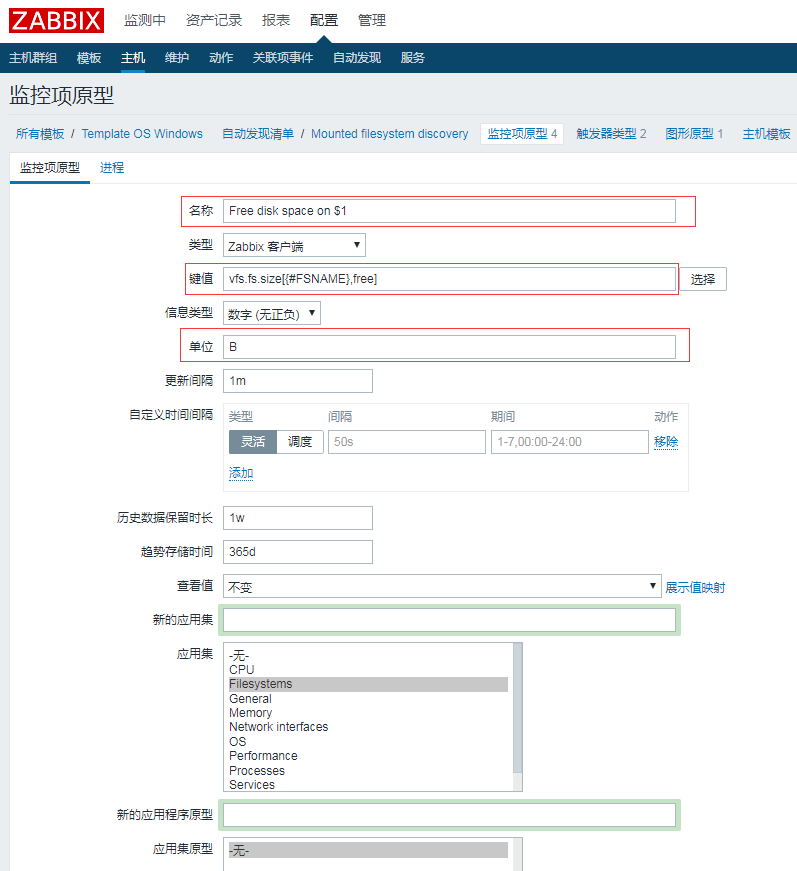
选择配置--->模板--->(Template OS Linux/Template OS Windows)--->Mounted filesystem discovery--->监控项类型
我这边是已经修改好的了,没有修改的或者没有这一监控项的,可以点击右上角(创建监控项原型)
名称:Free disk space on $1
表达式:vfs.fs.size[{#FSNAME},free]
单位:B
更新间隔:1m或者60s都可以
5、监控Windows-网卡自动发现规则
问题描述:这个一般是默认的windows模板里面包含自动发现服务器网卡的,但是会自动发现很多其他的网卡什么之类的图形东东
解决办法:你直接删除对应的图形是没用的,因为自动发现规则会再次自动发现,所以需要把规则改一下
1.自动发现规则里面---->Windows service discovery(这个可以禁用掉)
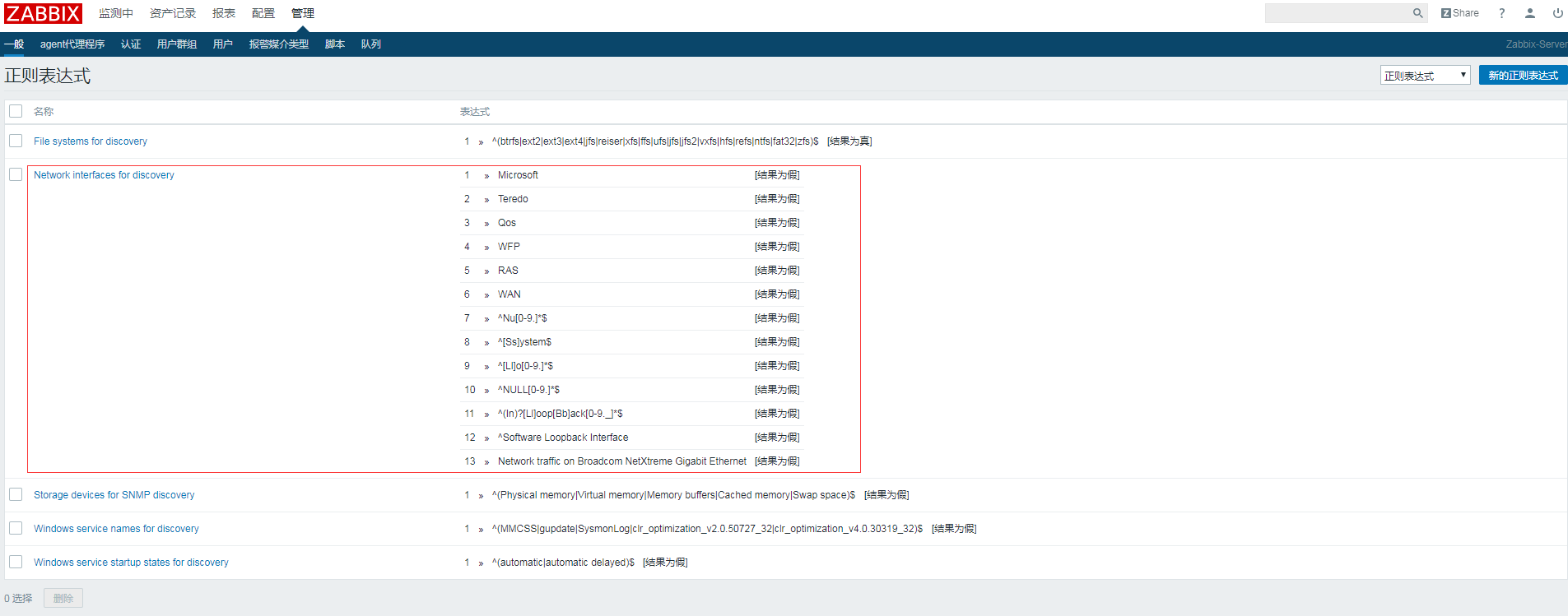
2.管理--->一般--->正则表达式--->Network interfaces for discovery(加入下图的参数,这样就设定不会自动发现以这些参数网卡了)
1 » Microsoft [结果为假] 2 » Teredo [结果为假] 3 » Qos [结果为假] 4 » WFP [结果为假] 5 » RAS [结果为假] 6 » WAN [结果为假] 7 » ^Nu[0-9.]*$ [结果为假] 8 » ^[Ss]ystem$ [结果为假] 9 » ^[Ll]o[0-9.]*$ [结果为假] 10 » ^NULL[0-9.]*$ [结果为假] 11 » ^(In)?[Ll]oop[Bb]ack[0-9._]*$ [结果为假] 12 » ^Software Loopback Interface [结果为假] 13 » Network traffic on Broadcom NetXtreme Gigabit Ethernet [结果为假]
6、配置服务端邮件报警功能
我这边用到的是腾讯企业邮箱
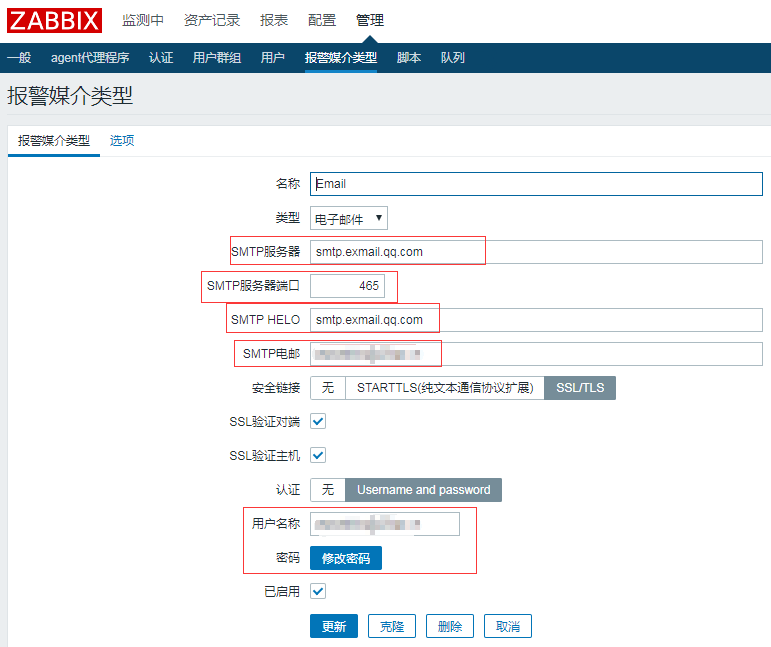
如下图所示,管理--->报警媒介类型--->Email
要注意的是用户名称这里要写你的企业邮箱账号,密码填写密码
一开始我以为是发邮件的名称,搞得没法发邮件,可以使用QQ邮箱
SMTP服务器:smtp.exmail.qq.com
端口:465
SMTP电邮:XXXX@qq.com
用户名称:XXXX@qq.com
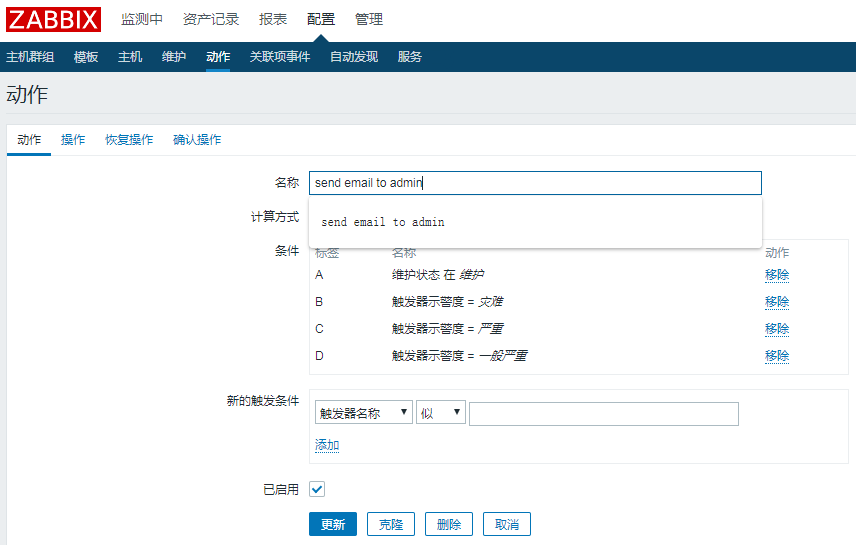
配置--->动作--->触发器
创建一个触发器来发邮件报警
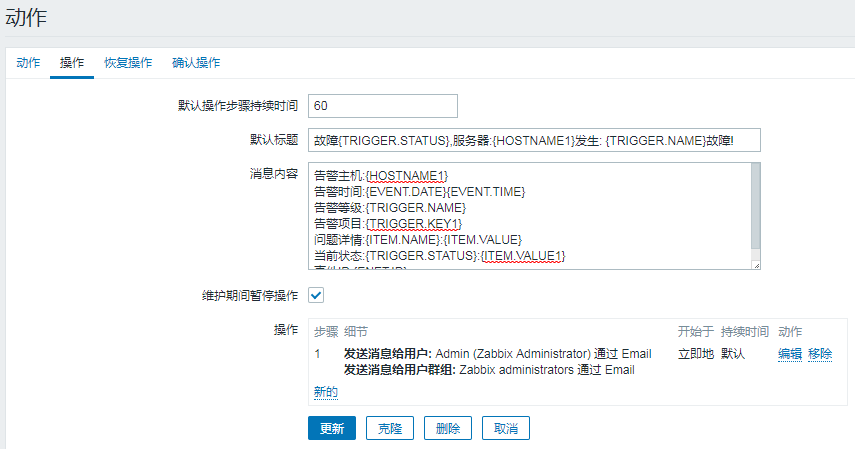
操作:
默认标题:故障{TRIGGER.STATUS},服务器:{HOSTNAME1}发生: {TRIGGER.NAME}故障!
消息内容:
告警主机:{HOSTNAME1}
告警时间:{EVENT.DATE}{EVENT.TIME}
告警等级:{TRIGGER.NAME}
告警项目:{TRIGGER.KEY1}
问题详情:{ITEM.NAME}:{ITEM.VALUE}
当前状态:{TRIGGER.STATUS}:{ITEM.VALUE1}
事件ID:{ENET.ID}
恢复操作:
默认标题:恢复{TRIGGER.STATUS}, 服务器:{HOSTNAME1}: {TRIGGER.NAME}已恢复!
消息内容:
告警主机:{HOSTNAME1}
告警时间:{EVENT.DATE}{EVENT.TIME}
告警等级:{TRIGGER.NAME}
告警项目:{TRIGGER.KEY1}
问题详情:{ITEM.NAME}:{ITEM.VALUE}
当前状态:{TRIGGER.STATUS}:{ITEM.VALUE1}
事件ID:{ENET.ID}
确认操作:
默认标题:已确认: {TRIGGER.NAME}
消息内容:
{USER.FULLNAME} 已经确认的问题 {ACK.DATE} {ACK.TIME} 以下消息:
{ACK.MESSAGE}
目前的问题状态是{EVENT.STATUS}
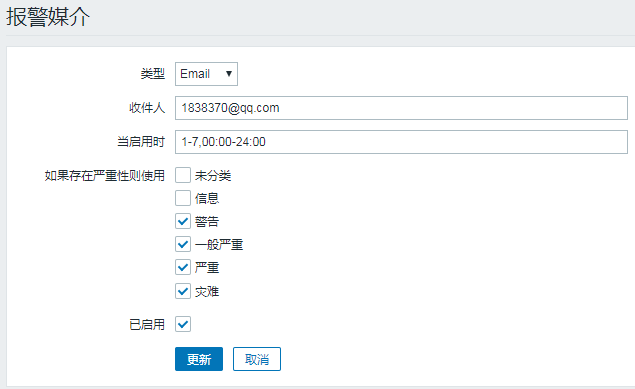
最后配置报警媒介,也就是触发报警条件,要下发邮件通知道哪个邮箱里面
点击那个小头像,然后进入到用户基本资料,选择报警媒介进行设置
可以自己选择严重性级别,设置完启用了以后,报警功能就设置完成了!


















 9059
9059

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









