





开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的 技术 」、「有亮点的 产品 」、「有思考的 文章 」、「有态度的 观点 」、「有看点的 活动 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@赵怡岭、@鲍勃
01有话题的技术
1、阿里巴巴达摩院提出 WorldVLA 模型,首次将世界模型与动作模型融合

阿里巴巴达摩院提出了 WorldVLA, 首次将世界模型 (World Model) 和动作模型 (Action Model/VLA Model) 融合到了一个模型中。WorldVLA 是一个统一了文本、图片、动作理解和生成的全自回归模型。
VLA 模型可以根据图像理解生成动作;世界模型可以根据当前图像和动作生成下一帧图像;WorldVLA 将将两者融合,实现图像与动作的双向理解和生成,如下图所示。
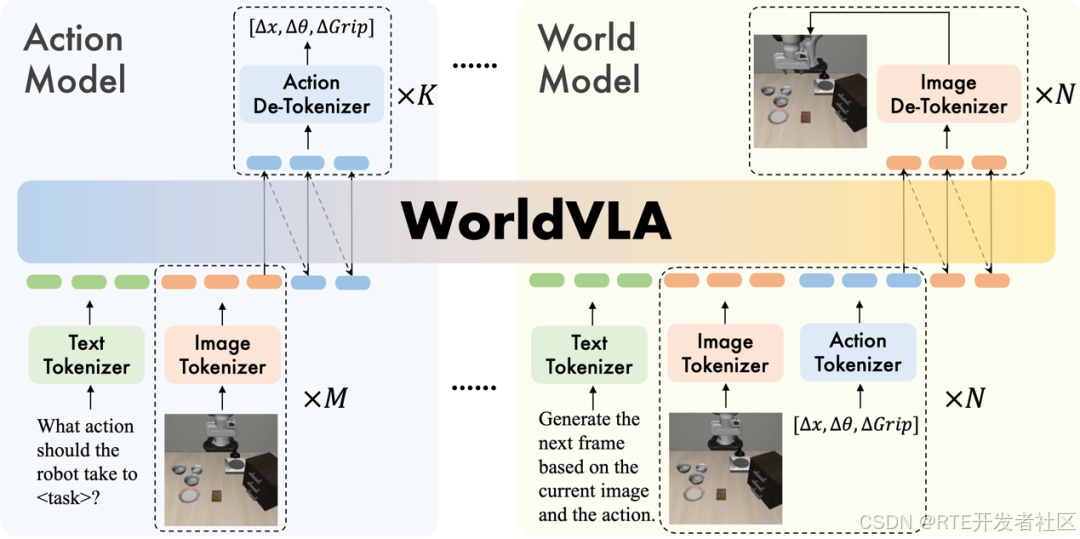
WorldVLA 使用独立的编码器分别处理图像、文本和动作,并让这些模态共享同一个词汇表,从而在单一的大语言模型架构下实现跨模态的统一建模。这种设计不仅提升了动作生成的准确性,也增强了图像预测的质量。WorldVLA 使用 Action Model 数据和 World Model 数据来训练模型。
论文标题:WorldVLA: Towards Autoregressive Action World Model
论文地址:https://arxiv.org/pdf/2506.21539
代码地址:https://github.com/alibaba-damo-academy/WorldVLA(@机器之心)
2、联发科推出开源 AI 语音识别模型 MR BreezeASR 25,针对中国台湾地区语言特点和口音优化
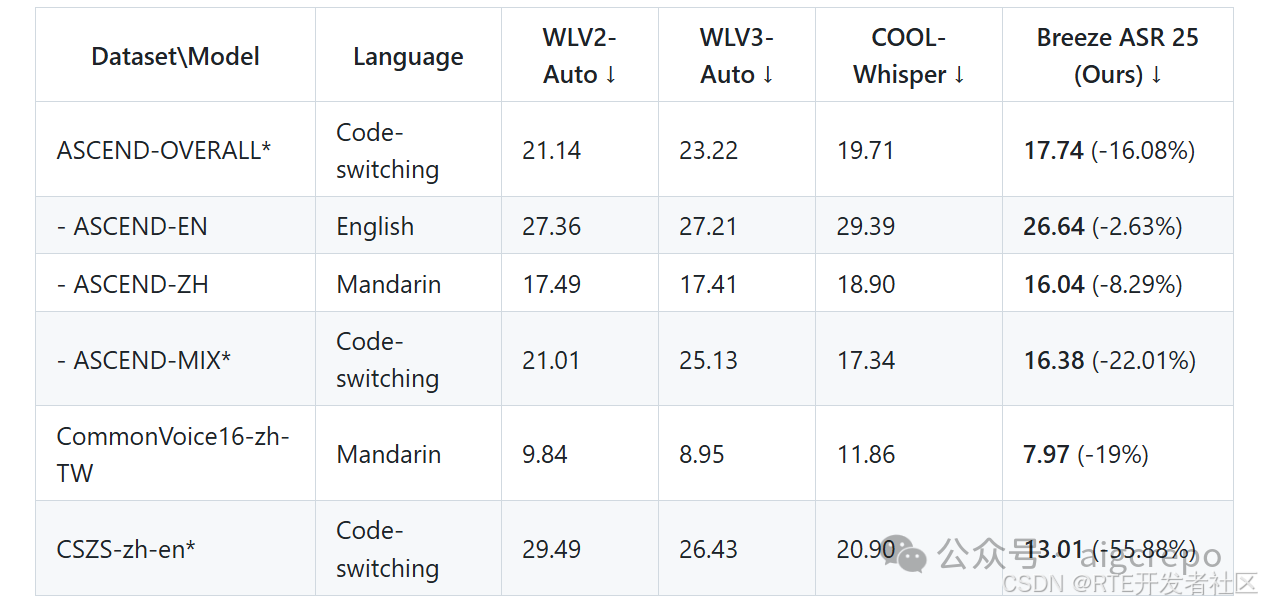
7 月 3 日消息,联发科本月 1 日宣布其辖下的前瞻技术研究单位联发创新基地 (MediaTek Research) 发布基于 OpenAI Whisper 优化的 AI 语音识别模型 MR Bre
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 639
639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









