





开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的 技术 」、「有亮点的 产品 」、「有思考的 文章 」、「有态度的 观点 」、「有看点的 活动 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@赵怡岭、@鲍勃
01有话题的技术
1、Manus 推出完全免费的 Chat 模式 无任何使用限制
Manus 宣布推出全新免费聊天模式,用户可通过简洁界面实现日常咨询、知识查询等即时问答。此次更新同步支持无缝切换至代理模式,无需付费即可执行网页设计、数据分析、股票策略生成等复杂任务,显著降低使用门槛。作为全球首款通用型 AI 智能体,Manus 采用多代理架构,能在独立虚拟机中完成从需求解析到成果交付的全链路任务,覆盖金融分析、旅行规划等数十个场景。此前代理模式需订阅或消耗点数。(@AI 智前沿、@三花 AI)
2、StepFun 开源 130B 端到端语音大模型 Step-Audio-AQAA,基于其自研的 Step-Omni 多模态大模型开发,支持包括四川话、粤语等多种语言
StepFun 开源了其最新的大型音频语言模型 Step-Audio-AQAA,并已在 Hugging Face 上线。该模型拥有 1300 亿参数,基于其自研的 Step-Omni 多模态大模型开发。
Step-Audio-AQAA 是一个完全端到端的模型,专注于音频问答(Audio Query-Audio Answer, AQAA)任务。它能够直接处理原始音频输入并生成自然的语音回答,无需依赖传统的 ASR(自动语音识别)和 TTS(文本转语音)模块,从而简化了系统架构并避免了级联错误。该模型支持多种语言,包括中文(含四川话、粤语)、英语、日语等,并能进行精细的语音特征控制。
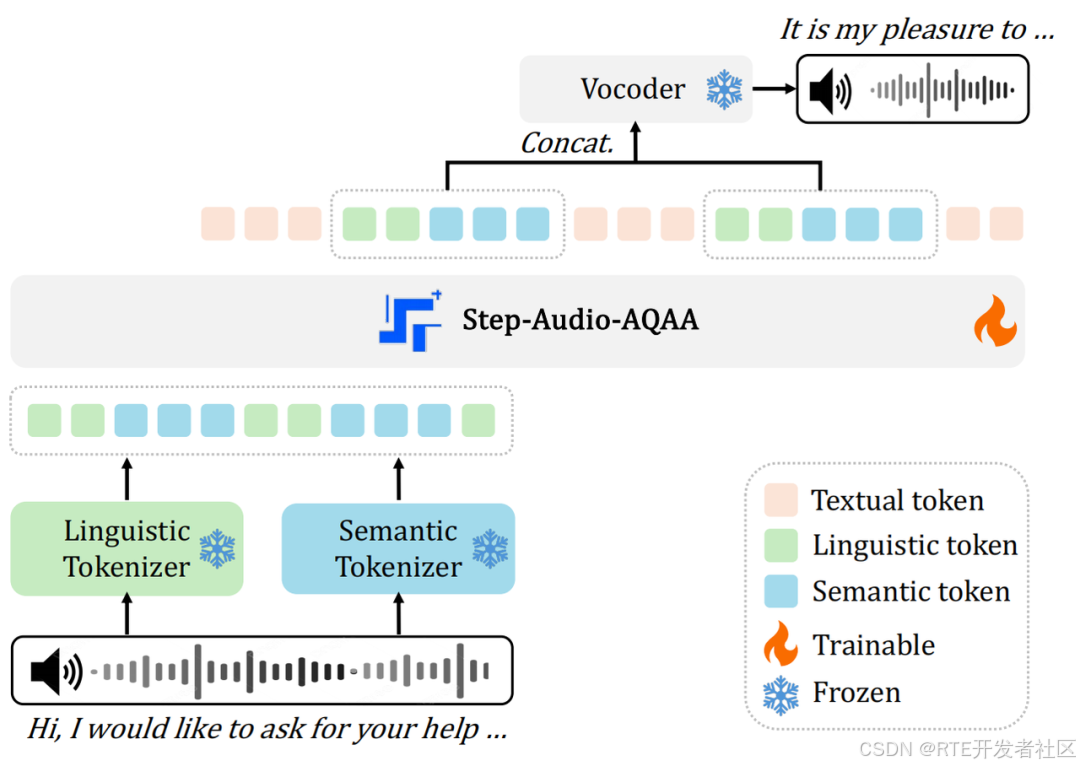
Step-Audio-AQAA 由双码本音频分词器、骨干 LLM 和神经声码器三个核心模块组成。
流程为:双码本音频分词器将输入音频转换为语言和语义令牌序列;骨干 LLM(经 SFT、DPO 和模型融合后训练)生成文本和音频令牌交错的输出序列;最后,声码器从音频令牌重建高保真语音波形作为响应。
HuggingFace 链接:
https://huggingface.co/stepfun-ai/Step-Audio-AQAA
StepEval-Audio-360 数据集:
https://huggingface.co/datasets/stepfun-ai/StepEval-Audio-360
论文链接:
https://arxiv.org/abs/2506.08967
相关链接:
https://www.stepfun.com/docs/zh/step-audio-aqaa?studio_code=step-audio-aqaa&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 406
406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









