



前言
今天下午突然 出现 测试环境 cpu飙高,干到了 60%,其他项目 响应时间明显变长。。。有点吓人,不想背锅。
项目背景
出问题的项目是 需要连接各个不同nacos 和不同的 namespace 进行对应操作的 一个项目,对nacos的操作都是httpClient 调用的api接口,httpClient方法 没有问题,不用质疑这个。
定位问题
首先 这 cpu高了,直接top -Hp 看看
定位到 进程id,然后 执行 jstack 进程id -> 1.txt
看到堆栈信息 ,下面提示信息有很多
"com.alibaba.nacos.client.config.security.updater" #2269 daemon prio=5 os_prio=0 tid=0x00007fa3ec401800 nid=0x8d85 waiting on condition [0x00007fa314396000]
java.lang.Thread.State: TIMED_WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000000f7f3eae0> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2078)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:1093)
at java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:809)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)但是上面这个提示信息 显示 是 线程内部的,而且是nacos client 内部的

你这么搞,让我很难受啊,我都是http 调用的,当时就是为了 防止开启无用的线程,这。。。。。怎么
那我去 根据你的关键字找找 是哪里打印的,关键字com.alibaba.nacos.client.config.security.updater ServerHttpAgent 类的方法。
// init executorService
this.executorService = new ScheduledThreadPoolExecutor(1, new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r);
t.setName("com.alibaba.nacos.client.config.security.updater");
t.setDaemon(true);
return t;
}
});这是构造方法啊,应该只初始化一次的啊,往上debug,我靠,NacosConfigService 类中调用了,debug 看什么时候调用了 不就行了嘛
项目初始化的时候 调用了一次,业务系统依赖nacos嘛,ok 可以理解。再就是漫长的等待,30s后 发现又是一次调用,我去,怎么可能。。。
往回debug,代码如下
scheduler.schedule("定时校对灰度nacos 配置", () -> loadGrayConfig(grayFileName),
1800, 1800, TimeUnit.SECONDS);/**
* 灰度配置更新 解决 网络隔离的问题
*
* @param grayFileName 灰度文件的名称
*/
private void loadGrayConfig(String grayFileName) {
synchronized (this) {
System.err.println("loadGrayConfig datetime: " + DateUtils.formatDate(new Date()));
//刷一次 缓存 重新获取nacos 内容 赋值
grayConfigManager.loadNoCache(grayFileName);
}
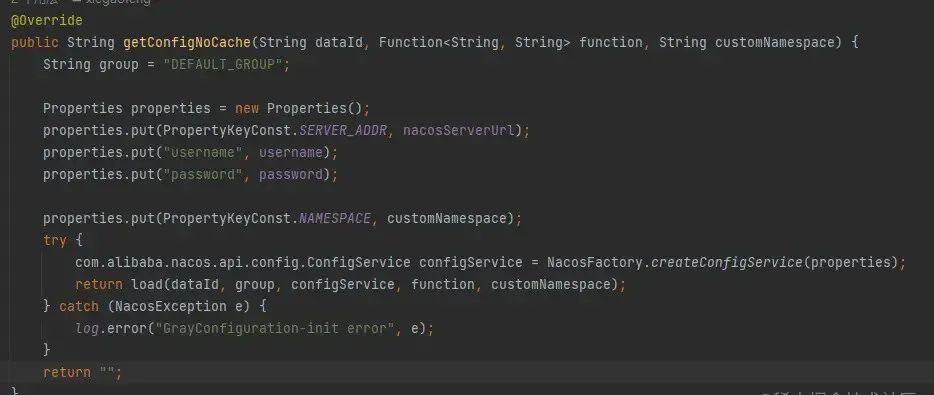
}
等会,难道 小丑是我。。。。

这当时是为了灰度功能,定时数据校验用的 用了一个线程池,当时以为用了线程池 妥妥的。。。还特意调用的 Nocache 方法,让他创建新的nacos Config对象,做数据校对。
但是每调用一次 NacosFactory.createConfigService(properties) ,nacos config 构造器就会开一个线程,就导致了这个问题。
什么是网络隔离
这里可能你要问了 你说 为了防止网络隔离 才加的这个调度任务,什么是网络隔离啊?

我刚开始听说这个概念是 当时学习 Raft 假设一个Raft集群拥有三个节点,其中节点3的网络被隔离,那么按照BasicRaft的实现,集群会有以下动作:
节点3由于网络被隔离,收不到来自Leader的Heartbeat和AppendEntries,所以节点3会进入选举过程,当然选举过程也是收不到投票的,所以节点3会反复超时选举;节点3的Term就会一直增大
节点1与节点2会正常工作,并停留在当时的Term
网络恢复之后,Leader给节点3发送RPC的时候,节点3会拒绝这些RPC理由是发送方任期太小。关于springcloud更多面试场景问题:https://www.yoodb.com/
Leader收到节点3发送的拒绝后,会增大自己的Term,然后变成Follower。随后,集群开始新的选举,大概率原本的Leader会成为新一轮的Leader。
那么网络隔离Raft是怎么解决的呢?
多轮投票的安全问题是棘手的,必须避免同一高度不同轮数分别提交两个不同区块的情形。在Tendermint中,这个问题可以通过锁机制(locking mechanism)得到解决。
锁定规则:预投票锁(Prevote-the-Lock):
验证者只能预投票(pre-vote) 他们被锁定的区块。这样就阻止验证者在上一轮中预提交(pre-commit)一个区块,之后又预投票了下一轮的另一个区块。
波尔卡解锁(Unlock-on-Polka):验证者只有在看到更高一轮(相对于其当前被锁定区块的轮数)的波尔卡之后才能释放该锁。这样就允许验证者解锁,如果他们预提交了某个区块,但是这个区块网络的剩余节点不想提交,这样就保护了整个网络的运转,并且这样做并没有损害网络安全性。
解决方案是把term替换成(term, nodeid),并且按照字典序比较大小(a > b === a.term > b.term || a.term == b.term && a.nodeid > b. node_id). 这是paxos里的做法, 保证不会出现raft里的冲突。
原理是, raft对voting的阶段有2个值来描述: term和当前投了哪个node_id, 即[term, nodeid], 由于raft不允许一个term vote2个不同的不同的node, 也就是说, vote_req.term > local.term && vote_req.nodeid == local.nodeid 才会grant这个vote请求。
把term替换成(term,nodeid)后, vote阶段的大小比较变成了: vote_req.term > local.term || vote_req.term == local.term && vote_req.nodeid >= local.nodeid, 条件边宽松了. 同一个term内, 较大nodeid的可以抢走较小nodeid 已经建立的leader。
而日志中原本记录的term也需要将其替换成(term, node_id), 因为这两项加起来才能唯一确定一个leader. 之前raft里只需一个term就可以唯一确定一个leader。
vote中比较最大log id相应的,从比较tuple (term, index) 改成比较tuple (term, node_id, index)。就这么点修改。
总结下来就是 按照字典排序 和 预投票锁 保证 当多个 term 相同的 candidate 相遇后,肯定会有一个 获得多数派投票。另外,推荐公众号Java精选,回复java面试,获取面试资料,支持在线刷题。
想法
我们如果出现 异常的网络隔离情况再回来,可能导致 数据的不一致,但是上面的 解决办法 因为 比较重,不适合我们,我们就单纯 引入 定时校对的调度任务 进行比较(和 对账一样)。
修复
我对nacos config 连接进行 遍历查找 是否存活,不存活 我就shutdown,然后生成一个新的,而不是这种全部生成一边,毕竟人家 构造器开了线程。。。。说回来还是因为 我当时自信了,没往这个调用下面看,在子类中 写的开线程 哈哈,行吧,改改 ,跑到测试环境 看看效果(CPU)

嗯嗯 稳定了,明天再看看,应该没问题了。
作者:雨夜之寂
https://juejin.cn/post/7166075966615126029
公众号“Java精选”所发表内容注明来源的,版权归原出处所有(无法查证版权的或者未注明出处的均来自网络,系转载,转载的目的在于传递更多信息,版权属于原作者。如有侵权,请联系,笔者会第一时间删除处理!
最近有很多人问,有没有读者交流群!加入方式很简单,公众号Java精选,回复“加群”,即可入群!
Java精选面试题(微信小程序):3000+道面试题,包含Java基础、并发、JVM、线程、MQ系列、Redis、Spring系列、Elasticsearch、Docker、K8s、Flink、Spark、架构设计等,在线随时刷题!
------ 特别推荐 ------
特别推荐:专注分享最前沿的技术与资讯,为弯道超车做好准备及各种开源项目与高效率软件的公众号,「大咖笔记」,专注挖掘好东西,非常值得大家关注。点击下方公众号卡片关注。
点击“阅读原文”,了解更多精彩内容!文章有帮助的话,点在看,转发吧!
















 6800
6800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









