




 本文介绍如何在Spark中集成SparkSQL,并使用SQL语句进行WordCount操作。通过配置pom.xml引入Spark核心、SparkSQL及Spark Streaming依赖,创建SparkSession并使用foreachRDD方法将RDD转换为DataFrame,创建临时视图后执行SQL查询实现WordCount。
本文介绍如何在Spark中集成SparkSQL,并使用SQL语句进行WordCount操作。通过配置pom.xml引入Spark核心、SparkSQL及Spark Streaming依赖,创建SparkSession并使用foreachRDD方法将RDD转换为DataFrame,创建临时视图后执行SQL查询实现WordCount。
1.需求:
集成Spark SQL,使用SQL语句进行WordCount
2.代码:
(1)pom.xml
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.0</version>
</dependency>
</dependencies>
(2)MyNetwordWordCountWithSQL.scala
import org.apache.log4j.Logger
import org.apache.log4j.Level
import org.apache.spark.SparkConf
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
import org.apache.spark.storage.StorageLevel
import org.apache.spark.sql.SparkSession
object MyNetwordWordCountWithSQL {
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir", "/Users/macbook/Documents/hadoop/hadoop-2.8.4")
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
val conf = new SparkConf().setMaster("local[2]").setAppName("MyNetwordWordCountWithSQL")
val ssc = new StreamingContext(conf,Seconds(5))
val lines = ssc.socketTextStream("192.168.1.121",1235,StorageLevel.MEMORY_ONLY)
val words = lines.flatMap(_.split(" "))
//集成Spark SQL 使用SQL语句进行WordCount
words.foreachRDD( rdd => {
val spark = SparkSession.builder().config(rdd.sparkContext.getConf).getOrCreate()
import spark.implicits._
val df1 = rdd.toDF("word")
df1.createOrReplaceTempView("words")
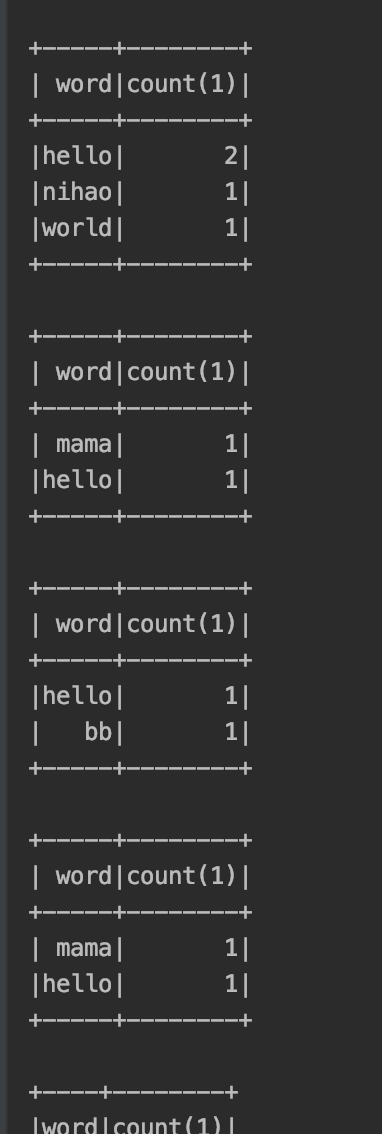
spark.sql("select word , count(1) from words group by word").show()
})
ssc.start()
ssc.awaitTermination()
}
}
3.运行:
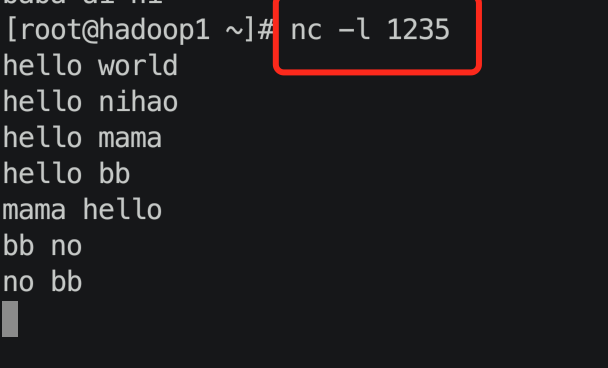
4.结果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









