




 本文深入探讨Scala编程语言的关键特性,包括类与对象、构造器、内部类、伴生对象、trait、继承、包与导入机制。详细解析了Scala如何处理类字段、方法、构造过程、类型检查与转换、模式匹配等核心概念。
本文深入探讨Scala编程语言的关键特性,包括类与对象、构造器、内部类、伴生对象、trait、继承、包与导入机制。详细解析了Scala如何处理类字段、方法、构造过程、类型检查与转换、模式匹配等核心概念。
Classes
- 一个源文件可包含多个类,每个类默认都是 public
- 类字段必须初始化,编译后默认是 private,自动生成 public 的 getter/setter ;Person 示例
private字段,生成 private 的 getter/setterval字段,只生成 getterprivate[this]字段,不生成 getter/setter- 自定义 getter/setter,foo 和 foo_=
- 类方法默认都是 public
- 方法调用规约:访问器调用可省略括号,修改器调用加上括号
- 为字段加上
@bean.BeanProperty注解可生成符合 JavaBean 规范的 get/set 方法(加上默认的两个方法,共四个方法) - 构造器:1 个主构造器,任意个辅构造器
- 全部都叫
this,只是参数不同 - 辅构造器必须调用主构造器或之前定义的辅构造器
- 主构造器与类定义密不可分,参数直接定义在类名后
- 主构造器会立即执行类定义中的所有语句
- 主构造器中的参数被方法使用到,则对应的参数等价于
private[this] val字段
- 全部都叫
- 内部类
- 路径依赖,不同于 Java 内部类,同一类 A 的不同实例(a1, a2)构建的内部类 Inner,其类型是不同的,a1.Inner != a2.Inner
- 解决路径依赖
- 类型投射,Outer#Inner
- 将内部类放到伴生对象 object 中
self =>自身类型,区分调用的内部类和外部类的字段、方法等
Objects
- 用于单例及工具类方法
- object 构造器只在第一次被调用时执行
- 可继承一个
class或多个trait- 可用于全局默认对象
- 不可提供构造器参数
- 伴生对象
- 与类名称一致
- 类与伴生对象可互相访问私有资源,但区分作用域,如
Accounts.newUniqueNumber()而不是newUniqueNumber() - 类与伴生对象必须在同一个源文件中
- 伴生对象中的
apply方法- 调用方式
Object(arg1, ..., argN), 返回伴生类的实例,如Array(1,2,3) - 省略
new关键字,在嵌套表达式中很方便
- 调用方式
- 应用对象
extends App- 不需要 main 方法直接执行构造器内的代码
- scala 默认无枚举类型
- 使用
Enumeration帮助类实现 - 枚举类型为
Enumeration.Value(ID, name)内部类, ID 依次累加, 默认 0 开始;name 默认是字段名
- 使用
Traits
- 替代 Java 中的接口
- 可以有抽象的和具体的方法
- 在
trait中未实现的方法默认是抽象的 (abstract)
- 在
- 类可以实现多个
trait,从最后一个开始调用- 使用
extends关键字实现 - 覆盖抽象方法时不需要
override关键字 - 有多个
trait则对其他的trait使用with关键字
- 使用
- 所有的 Java 接口都可以被当做
trait使用 - 对象也可以添加多个
trait,从最后一个开始调用 - 多个
trait的情况下,super.someMethod会根据从右向左的顺序调用下一个trait的方法- 具体调用依赖于使用时的顺序,相比传统的继承更灵活
- 在多个 mix-in 的情况下,如果父
trait存在抽象方法,则子trait需使用abstract override关键字,否则super.someMethod无法编译
- 有初始值的字段/具体字段,都会被添加到子类中
- 无初始值的字段/抽象字段,在非抽象子类中,需要进行初始化
trait也有构造器- 不可以有构造参数,且只有一个构造器
- 由定义体中的初始化字段和其他语句构成
- 构造顺序:父类 > 各
trait从左向右,有父trait的先构造,共享的父trait只构造一次 > 子类 - 考虑到构造顺序,如果子类中使用抽象字段,则可使用提前定义(early definition,会在构造器之前执行)的语法讲改字段初始化
- 提前定义语句块中只能使用字段定义语句,不可使用其他语句
trait可继承类,混入该trait的类都是被继承类的子类,子类如果有继承其他的类也必须是被继承类的子类- 与自身类型(self type)比较
trait不继承类,直接在 body 内定义this: Type =>,则混入的类必须是该 Type 类型的/子类型的- 也可使用结构类型(structural type),
this: { def log(msg: String) } =>,则混入的类必须包含结构类型中定义的方法
trait最终会翻译成类和接口
Packages and Imports
package包名和文件路径并不一定对应java.lang,scala,Predef始终默认会导入- 与 Java 不同,包路径并不是绝对的,如
collection.mutable实际是scala.collection.mutable package a.b.c与package a { package b { package c {}}}不同package a或package b中定义的资源可在带括号的包声明中访问,但package a.b.c无法访问
- 包对象
- package 由于 JVM 的限制不能直接声明函数或变量
- 不同于 package, package object 可定义工具函数或常量
- 可见性控制,通过
private[package.name]限制资源的可见性 import- 导入包后可使用相对路径访问类等,如
collection.mutable - 导入所有资源
import collection.mutable._ - 可在任意位置进行导入操作
selector- 选择性的导入一部分成员,
import java.awt.{Color, Font} - 为导入成员取别名:
import java.util.{HashMap => JavaMap} - 隐藏成员:
import java.util.{HashMap => _, _}// 避免产生混淆
- 选择性的导入一部分成员,
- 隐式导入,默认导入三个
java.lang,scala和Predef- 后面导入的可将前面的成员覆盖,避免冲突
- 导入 scala 相关的包可省略
scala路径
- 导入包后可使用相对路径访问类等,如
Inheritance
fragile base class基类被继承之后,修改基类可能会对子类造成无法预期的影响
-
继承类,与 Java 一样使用
extends关键字final类不能被继承,final字段、方法不能被覆盖
-
覆盖非抽象方法,必须使用
override关键字 -
抽象方法
- 无方法体的方法,可以省略
abstract关键字;子类覆盖时也可以省略override
- 无方法体的方法,可以省略
-
抽象字段
- 无初始值的字段,可省略
abstract关键字,子类覆盖式也可省略override
- 无初始值的字段,可省略
-
调用父类方法,使用
super关键字 -
类型检查和转换,
isInstanceOf,asInstanceOf;获取类型,classOf- 模式匹配通常是个更好的类型检查方式
-
protected不同于 Java,受保护成员在包内不可见 -
辅助构造器不可直接调用超类构造器
- 可在定义类时直接在 extends 时调用超类构造器并传递参数
- 继承 Java 类时主构造器必须调用超类的构造器
-
覆盖字段
def只能覆盖defval只能覆盖 无参数的defvar只能覆盖 抽象的var
-
继承层级
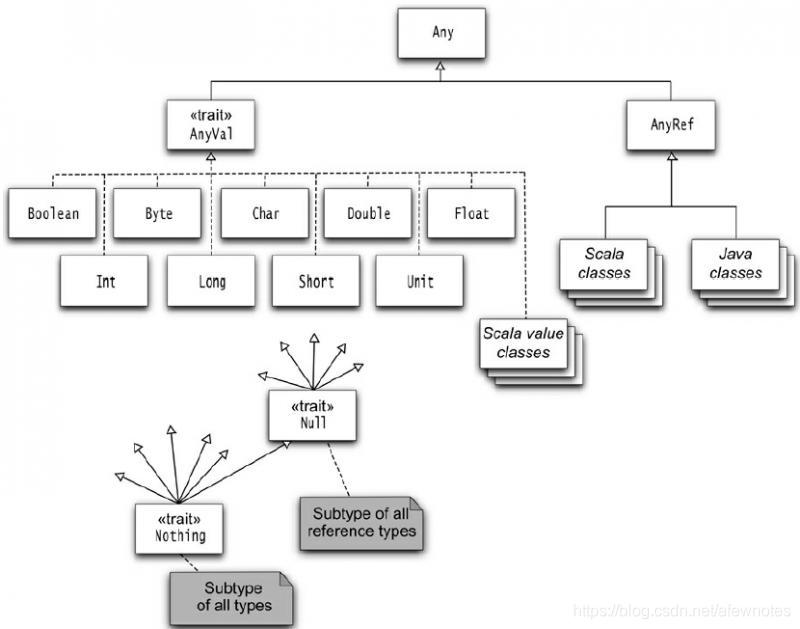
Any定义了asInstanceOf,isInstanceOf,判断相等,hash值等方法AnyRef是除基础类型外所有类的父类,等价于java.lang.Object- 提供方法
wait,notify/notifyAll,synchronized
- 提供方法
AnyVal不包含任何方法,只是个值类型的标记- 所有 Scala 类都实现了
ScalaObject这个标记接口,该接口无任何方法 Null的唯一实例null,可分配给引用类型,但不可分配给值类型(Int不可为null)Nothing无实例,在泛型构造时有用,Nil类型为List[Nothing]???方法声明返回类型为Nothing, 无返回值,会抛出NotImplementedError,用于预留未实现的方法Unit代表空/void,类型唯一值为()- 如果方法参数类型为
Any或AnyRef, 当传递多个参数时,会被替换为tuple
-
equals和hashCode判断对象相等- 可使用模式匹配实现
equals equals参数类型为Any而不是具体的类型##是hashCode的安全版本,遇到null会返回 0 而不是抛出异常
- 可使用模式匹配实现
-
值类 Value Class
- 继承
AnyVal - 主构造器只有一个参数 val,无构造体
- 无其他构造器和字段
- 自动提供的
equals和hashCode比较实际值 - 用于隐式转换
- 其他用途,如
class a(x: Int, y: Int)设计为class a(x: X, y: Y),定义值类X,Y避免混淆参数
- 其他用途,如
- 继承

















 5273
5273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









