



 本文讲述了作者在2024年第一季度专注于改进现有产品,尤其是升级软件和优化用户体验的过程中,遇到并解决一个关于GDK3闪存算法程序的BUG,通过实例揭示了“调试第一心法”,强调了从近距离出发解决问题的重要性。
本文讲述了作者在2024年第一季度专注于改进现有产品,尤其是升级软件和优化用户体验的过程中,遇到并解决一个关于GDK3闪存算法程序的BUG,通过实例揭示了“调试第一心法”,强调了从近距离出发解决问题的重要性。
2024年的第一个季度就要过去了,回顾过去的近3个月,我没有一天出差,也没有一天请假,每个工作日都在格蠹的办公室。
而且在过去的这些天里,格蠹没有做任何新的产品,所有精力都放在改进现有产品上,主要是升级软件和改进用户体验,包括找BUG和解BUG。
在解掉的众多BUG中,没有任何两个是一样的。所以我相信,要训练AI来解BUG的话,最大的问题将是训练样本不足。
但是在解BUG的思想方法方面,我的确找到了一个很有效的规律,我把它称为“调试第一心法”。
为了避免空洞说教,还是举个真实例子吧。
3月9日,一位GDK3的用户报告问题,使用NanoCode给GDK3刷固件时没有成功。
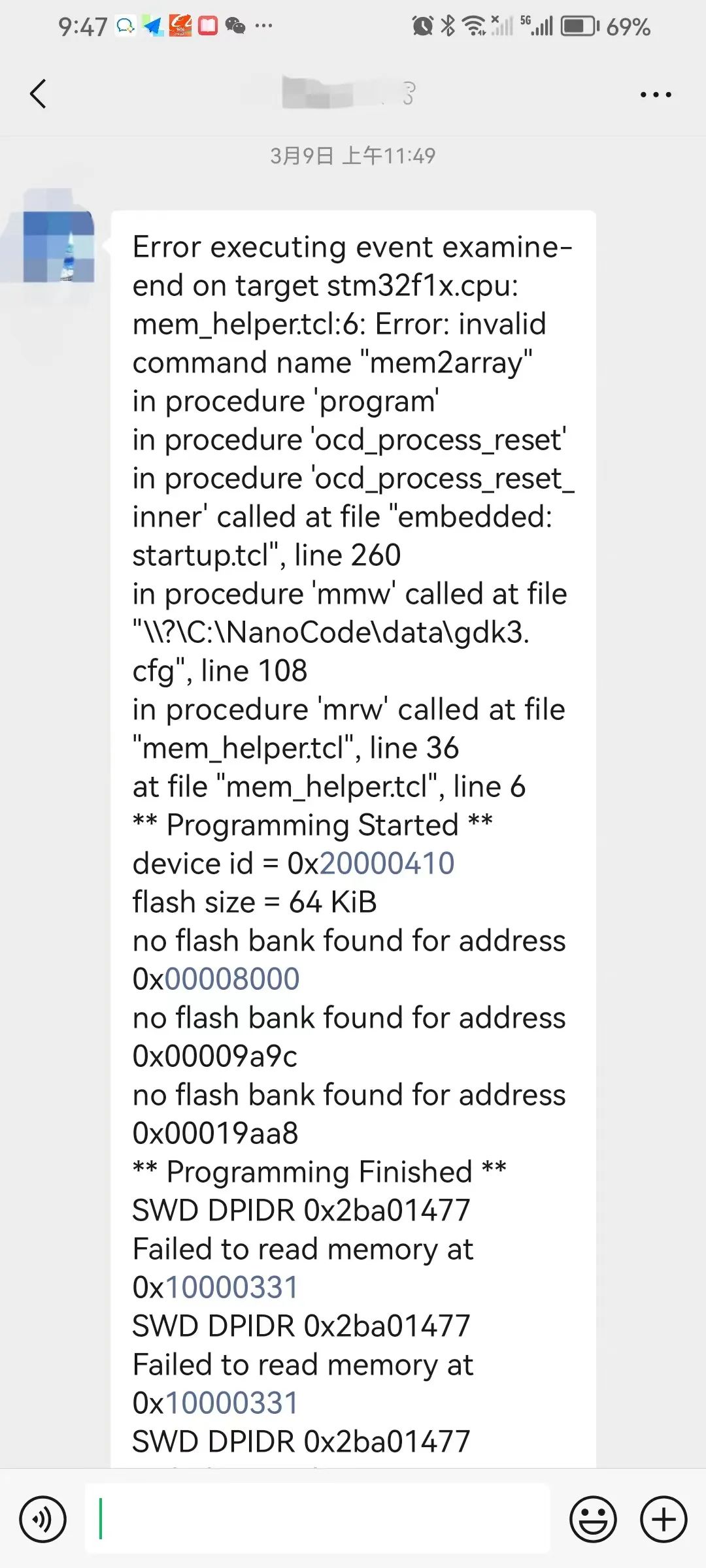
看了这个信息,我意识到这个问题可能是因为升级了最新的OpenOCD代码而引入的。
去年下半年,为了支持调试幽兰代码本,NanoCode的OCD库从原来的0.11版本升级到最新的0.12版本。这次升级,把访问ARM硬件的NTP模块(ntp.dll)改动较大。
我让格蠹的小伙伴使用老的ntp.dll,果然可以刷成功了。
接下来的问题就是比较新老代码,看新代码哪里有问题。这个问题的复杂度与代码量直接相关,如果只有一点点代码,那么很容易找到差异。但实际上,这个模块的代码量很大,而且新老代码的差异本来就很多。
在做了一些简单的改进后,问题稳定在如下错误:
corrupted fifo read pointer 0x20000044
看这个错误信息,有几个地方挺吓人的:
- fifo是一种数据结构,所谓的先进先出队列。
- pointer是指针,C语言里最著名的特征,高效直接,用好了很有杀伤力,用坏了也很有杀伤力。我在给小朋友们讲的编程课里,用“到你家找你”来做比喻。

- corrupted 啥意思?腐败。
fifo要求很精准和有序,指针很锐利,指错地方就像失控的铲车,铲到哪里算哪里。现在说是corrupted了,真是吓人。
根据这个错误信息搜索代码,精准定位到一个函数,很长的函数,名字和函数原型也都很长:
int target_run_flash_async_algorithm(struct target *target,
const uint8_t *buffer, uint32_t count, int block_size,
int num_mem_params, struct mem_param *mem_params,
int num_reg_params, struct reg_param *reg_params,
uint32_t buffer_start, uint32_t buffer_size,
uint32_t entry_point, uint32_t exit_point, void *arch_info)分段解释一下函数名target_run_flash_async_algorithm吧:
- target是这个模块的名字,用于访问调试目标,所在的源代码叫target.c,有7000多行,文件里的大多数函数都是以target开始。
- run表示运行,这个函数内部会调用另一个叫target_start_algorithm的函数来启动一个小程序,称为“闪存算法”。下文会解释一下。
- flash即闪存的意思。
- async代表异步,也就是以异步方式启动闪存算法程序,启动之后不阻塞调用线程。
- algorithm的本意是算法,在这里代表即将运行在GDK3上的一小段代码。
接下来解释一下所谓的“闪存算法程序”,这就不得不说一下ARM上烧写固件的著名套路了。
下图左侧是主机端,运行着NanoCode软件,右侧是基于ARM M核的GDK3小系统。
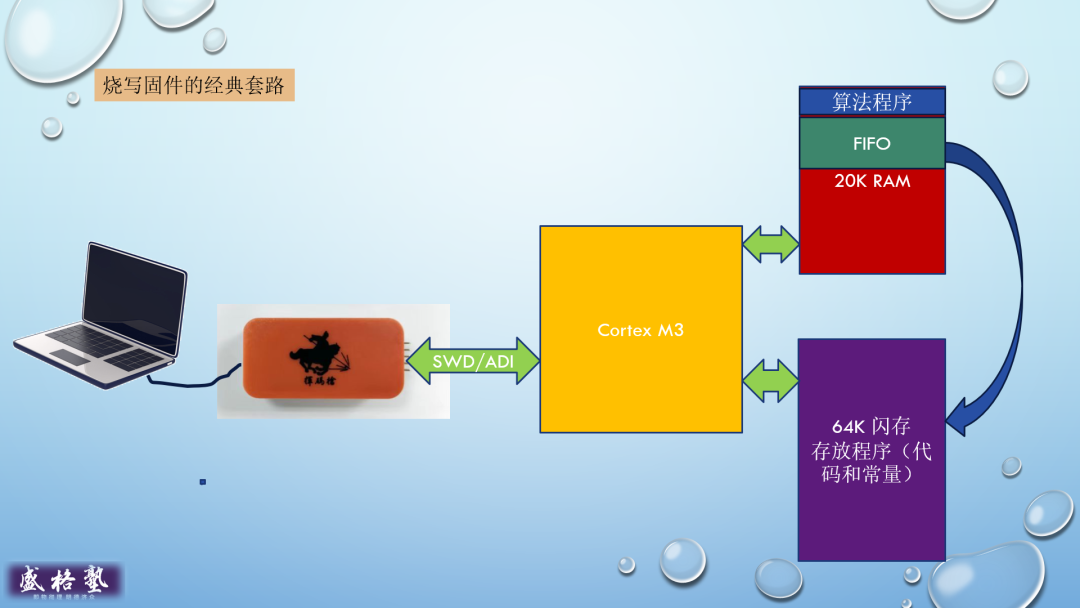
当在NanoCode里发出!program gem3.hex这样的命令后,NanoCode中的NDB(Nano Debugger)会通过挥码枪把一段事先准备好的程序写到GDK3的内存里,这段程序就是所谓的“闪存算法程序”。
闪存算法程序很短,一般只有几十条指令,下面的数组便是程序的机器码。
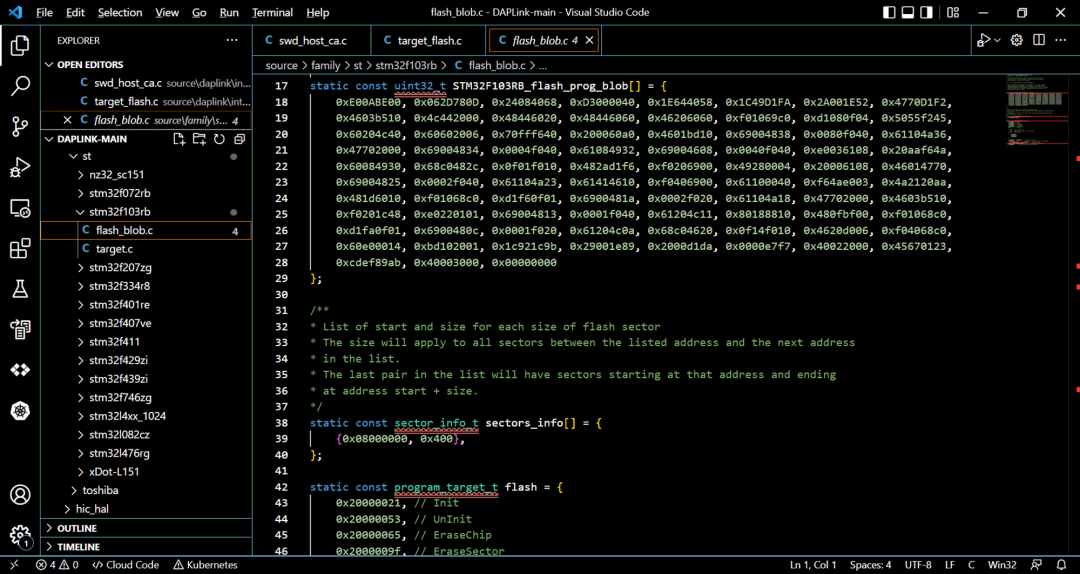
下面是使用NDB反汇编出来的算法程序。
u 20000000
20000000 6816 ldr r6, [r2]
20000002 2e00 cmp r6, #0
20000004 d018 beq #0x20000038
20000006 6855 ldr r5, [r2, #4]
20000008 42b5 cmp r5, r6
2000000a d0f9 beq #0x20000000
2000000c 882e ldrh r6, [r5]
2000000e 8026 strh r6, [r4]
20000012 3402 adds r4, #2
20000014 68c6 ldr r6, [r0, #0xc]
20000016 2701 movs r7, #1
20000018 423e tst r6, r7
2000001a d1fb bne #0x20000014
2000001c 2714 movs r7, #0x14
2000001e 423e tst r6, r7
20000020 d108 bne #0x20000034
20000022 429d cmp r5, r3
20000024 d301 blo #0x2000002a
20000026 4615 mov r5, r2
20000028 3508 adds r5, #8
2000002a 6055 str r5, [r2, #4]
2000002c 3901 subs r1, #1
2000002e 2900 cmp r1, #0
20000030 d002 beq #0x20000038
20000032 e7e5 b #0x20000000
20000034 2000 movs r0, #0
20000036 6050 str r0, [r2, #4]
20000038 4630 mov r0, r6
2000003a be00 bkpt #0
2000003c 0044 lsls r4, r0, #1
2000003e 2000 movs r0, #0
20000040 0044 lsls r4, r0, #1注意上面指令的末尾有一条端点指令:
2000003a be00 bkpt #0
这是用来重新中断到调试器的。
设计这个套路的ARM架构师一定是个调试高手。不然怎么会想出这么巧妙而且离不开调试器的方法呢?
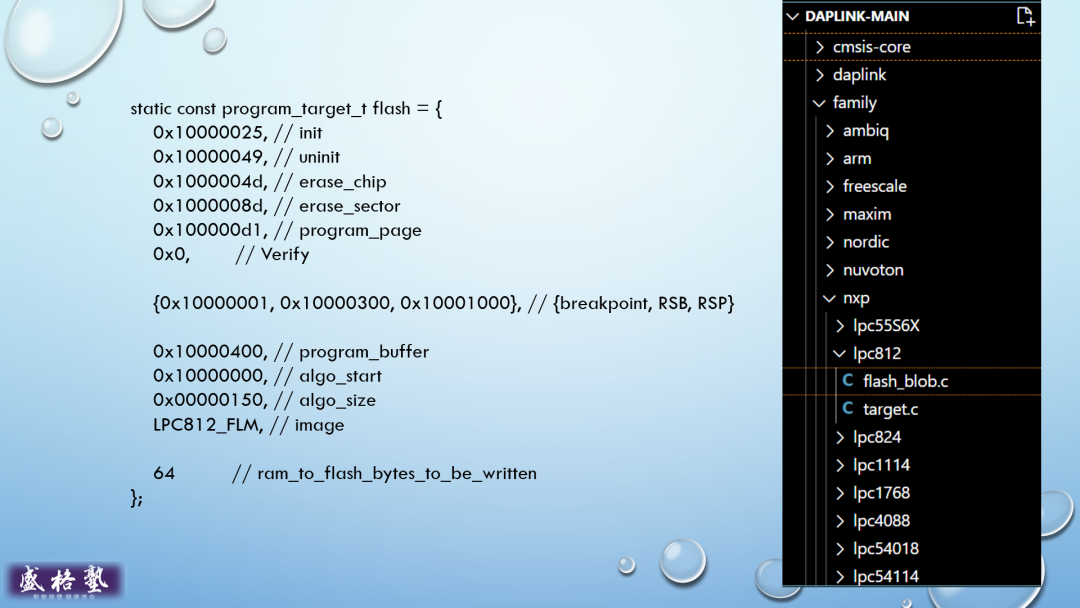
NDB把闪存算法程序会写到GDK3的内存里后,重启M核,让它进入算法程序。
算法程序开始工作后,便监视FIFO区域(在算法程序后面),如果有要写的数据,便把它写到闪存区域。
在主机端,NDB启动算法程序后,便把要更新闪存内容写到FIFO区。两端如此配合实现固件更新。
再回到出问题的函数(如下图)。它的1016行便是启动算法程序。
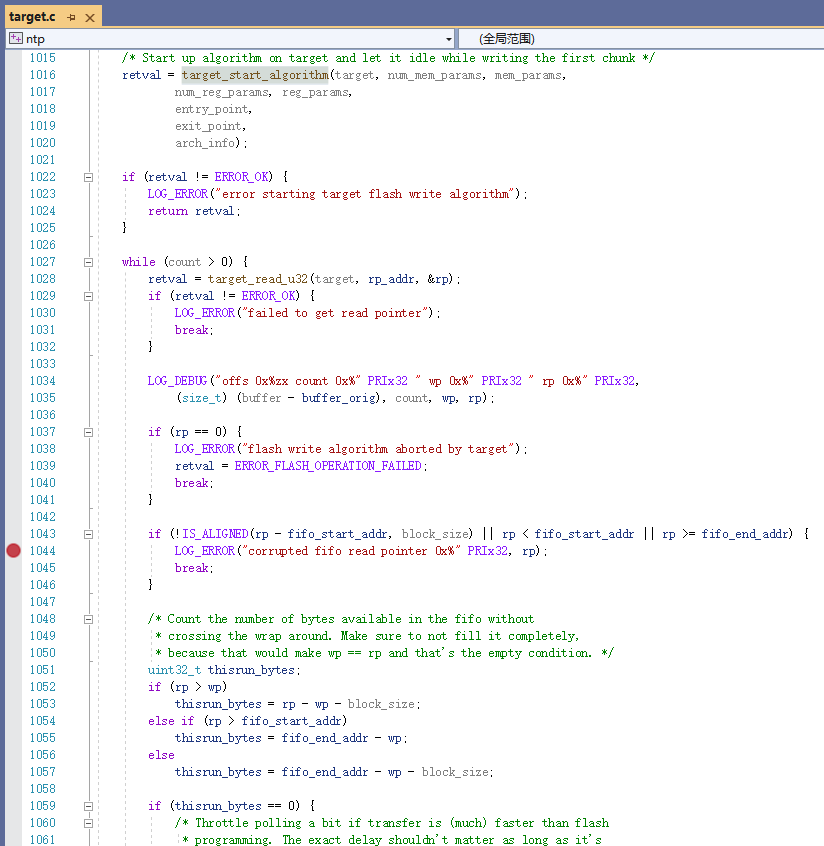
1027行开始的循环便是与算法程序配合,反复向FIFO写数据的。
对于这个错误,我首先想到,疫情期间开发GDK3时,一开始也是无法用NDB烧写固件的,后来解决了。但是如何解决的细节记不清了。搜索代码里的注释,没啥收获。
接下来想到的是算法程序的差别。我首先比较了能工作的老版本和新版本,确认二者是一致的。
抱着试试看的想法,我也咨询了GDK3所用芯片的工程师。
芯片支持工程师的态度非常好,根据芯片工程师的提示,我顺着思路怀疑到了挥码枪,仔细核对了挥码枪里的固件逻辑,但是也没什么收获。
试了上面各种方法都没有效果后,我穿插做了些其它的工作。
但是过了几天后,我又想到这个问题。一个问题如果不解决,就像是一个鱼刺卡在喉咙里,即使暂时不痛了,一旦想起来,还是难受。于是我又打开VS,复现问题,设置断点,一步步跟踪有关的代码。
一边跟踪,我一边核对各种地址信息,寻找线索。
特别的,我仔细阅读了闪存算法,梳理了内存布局,特别是FIFO的位置,把这些都弄懂后,继续跟踪代码。
反复跟踪启动算法程序的过程后,我感觉算法程序确实被下载到GDK3了。使用NDB观察,它也确实在执行了。
如此看来,很多逻辑都工作了,一切都工作的非常好。
那为什么报错呢?
走遍千山万水后,我终于跟踪到了包含错误信息的while循环。
为了深刻理解这个循环的工作过程,我特别切换回老的代码,看老的代码如何工作。
有了正确的样本后,我再切换到有问题的代码继续跟踪。
当我第二次跟踪包含log的while循环时,我仔细核对进入报错信息的条件,也就是下面的几条语句:
if (!IS_ALIGNED(rp - fifo_start_addr, block_size) || rp < fifo_start_addr || rp >= fifo_end_addr) {
LOG_ERROR("corrupted fifo read pointer 0x%" PRIx32, rp);
break;
}判断条件的if语句有点长,是把三个条件或在一起:
- !IS_ALIGNED(rp - fifo_start_addr, block_size)
- rp < fifo_start_addr
- rp >= fifo_end_addr
观察有关的几个变量,后两个条件都不满足。
再仔细看第一个条件,是判断地址对齐的,用了个‘!’,也就是不对齐时报错。
心算一下,p就是fifo_start_addr,p-fifo_start_addr = 0,应该符合对齐原则的,但是单步一下,居然进了条件块。
这时,仿佛有一道光在我的脑海里闪过。就是这里有问题啊!
进一步看IS_ALIGNED宏,进一步确认了推测,这个宏最初是针对Linux写的,写法如下:
#define IS_ALIGNED(x, a) (((x) & ((typeof(x))(a) - 1)) == 0)
移植到Windows后,因为VC不支持typeof,所以移植时使用了一种简易的写法:
((x)%(a)) == 0
但是这种写法在x大于a时成立,但是在x为0时是错误的。
将宏改写为如下形式后:
#define IS_ALIGNED(x, a) (((x) & ((a) - 1)) == 0)
问题不见了。
案例讲完了。搜遍千山万水之后,其实出错的语句就在log语句的上一行。因为此,调试第一心法就两个字:近思。
遇到问题,不要从远处想起,要从近处想起。不要怀疑太多,太远,先怀疑较少,较近的代码。
今早,格友群里说起学车的问题。
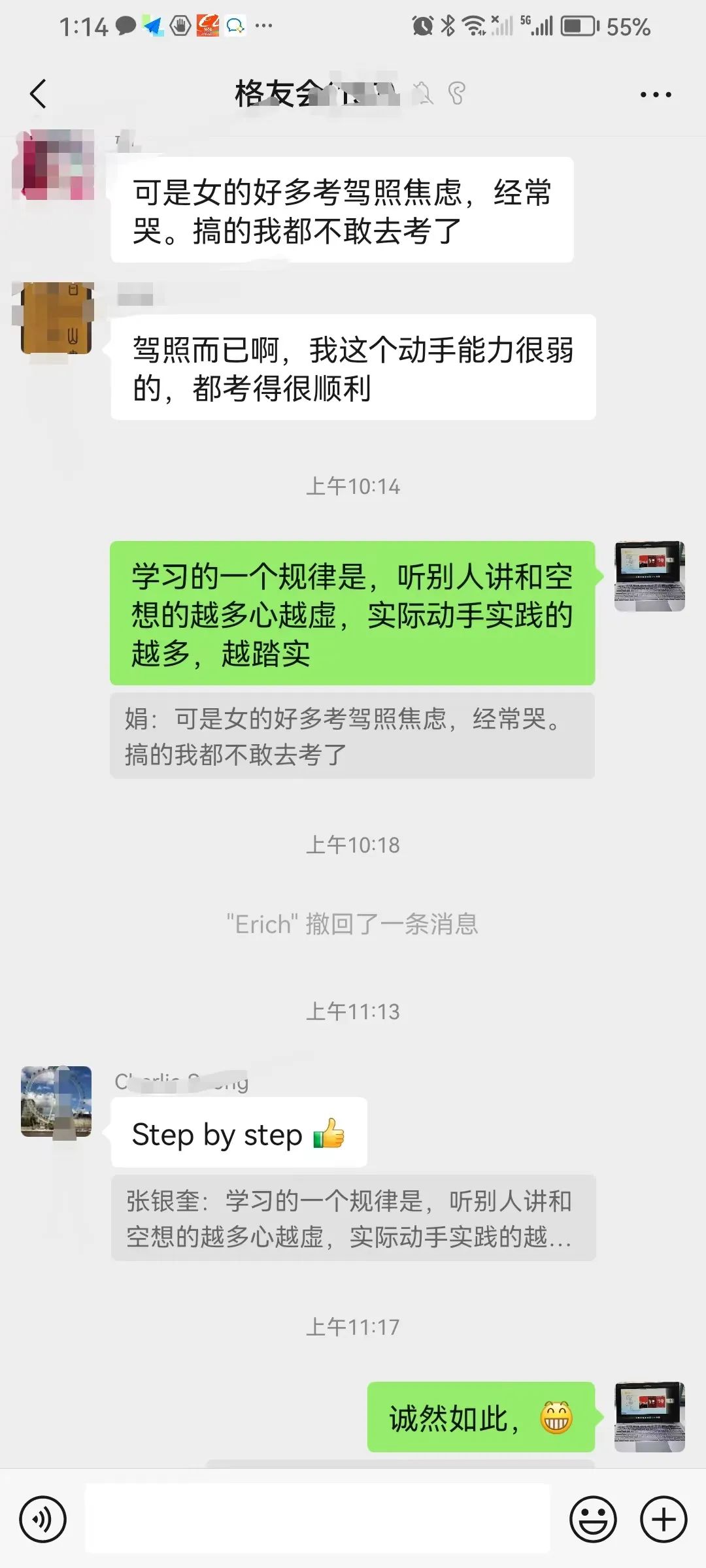
我分享了我思考许久的一个“学习规律”:听别人讲和空想的越多心越虚,实际动手实践的越多,越踏实。
其实这个规律也适用于调试的,遇到问题,想的越多,怀疑的越多,对问题的恐惧越大。相反,低下头来,实实在在地跟踪问题附近的代码,常常有意想不到的成果。
顺便预告一下,今天晚上,2024年的第一期《内核夜话》开播,欢迎新老朋友来听,我会分享更多的调试故事。

(写文章很辛苦,恳请各位读者点击“在看”,也欢迎转发)
*************************************************
正心诚意,格物致知,以人文情怀审视软件,以软件技术改变人生
扫描下方二维码或者在微信中搜索“盛格塾”小程序,可以阅读更多文章和有声读物

也欢迎关注格友公众号



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









