






Hive 基础概念
Hive是基于Hadoop的一个数据仓库,Hive能够将SQL语句转化为MapReduce任务进行运行。
Hive架构图分为以下四部分。
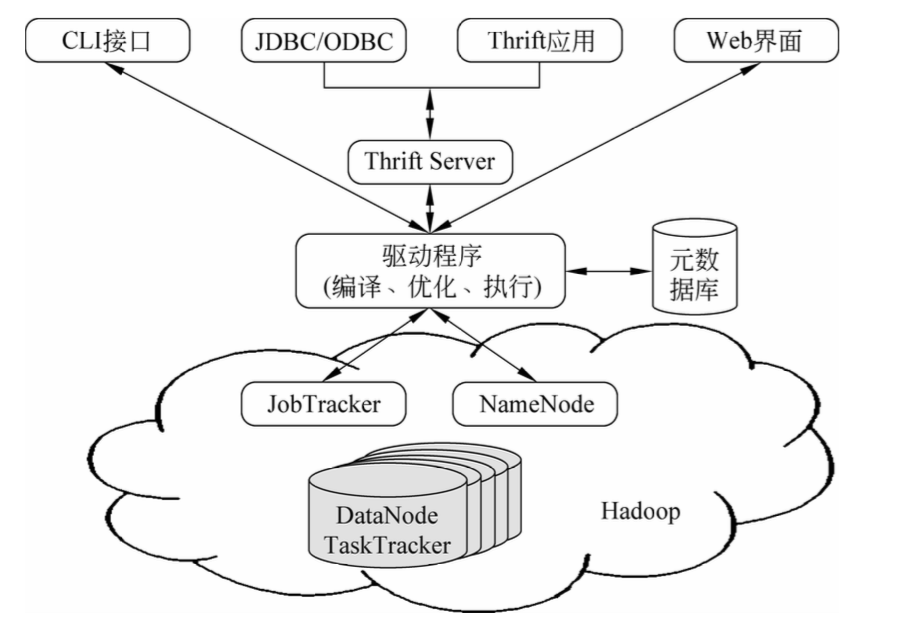
1、用户接口
Hive有三个用户接口:
-
- 命令行接口(CLI):以命令行的形式输入SQL语句进行数据数据操作
- Web界面:通过Web方式进行访问。
- Hive的远程服务方式:通过JDBC等方式进行访问。
2、元数据存储
将元数据存储在关系数据库中(MySql、Derby),元数据包括表的属性、表的名称、表的列、分区及其属性以及表数据所在的目录等。
3、解释器、编译器、优化器
分别完成SQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后由MapReduce调用执行。
4、数据存储
Hive没有专门的数据存储格式,也没有为数据建立索引,Hive中所有数据都存储在HDFS中。
Hive包含以下数据模型:表、外部表、分区和桶
Metadata,Metastore 的作用
Metadata即元数据: 元数据包含用Hive创建的database、tabel等的元信息。元数据存储在关系型数据库中。如Derby、MySQL等。
Metastore的作用是: 客户端连接metastore服务,metastore再去连接MySQL数据库来存取元数据。
有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore 服务即可。
Metastore Database & Server 运行模式
我的Hive 版本是3.1.2,很多参数设置都是该版本的。若是hive1、2,请参考https://cwiki.apache.org/confluence/display/Hive/AdminManual+Metastore+Administration#AdminManualMetastoreAdministration-HiveMetastoreAdministration。
Metastore Databse
默认使用的是derby,这个数据库有两种使用模式。
Database Embedded 模式
数据库作为一个lib,和hive server、metastore server位于同一个进程,metastore server负责启动和关闭数据库。若不给配置文件或使用hive-default-template生成的配置文件,就是这种模式。因为数据库位于某进程内,数据处于内存中,若其他进程需要访问改数据库只能以只读模式打开,因此不能在Embedded模式的数据库上创建两个metastore server(因为他们都需要读写功能)。
常见的配置信息如下:
Config Param
Config Value
Comment
javax.jdo.option.ConnectionURL
jdbc:derby:;databaseName=
../build/test/junit_metastore_db;create=trueDerby database located at hive/trunk/build...
javax.jdo.option.ConnectionDriverName
org.apache.derby.jdbc.EmbeddedDriverDerby embeded JDBC driver class.
详情参考: https://cwiki.apache.org/confluence/display/Hive/AdminManual+Metastore+Administration#AdminManualMetastoreAdministration-Local/EmbeddedMetastoreDatabase(Derby)
Database Remote 模式
数据库作为服务器模式,独立一个进程运行,可被多个metastore进程共享。常见的配置信息如下:
Config Param
Config Value
Comment
javax.jdo.option.ConnectionURL
jdbc:mysql://<host name>/<database name>?createDatabaseIfNotExist=truemetadata is stored in a MySQL server
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.DriverMySQL JDBC driver class
javax.jdo.option.ConnectionUserName
<user name>user name for connecting to MySQL server
javax.jdo.option.ConnectionPassword
<password>password for connecting to MySQL server
当然derby也是可以使用服务器模式的,详情参看:https://cwiki.apache.org/confluence/display/Hive/HiveDerbyServerMode
当前支持的数据库服务器列表:
Database
Minimum Supported Version
Name for Parameter Values
See Also
MySQL 5.6.17 mysqlPostgres 9.1.13 postgresOracle 11g oraclehive.metastore.orm.retrieveMapNullsAsEmptyStrings MS SQL Server 2008 R2 mssql
Metastore Server 运行模式
Server Embedded 模式
Metastore Server 和 Hive Server 运行在同一进程之内,为Hive Server 提供meta 数据服务。hive.metastore.uris没有值时默认就是Embedded模式,此时的metastore database 可以是embedded / remote 模式。
Config Param
Hive 2 Parameter Config Value
Comment
metastore.thrift.uris
hive.metastore.uris
not needed because this is local store
详情参考: https://cwiki.apache.org/confluence/display/Hive/AdminManual+Metastore+3.0+Administration#AdminManualMetastore3.0Administration-EmbeddedMode
Server Remote 模式
Metastore Server 以独立进程运行,可为多个Hive Server提供服务。需要提供的配置如下:
Configured On
Parameter
Hive 2 Parameter
Format
Default Value
Comment
Server metastore.thrift.port hive.metastore.port integer 9083 Port Thrift will listen on. Client metastore.thrift.uris hive.metastore.uris thrift://<HOST>:<PORT>[, thrift://<HOST>:<PORT>...] none HOST = hostname, PORT = should be set to match metastore.thrift.port on the server (which defaults to 9083. You can provide multiple servers in a comma separate list.
启动meatstore server命令:
hive --service metastore
连接 remote metastore server时,仅需要做如下配置:
Config Param
Config Value
Comment
hive.metastore.uris
thrift://<host_name>:<port>host and port for the Thrift metastore server. If hive.metastore.thrift.bind.host is specified, host should be same as that configuration. Read more about this in dynamic service discovery configuration parameters.
hive.metastore.warehouse.dir
<base hdfs path>Points to default location of non-external Hive tables in HDFS.
Hive 运行模式
Hive的运行模式主要由metastore database的运行模式和metastore server的运行模式组合产生四种不同形式。
1. embedded metastore database + embedded metastore server
不添加任何配置或者拷贝hive-default-template.xml生成的配置hive-site.xml就是这种启动模式。本地独立使用hive时,可采用该模式。
2. embedded metastore database + remote metastore server
就是使用嵌入式数据库作为metastore的存储,独立metastore服务共hive server 或其他引擎(如spark sql)使用。本地spark+hive时可以采用该模式。但是这个模式很容易出错,spark+hive推荐使用模式4.
使用embedded database + remote metastore server 模式时,数据库需要初始化一个干净的数据库,不能使用hiveserver2使用(embedded database + embedded metastore server)启动过的数据库。否则会抛出“A read-only user or a user in a read-only database is not permitted to disable read-only mode on a connection” exception.
>$HIVE_HOME/bin/schemaTool -initSchema --dbType "derby"
> $HIVE_HOME/bin/hive --service metastore
>$HIVE_HOME/bin/hive --service hiveserver2
一定要注意启动顺序,等metastore服务启动完成后再启动hiveserver2.
3. remote metastore database + embedded metastore server
使用独立的metastore数据库(如mysql),metastore server + hive server 位于同一个进程。单纯的仅使用hive的,多hiveserver集群推荐使用。
4. remote metastore database + remote metastore server
独立的数据库存储meta数据,独立的metastore服务供第三方调用,production环境,spark+hive等采用该模式。
参考文章:
https://cwiki.apache.org/confluence/display/Hive/GettingStarted#GettingStarted-MetadataStore
https://cwiki.apache.org/confluence/display/Hive/AdminManual+Metastore+3.0+Administration
https://www.cnblogs.com/netuml/p/7841387.html


















 1276
1276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









