




目录
以executeSelectStatement为例的请求处理源码:
摘要:
解析influxdb集群启动及请求处理流程
时序图:
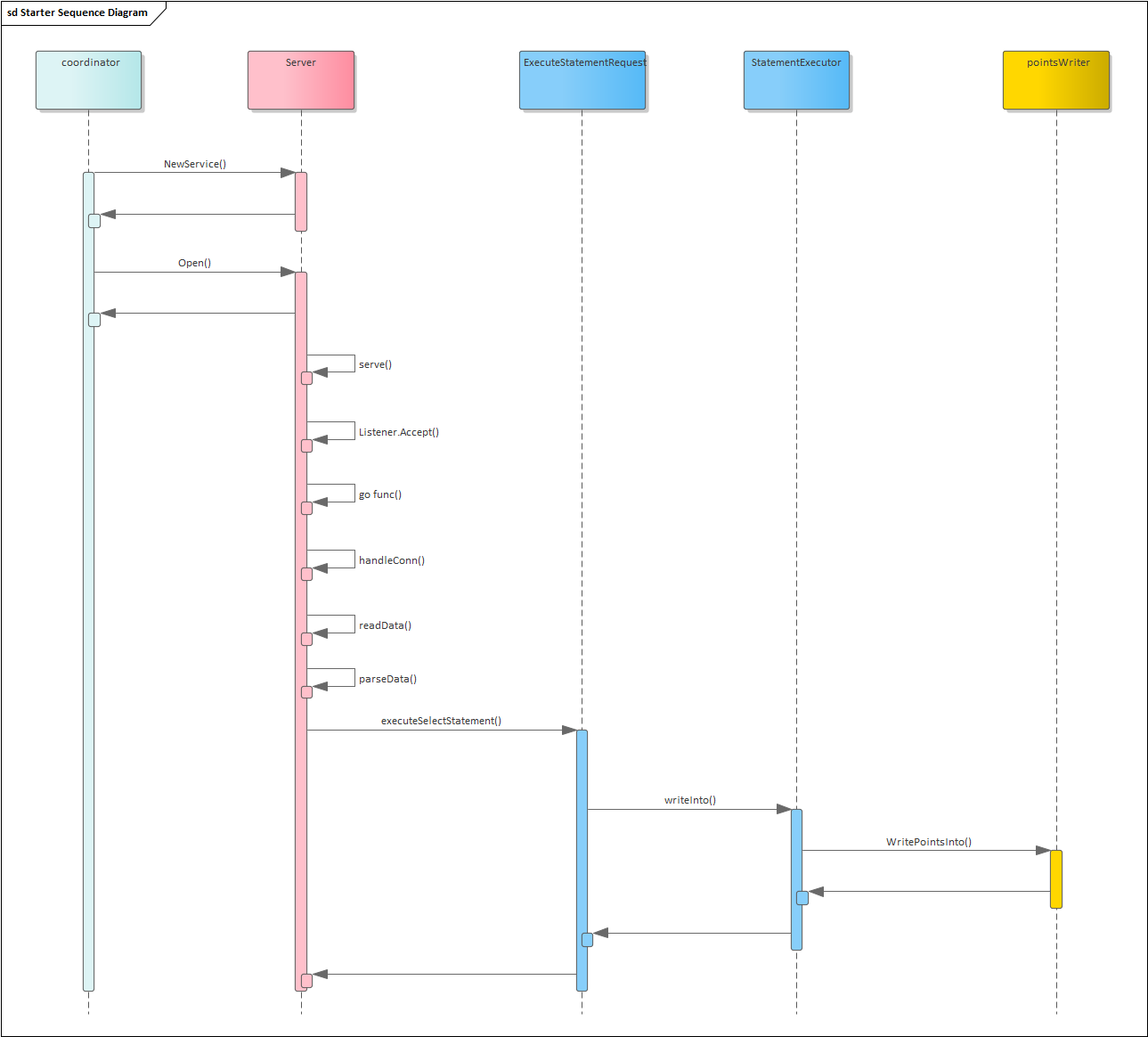
可以看出流程如下:
- 启动服务后监听对应端口
- 有请求连接后, 建立新协程处理该连接的数据
- 每个连接单独一个协程处理数据
- 读取连接发送的数据, 解析请求
- 根据请求的类型做不同的接口分发
源码处理:
启动服务:
// Service processes data received over raw TCP connections.
type Service struct {
mu sync.RWMutex
wg sync.WaitGroup
closing chan struct{}
Listener net.Listener
MetaClient interface {
ShardOwner(shardID uint64) (string, string, *meta.ShardGroupInfo)
}
TSDBStore TSDBStore
Logger *zap.Logger
statMap *expvar.Map
}
// NewService returns a new instance of Service.
func NewService(c Config) *Service {
return &Service{
closing: make(chan struct{}),
//Logger: log.New(os.Stderr, "[cluster] ", log.LstdFlags),
Logger: zap.NewNop(),
statMap: freetsdb.NewStatistics("cluster", "cluster", nil),
}
}
// Open opens the network listener and begins serving requests.
func (s *Service) Open() error {
s.Logger.Info("Starting cluster service")
// Begin serving conections.
s.wg.Add(1)
go s.serve()
return nil
}对每个新连接开辟新的协程:
// serve accepts connections from the listener and handles them.
func (s *Service) serve() {
defer s.wg.Done()
for {
// Check if the service is shutting down.
select {
case <-s.closing:
return
default:
}
// Accept the next connection.
conn, err := s.Listener.Accept()
if err != nil {
if strings.Contains(err.Error(), "connection closed") {
s.Logger.Info("cluster service accept", zap.Error(err))
return
}
s.Logger.Info("accept", zap.Error(err))
continue
}
// Delegate connection handling to a separate goroutine.
s.wg.Add(1)
go func() {
defer s.wg.Done()
s.handleConn(conn)
}()
}
}
读取数据并解析请求:
// handleConn services an individual TCP connection.
func (s *Service) handleConn(conn net.Conn) {
// Ensure connection is closed when service is closed.
closing := make(chan struct{})
defer close(closing)
go func() {
select {
case <-closing:
case <-s.closing:
}
conn.Close()
}()
for {
// Read type-length-value.
typ, err := ReadType(conn)
if err != nil {
if strings.HasSuffix(err.Error(), "EOF") {
return
}
s.Logger.Info("unable to read type", zap.Error(err))
return
}
// Delegate message processing by type.
switch typ {
case writeShardRequestMessage:
buf, err := ReadLV(conn)
if err != nil {
s.Logger.Info("unable to read length-value:", zap.Error(err))
return
}
s.statMap.Add(writeShardReq, 1)
err = s.processWriteShardRequest(buf)
if err != nil {
s.Logger.Info("process write shard error:", zap.Error(err))
}
s.writeShardResponse(conn, err)
case executeStatementRequestMessage:
buf, err := ReadLV(conn)
if err != nil {
s.Logger.Info("unable to read length-value:", zap.Error(err))
return
}
err = s.processExecuteStatementRequest(buf)
if err != nil {
s.Logger.Info("process execute statement error:", zap.Error(err))
}
s.writeShardResponse(conn, err)
case createIteratorRequestMessage:
s.statMap.Add(createIteratorReq, 1)
s.processCreateIteratorRequest(conn)
return
case fieldDimensionsRequestMessage:
s.statMap.Add(fieldDimensionsReq, 1)
s.processFieldDimensionsRequest(conn)
return
default:
s.Logger.Info("coordinator service message type not found:", zap.Uint8("Type", uint8(typ)))
}
}
}
以executeSelectStatement为例的请求处理源码:
func (e *StatementExecutor) executeSelectStatement(stmt *influxql.SelectStatement, ctx *query.ExecutionContext) error {
cur, err := e.createIterators(ctx, stmt, ctx.ExecutionOptions)
if err != nil {
return err
}
// Generate a row emitter from the iterator set.
em := query.NewEmitter(cur, ctx.ChunkSize)
defer em.Close()
// Emit rows to the results channel.
var writeN int64
var emitted bool
var pointsWriter *BufferedPointsWriter
if stmt.Target != nil {
pointsWriter = NewBufferedPointsWriter(e.PointsWriter, stmt.Target.Measurement.Database, stmt.Target.Measurement.RetentionPolicy, 10000)
}
for {
row, partial, err := em.Emit()
if err != nil {
return err
} else if row == nil {
// Check if the query was interrupted while emitting.
select {
case <-ctx.Done():
return ctx.Err()
default:
}
break
}
// Write points back into system for INTO statements.
if stmt.Target != nil {
n, err := e.writeInto(pointsWriter, stmt, row)
if err != nil {
return err
}
writeN += n
continue
}
result := &query.Result{
Series: []*models.Row{row},
Partial: partial,
}
// Send results or exit if closing.
if err := ctx.Send(result); err != nil {
return err
}
emitted = true
}
// Flush remaining points and emit write count if an INTO statement.
if stmt.Target != nil {
if err := pointsWriter.Flush(); err != nil {
return err
}
var messages []*query.Message
if ctx.ReadOnly {
messages = append(messages, query.ReadOnlyWarning(stmt.String()))
}
return ctx.Send(&query.Result{
Messages: messages,
Series: []*models.Row{{
Name: "result",
Columns: []string{"time", "written"},
Values: [][]interface{}{{time.Unix(0, 0).UTC(), writeN}},
}},
})
}
// Always emit at least one result.
if !emitted {
return ctx.Send(&query.Result{
Series: make([]*models.Row, 0),
})
}
return nil
}
func (e *StatementExecutor) writeInto(w pointsWriter, stmt *influxql.SelectStatement, row *models.Row) (n int64, err error) {
if stmt.Target.Measurement.Database == "" {
return 0, errNoDatabaseInTarget
}
// It might seem a bit weird that this is where we do this, since we will have to
// convert rows back to points. The Executors (both aggregate and raw) are complex
// enough that changing them to write back to the DB is going to be clumsy
//
// it might seem weird to have the write be in the Executor, but the interweaving of
// limitedRowWriter and ExecuteAggregate/Raw makes it ridiculously hard to make sure that the
// results will be the same as when queried normally.
name := stmt.Target.Measurement.Name
if name == "" {
name = row.Name
}
points, err := convertRowToPoints(name, row)
if err != nil {
return 0, err
}
if err := w.WritePointsInto(&IntoWriteRequest{
Database: stmt.Target.Measurement.Database,
RetentionPolicy: stmt.Target.Measurement.RetentionPolicy,
Points: points,
}); err != nil {
return 0, err
}
return int64(len(points)), nil
}
// writeToShards writes points to a shard and ensures a write consistency level has been met. If the write
// partially succeeds, ErrPartialWrite is returned.
func (w *PointsWriter) writeToShard(shard *meta.ShardInfo, database, retentionPolicy string,
consistency ConsistencyLevel, points []models.Point) error {
atomic.AddInt64(&w.stats.PointWriteReqLocal, int64(len(points)))
// The required number of writes to achieve the requested consistency level
required := len(shard.Owners)
switch consistency {
case ConsistencyLevelAny, ConsistencyLevelOne:
required = 1
case ConsistencyLevelQuorum:
required = required/2 + 1
}
// response channel for each shard writer go routine
type AsyncWriteResult struct {
Owner meta.ShardOwner
Err error
}
ch := make(chan *AsyncWriteResult, len(shard.Owners))
for _, owner := range shard.Owners {
go func(shardID uint64, owner meta.ShardOwner, points []models.Point) {
if w.Node.ID == owner.NodeID {
atomic.AddInt64(&w.stats.PointWriteReqLocal, int64(len(points)))
err := w.TSDBStore.WriteToShard(shardID, points)
// If we've written to shard that should exist on the current node, but the store has
// not actually created this shard, tell it to create it and retry the write
if err == tsdb.ErrShardNotFound {
err = w.TSDBStore.CreateShard(database, retentionPolicy, shardID, true)
if err != nil {
ch <- &AsyncWriteResult{owner, err}
return
}
err = w.TSDBStore.WriteToShard(shardID, points)
}
ch <- &AsyncWriteResult{owner, err}
return
}
atomic.AddInt64(&w.stats.PointWriteReqRemote, int64(len(points)))
err := w.ShardWriter.WriteShard(shardID, owner.NodeID, points)
if err != nil && tsdb.IsRetryable(err) {
// The remote write failed so queue it via hinted handoff
atomic.AddInt64(&w.stats.WritePointReqHH, int64(len(points)))
hherr := w.HintedHandoff.WriteShard(shardID, owner.NodeID, points)
if hherr != nil {
ch <- &AsyncWriteResult{owner, hherr}
return
}
// If the write consistency level is ANY, then a successful hinted handoff can
// be considered a successful write so send nil to the response channel
// otherwise, let the original error propagate to the response channel
if hherr == nil && consistency == ConsistencyLevelAny {
ch <- &AsyncWriteResult{owner, nil}
return
}
}
ch <- &AsyncWriteResult{owner, err}
}(shard.ID, owner, points)
}
var wrote int
timeout := time.After(w.WriteTimeout)
var writeError error
for range shard.Owners {
select {
case <-w.closing:
return ErrWriteFailed
case <-timeout:
atomic.AddInt64(&w.stats.WriteTimeout, 1)
// return timeout error to caller
return ErrTimeout
case result := <-ch:
// If the write returned an error, continue to the next response
if result.Err != nil {
atomic.AddInt64(&w.stats.WriteErr, 1)
w.Logger.Info("write failed", zap.Uint64("shard", shard.ID), zap.Uint64("node", result.Owner.NodeID), zap.Error(result.Err))
// Keep track of the first error we see to return back to the client
if writeError == nil {
writeError = result.Err
}
continue
}
wrote++
// We wrote the required consistency level
if wrote >= required {
atomic.AddInt64(&w.stats.WriteOK, 1)
return nil
}
}
}
if wrote > 0 {
atomic.AddInt64(&w.stats.WritePartial, 1)
return ErrPartialWrite
}
if writeError != nil {
return fmt.Errorf("write failed: %v", writeError)
}
return ErrWriteFailed
}



















 1379
1379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











