




一、Ansj
1、利用DicAnalysis可以自定义词库:
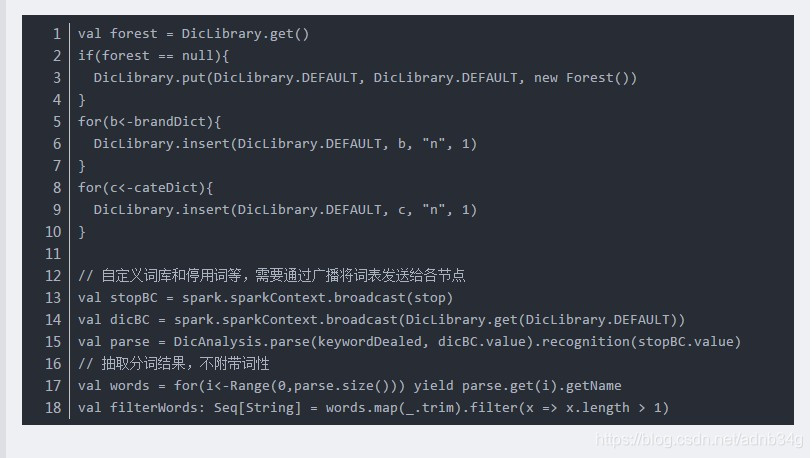
2、但是自定义词库存在局限性,导致有些情况无效:
比如:“不好用“的正常分词结果:“不好,用”。
(1)当自定义词库”好用“时,词库无效,分词结果不变。
(2)当自定义词库
“不好用”时,分词结果为:“不好用”,即此时自定义词库有效。
3、由于版本问题,可能DicAnalysis, ToAnalysis等类没有序列化,导致读取hdfs数据出错
此时需要继承序列化接口
1|case class myAnalysis() extends DicAnalysis with Serializable
2|val seg = new myAnalysis()
二、HanLP
同样可以通过CustomDictionary自定义词库:
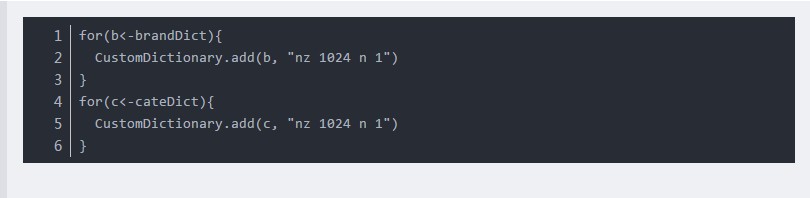
但是在统计分词中,并不保证自定义词典中的词一定被切分出来,因此用户可在理解后果的情况下通过
1|StandardTokenizer.SEGMENT.enableCustomDictionaryForcing(true)强制生效
并发问题:
CustomDictionary是全局变量,不能在各节点中更改,否则会出现并发错误。
但是HanLP.segment(sentence),只有一个参数,不能指定CustomDictionary,导致在各个excutors计算的时候全局CustomDictionary无效。
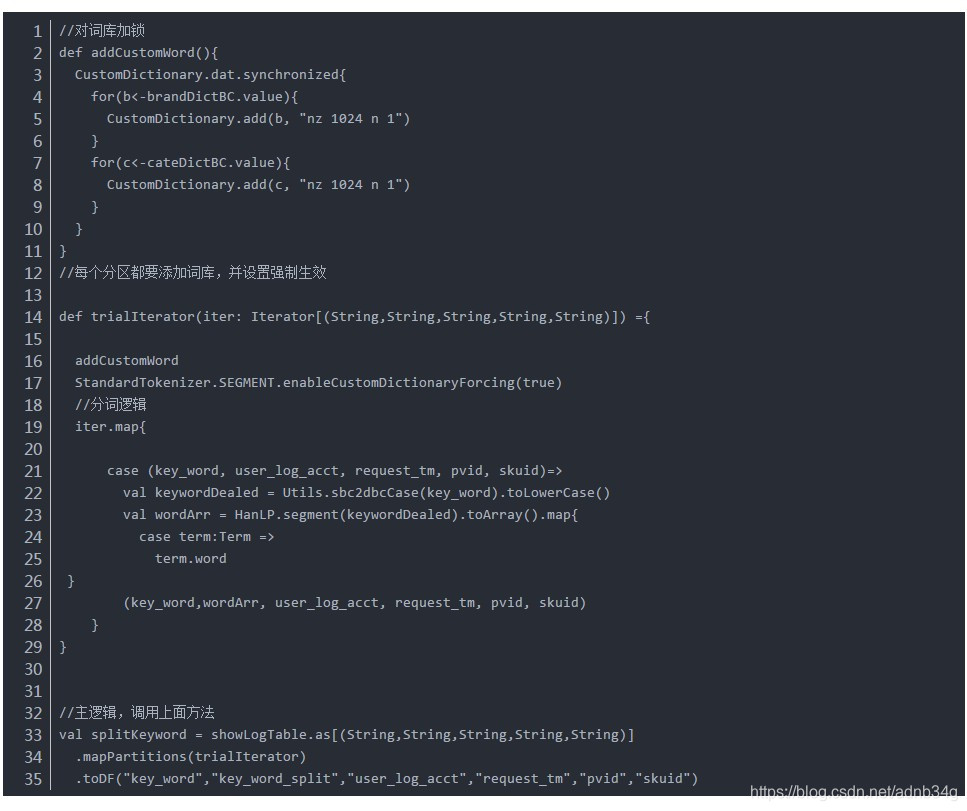
由于CustomDictionary是全局变量,因此我采用一个方式:每个分区都对CustomDictionary加锁并添加一次词库,性能影响较小:
原文链接:https://blog.youkuaiyun.com/weixin_40901056/article/details/89349095

















 806
806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









