




Django REST framework(二)-序列化器定义与使用_simpleyako的博客-优快云博客
反序列化:后端对前端传入数据进行验证
一、验证
1、参数验证
使用序列化器进行反序列化时,需要对数据进行验证后,才能获取验证成功的数据或保存成模型类对象。
在获取反序列化的数据前,必须调用is_valid()方法进行验证,验证成功返回True,否则返回False。
验证失败,可以通过序列化器对象的errors属性获取错误信息,返回字典,错误信息包含了字段和字段的错误。如果是非字段错误,可以通过修改REST framework配置中的NON_FIELD_ERRORS_KEY来控制错误字典中的键名。![]()
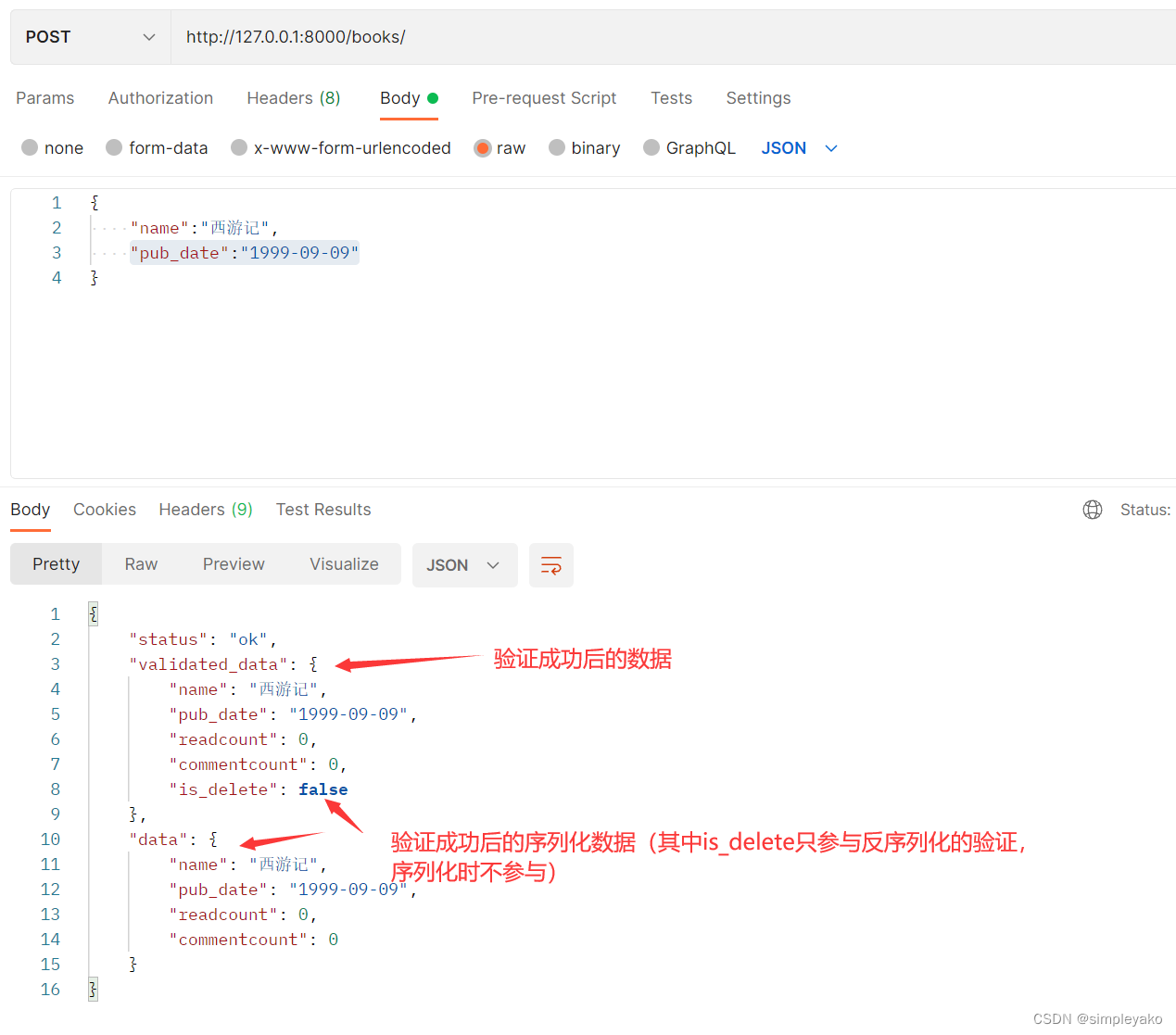
验证成功,可以通过序列化器对象的validated_data属性获取验证后的数据,通过序列器对象的data获取序列化后的数据
在定义序列化器时,指明每个字段的序列化类型和选项参数,本身就是一种验证行为。
在我们之前定义的BookInfoSerializer上添加验证参数
class BookInfoSerializer(serializers.Serializer):
"""
定义BookInfo表序列化器(序列化的定义与模型定义要相互对应)
指定需要返回的字段,继承自serializers.Serializer
"""
# 最大值20,最小值3,不允许为None值,必传
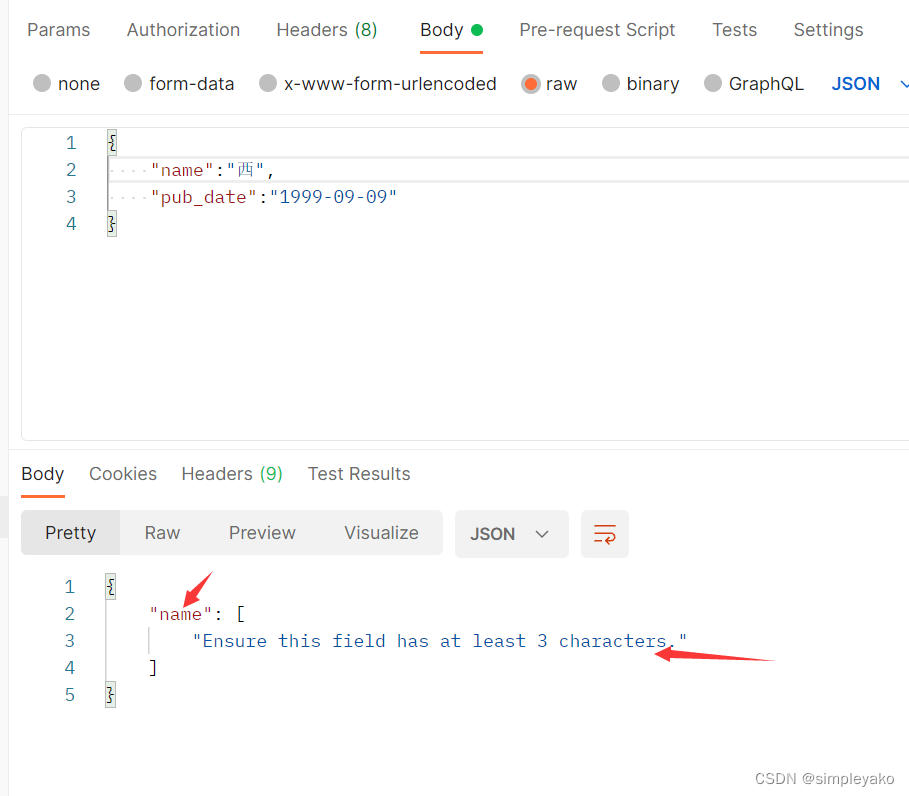
name = serializers.CharField(max_length=20, min_length=3, allow_null=False, allow_blank=False, required=True)
# 不允许为none值,必传
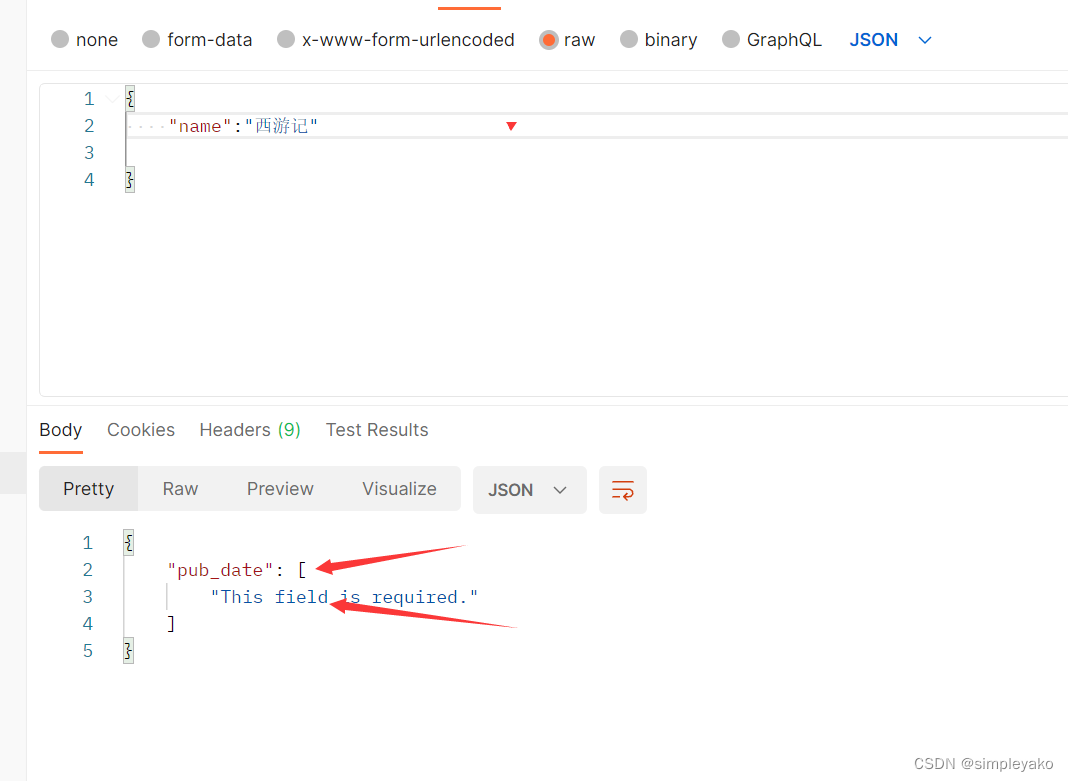
pub_date = serializers.DateField(allow_null=True, label='发布日期', required=True)
readcount = serializers.IntegerField(default=0, min_value=0, label='阅读量')
commentcount = serializers.IntegerField(default=0, min_value=0, label='评论量')
# write_only只参与反序列化(只接受验证),不参与序列化(不返回)
is_delete = serializers.BooleanField(default=False, label='逻辑删除', write_only=True)
在视图中通过构造序列化器对象,并将要反序列化的数据传递给data构造参数,进而进行验证
def post(self, request):
# 接受参数
json_dict = json.loads(request.body.decode())
# 定义序列化器,传入参数
# instance: 数据模型对象
# data : 前端接受或自定义的数据
ser = BookInfoSerializer(data=json_dict)
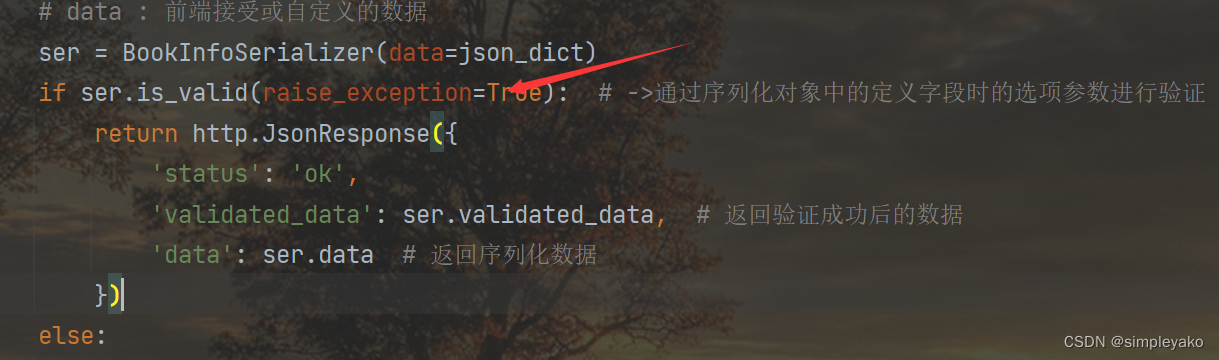
if ser.is_valid(): # ->通过序列化对象中的定义字段时的选项参数进行验证
return http.JsonResponse({
'status': 'ok',
'validated_data': ser.validated_data, # 返回验证成功后的数据
'data': ser.data # 返回序列化数据
})
else:
return http.JsonResponse(
ser.errors, # 验证失败返回错误信息
)验证成功:
验证失败:
is_valid()方法还可以在验证失败时抛出异常serializers.ValidationError,可以通过传递raise_exception=True参数开启,REST framework接收到此异常,会向前端返回HTTP 400 Bad Request响应。
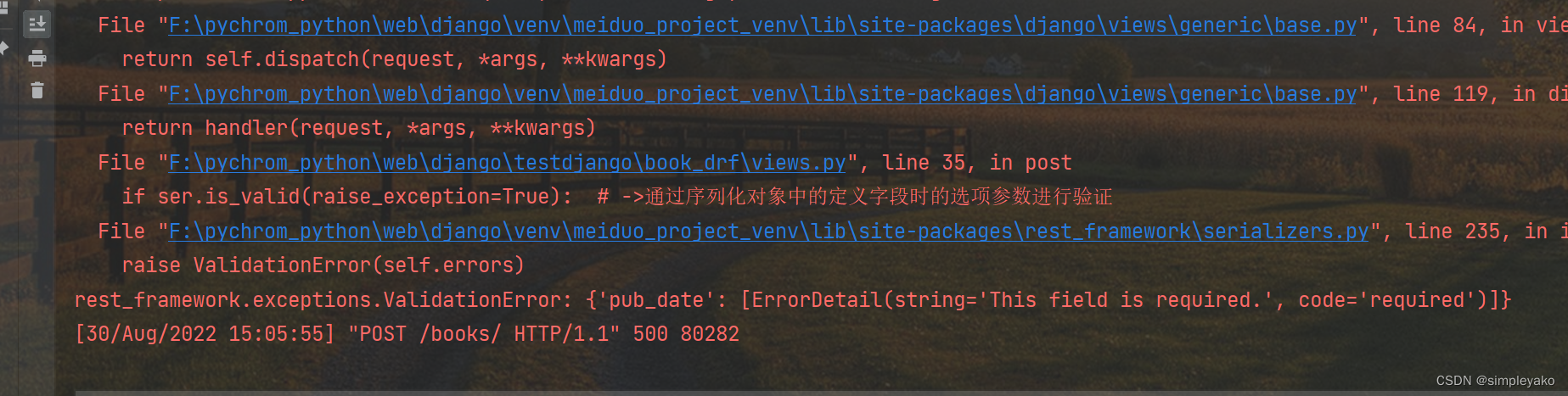
相关验证参数说明:
read_only:只在序列化时使用,不进行验证 write_only:只在反序列化时使用,不返回前端 max_length: 字段的最大长度 min_length: 字段最小擦长度 max_value: 字段最大长度 min_value: 字段最小长度 allow_null: 允许传入None值 allow_blank: 允许字段为空 required: 是否必传,默认为True default: 字段的默认值 validators:字段在验证时指定的自定义验证码[函数名]
2、validate_<field_name>方法单一字段验证
对<field_name>字段进行验证,如对name字段进行验证,在序列器中定义该方法,在视图中调用is_valid()时自动会去调用该方法进行验证
# validate_filename(固定写法)
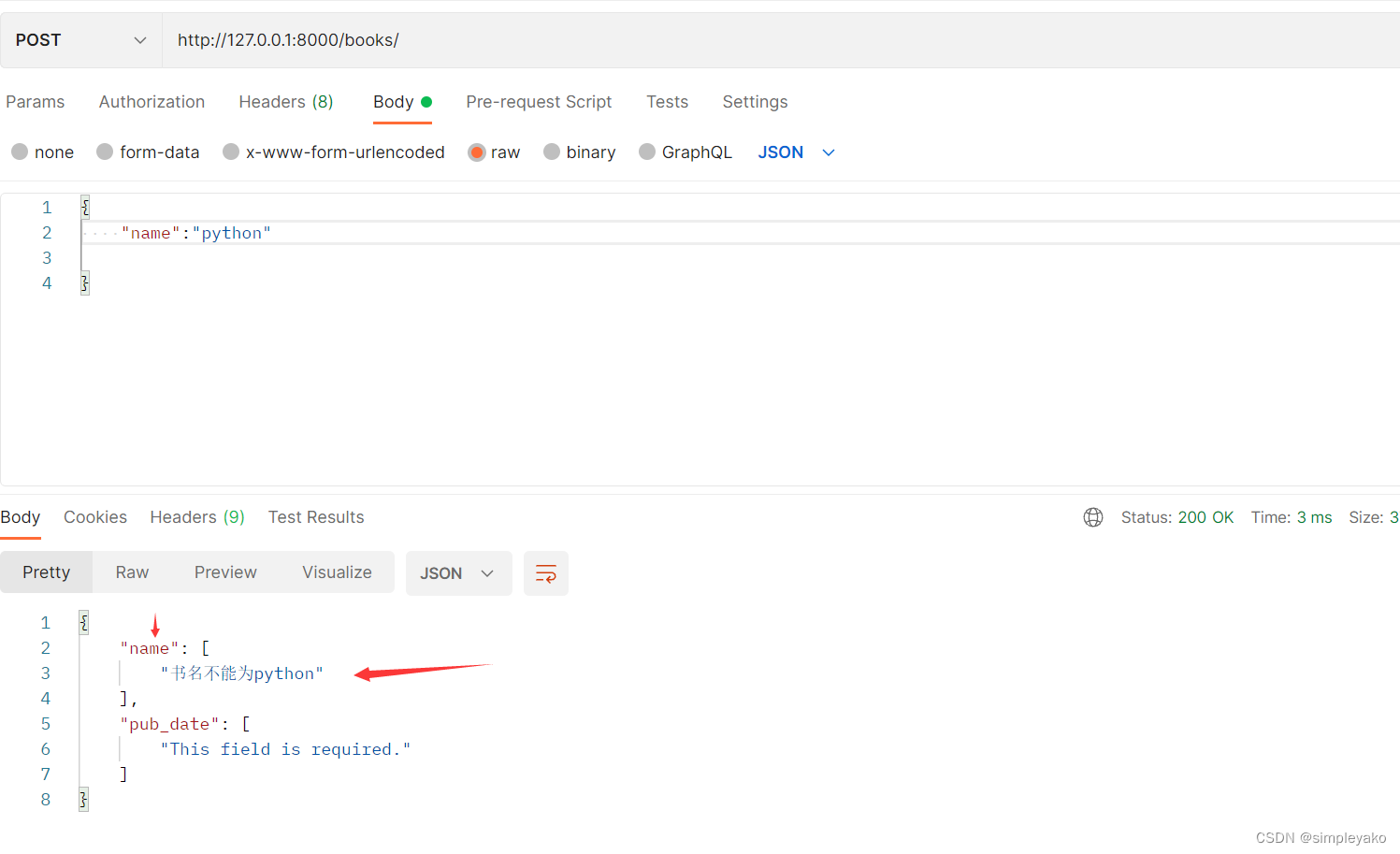
def validate_name(self, value):
print(value)
if value == 'python':
raise serializers.ValidationError('书名不能为python')
return value测试
3、validate方法多字段进行验证
在序列化器中需要同时对多个字段进行比较验证时,可以定义validate方法来验证,如在序列器中定义方法,在视图中调用is_valid()时自动会去调用该方法进行验证
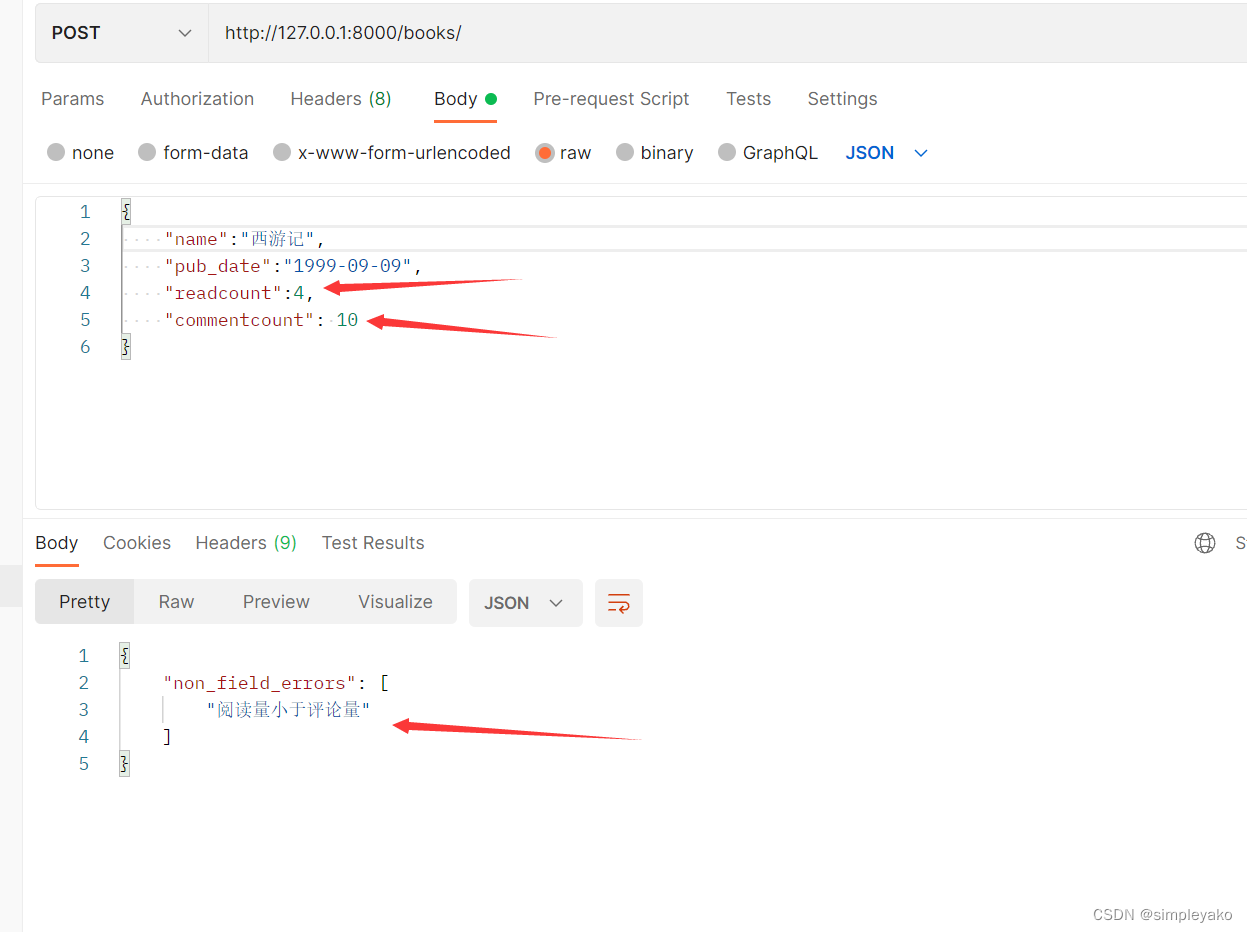
def validate(self, attrs):
print(attrs)
readcount = attrs['readcount']
commentcount = attrs['commentcount']
if readcount < commentcount:
raise serializers.ValidationError('阅读量小于评论量')
return attrs测试
4、在定义序列器字段参数指定验证方法validators(单一字段多方法验证)
在序列器外部定义验证函数方法,在字段中添加validators选项参数,指定验证行为,如
def about_name(value):
if value == 'django':
raise serializers.ValidationError('书名不能为django')
return value
class BookInfoSerializer(serializers.Serializer):
"""
定义BookInfo表序列化器(序列化的定义与模型定义要相互对应)
指定需要返回的字段,继承自serializers.Serializer
"""
# 最大值20,最小值3,不允许为None值,不允许为空
name = serializers.CharField(max_length=20, min_length=3, allow_null=False, allow_blank=False, required=True,
validators=[about_name])
pub_date = serializers.DateField(allow_null=True, label='发布日期')
readcount = serializers.IntegerField(default=0, min_value=0, label='阅读量')
commentcount = serializers.IntegerField(default=0, min_value=0, label='评论量')
# 只验证不返回,具有默认值
is_delete = serializers.BooleanField(default=False, label='逻辑删除', write_only=True)
测试:
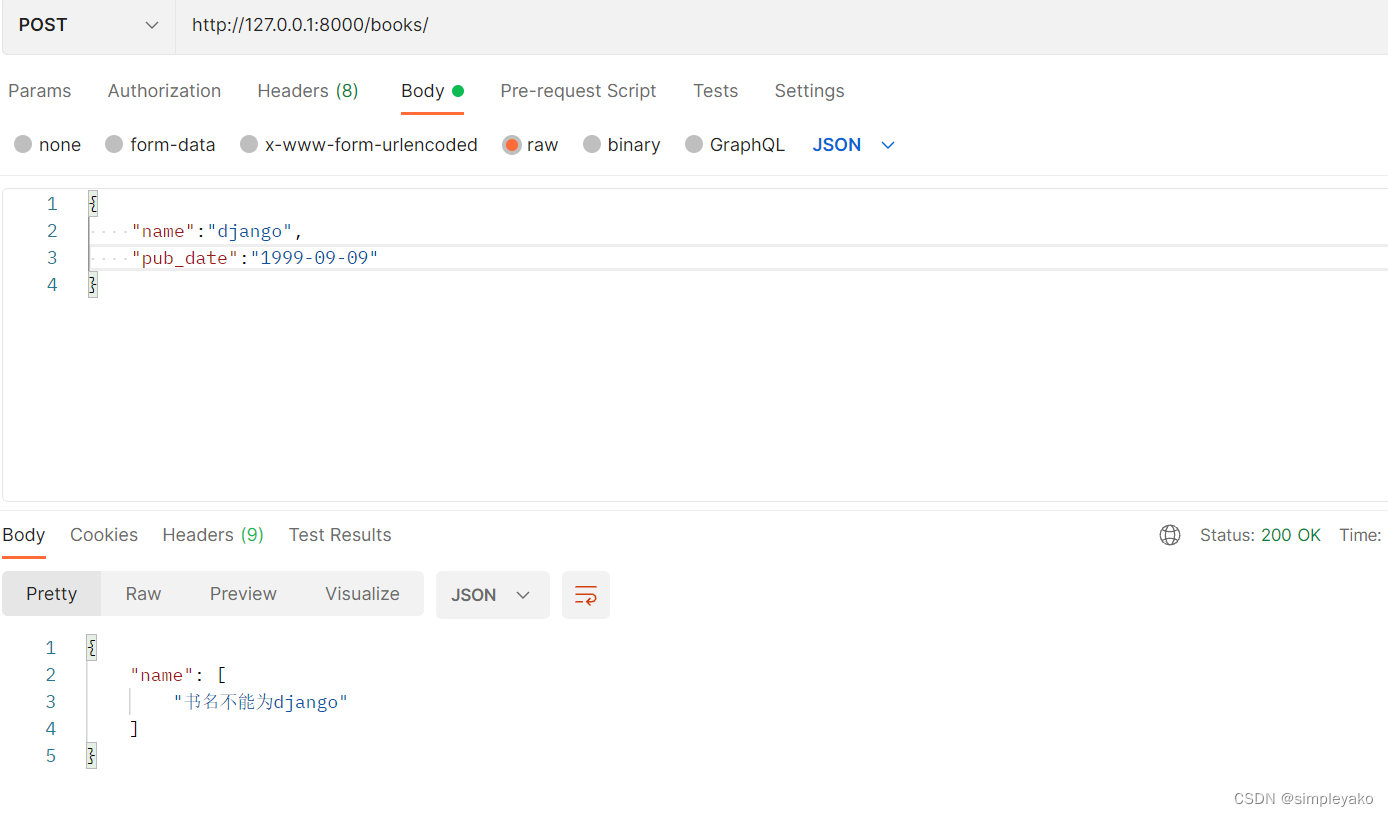
二、 序列化器的保存、更新方法方法
1、create()方法
如果在验证成功后,想要基于validated_data完成数据对象的创建,可以通过实现create()
在视图中调用save()方法会自动调用序列化器中的create()方法进行数据的创建
# 在序列器中定义保存数据序列化方法
def create(self, validated_data):
# 接受validated_data验证后的数据,进行数据对象的创建
book = BookInfo.objects.create(**validated_data)
return book
def post(self, request):
json_dict = json.loads(request.body.decode())
ser = BookInfoSerializer(data=json_dict)
if ser.is_valid() is False:
return http.JsonResponse(
ser.errors, # 验证失败返回错误信息
)
# 调用save()方法进行数据对象的创建
ser.save()
return http.JsonResponse(ser.data)
效果:
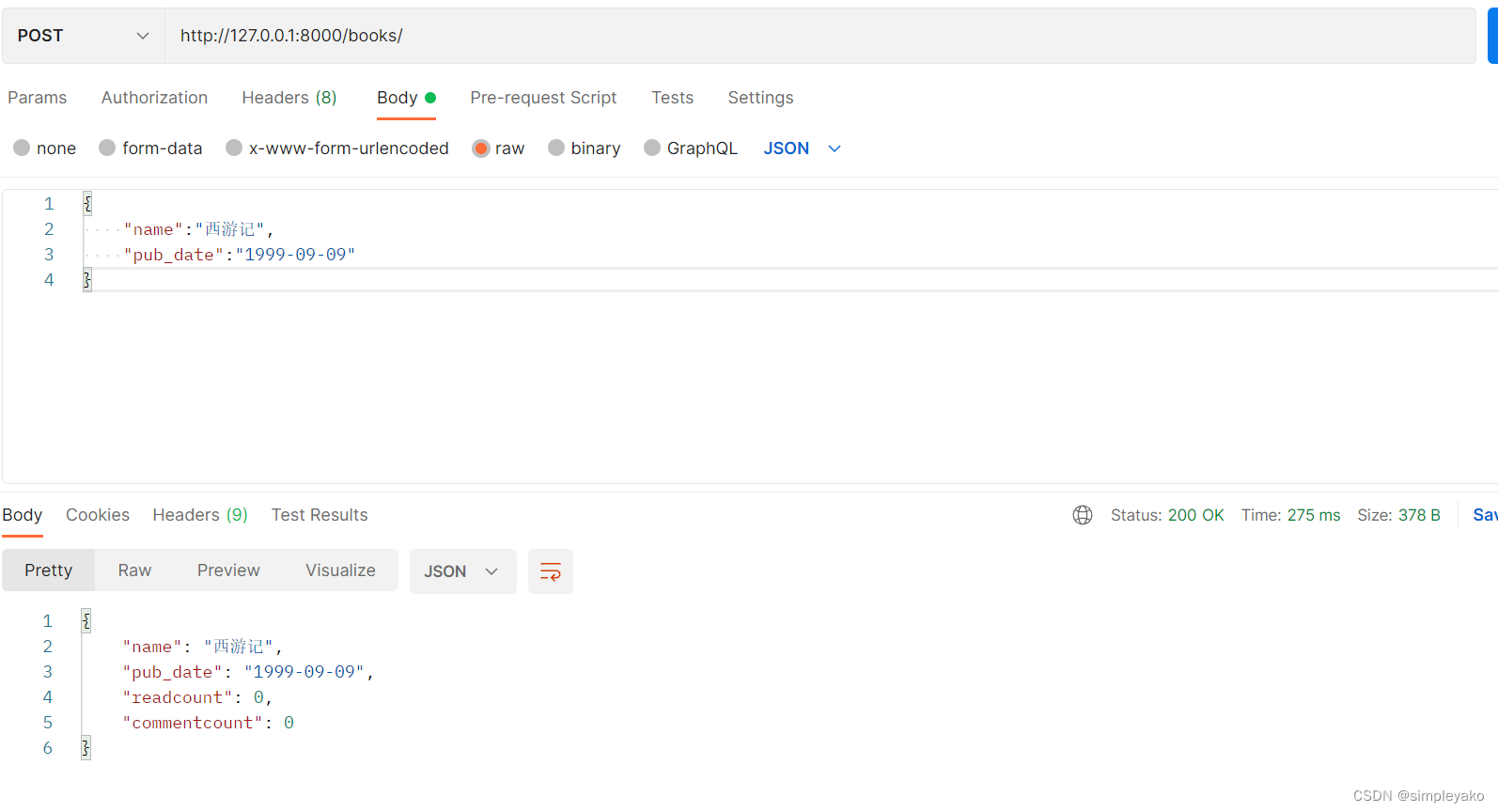
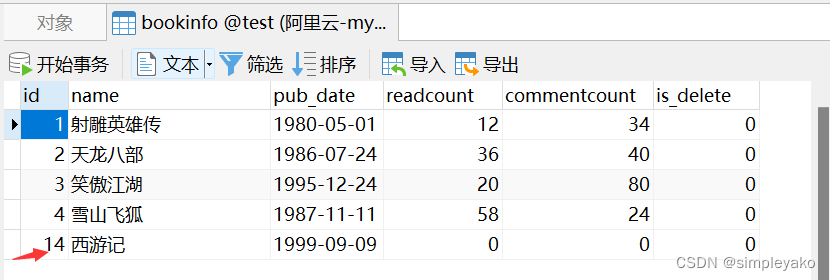
2、update方法
update方法用于更新数据模型对象记录,
在序列化器中定义update方法
instance :实例模型对象
validated_data: 反序列化验证后的数据
# 定义更新数据序列化方法
def update(self, instance, validated_data):
instance.name = validated_data['name']
instance.readcount = validated_data['readcount']
instance.commentcount = validated_data['commentcount']
instance.pub_date = validated_data['pub_date']
instance.is_delete =validated_data['is_delete']
instance.save()
return instance定义视图和路由
#路由
re_path(r'^books/(?P<pk>\d+)/$', Book_Get_Update.as_view()),
# 视图
class Book_Get_Update(View):
def put(self, request, pk):
"""更新单个图书信息"""
# 1.接收参数
json_str = request.body.decode()
json_dict = json.loads(json_str)
# 2.查询获取更新对象
try:
book = BookInfo.objects.get(id=pk)
except BookInfo.DoesNotExist:
return http.JsonResponse({'查无图书'})
# 3.初始化序列化器对象
dser = BookInfoSerializer(instance=book, data=json_dict)
# 4.通过序列化对象验证数据
dser.is_valid() # ->通过序列化对象中的定义字段时的选项参数以及定义的验证方法进行验证
# 5.调用save()方法进行对象数据更新 ->通过序列化对象中的update方法进行更新
"""
在save方法中有判断初始化序列化对象时传入的参数:
如果只传入data,则调用save方法时会调用序列化器中的create方法
如果传入模型实例对象和data,则调用save方法时会调用序列化器中的update方法
"""
dser.save()
# 6.进行序列化返回对象
return http.JsonResponse(dser.data)
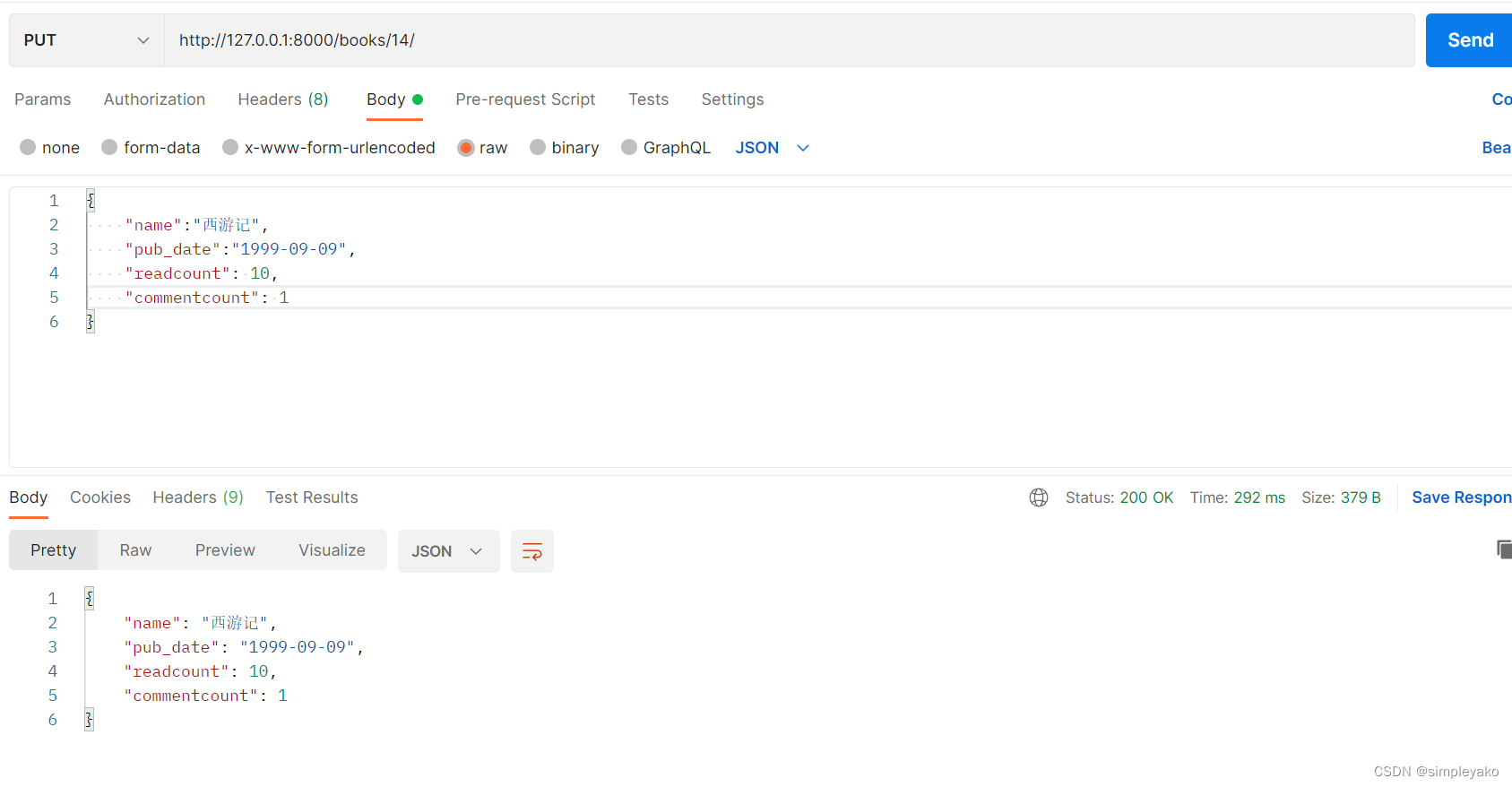
说明:
1)、创建序列化器对象的时候,没有传递instance实例,则调用save()方法的时候,create()被调用,相反,如果传递了instance实例,则调用save()方法的时候,update()被调用。
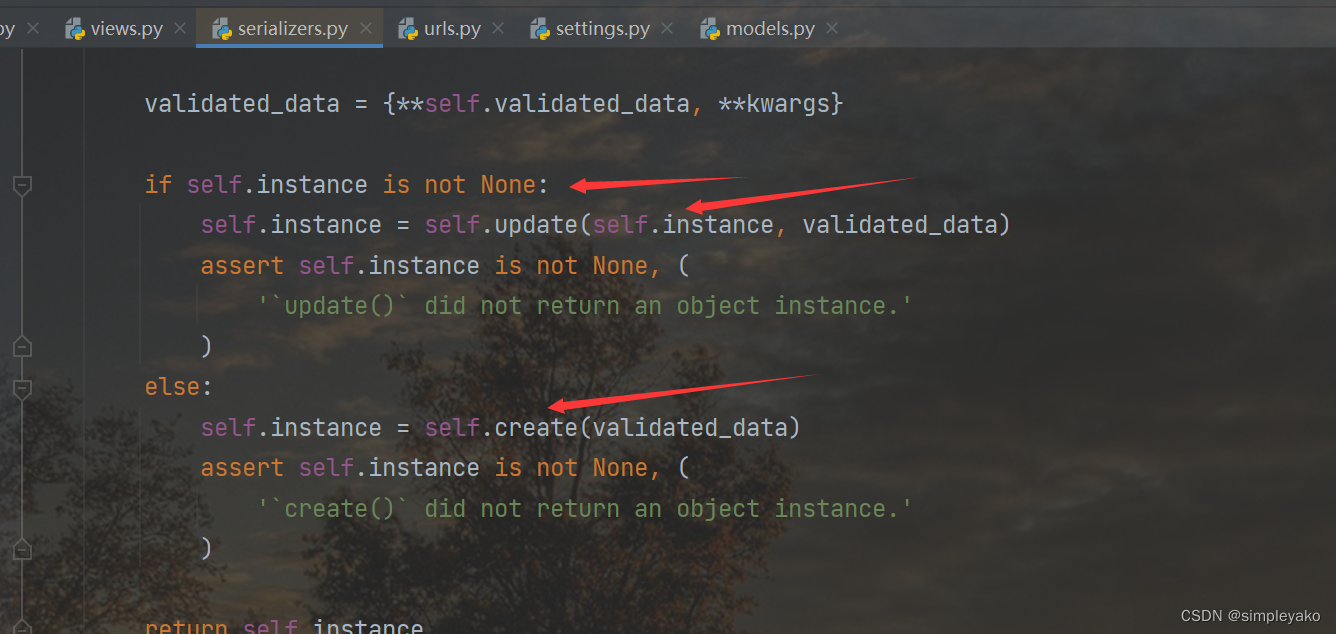
2)、在对序列化器进行save()保存时,可以额外传递数据,这些数据可以在create()和update()中的validated_data参数获取到
serializer.save(owner=request.user)
















 230
230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









