



算法与数据结构息息相关
首先有哪些数据结构呢?
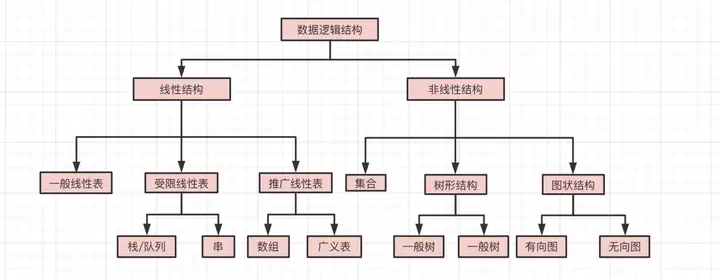 可以分为线性结构和非线性结构
可以分为线性结构和非线性结构
常见的数据结构:
1.数组
数组是相同类型数据的有序集合
按一定先后次序排列组成
每一个数据成为一个数组元素,可以通过其下标来访问他们
数组再创建时设置长度,当插入元素时们还需要重新创建数组,资源耗费大
优点:连续的存储空间通过查询下标速度很快
缺点:插入和删除时循环赋值,速度慢,容易造成资源浪费
2.链表
每个元素存储再一个单独的小内存中,知道后一个元素的地址就是单项链表,知道前后元素的地址就是双向链表
查询慢,插入和修改速度快,存储空间不连续,不浪费资源。
3.红黑树
按照主要的父接口可以分为collection和map
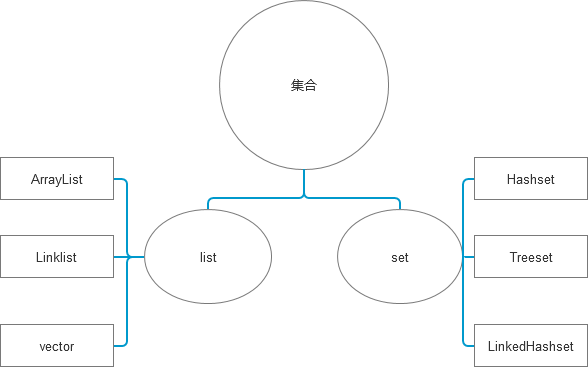
collection子类
list(接口):
vector:是基于数组array的一个list,时同步线程(syn)
Arraylist:速度快一些,但是不是同步线程需要自己考虑线程安全问题
linkedlist:基于链表,增删快,查询慢
set(一堆无重复的集合)
Hashset和Treeset是用HashMap和TreeMap实现的集合
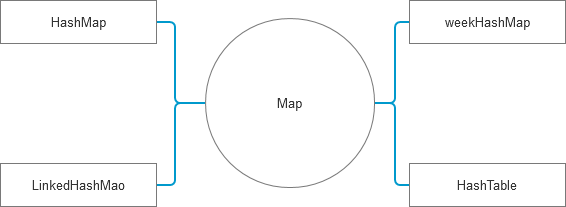
HashMap是线程不安全的
Hashtable是线程安全的(syn)但是不如concurrentHashMap(分段锁)性能好
weekHashMap可能会被gc掉entry因为其是使用弱引用的
栈:先进后出
队列:头出尾进
数组:
链表:
树:
堆:
散列表:hash
ArrayList和linkedlist的区别?
arraylist是基于数组的linkedlist是基于链表的
查询熟读快,增删速度慢
ArrayList和vector的区别?
都是基于数组的,但是ArrayList是线程不安全的,所以性能会好一些
扩容方式ArrayList扩容是阔50%,vector是扩容100%。所以vector更适合存放更大量的数据
哈希冲突?
不同的键可能会有相同的hash码
解决方案:
1.链地址法:数组加链表,链表过长转化为红黑树
2,开放地址法:开放地址法
3.再hash:当发生hash冲突时使用一个新的hash函数计算出新的哈希值存放在新的桶里
HashMap的底层实现?
数组+链表
数组+链表+红黑树 1.8
当链表中元素个数大于8(阈值)&&数组长度>64时,链表转化为红黑树
低于阈值时链表查询新增效率高,大于阈值时红黑树效率高
当红黑树节点小于6 时会退回链表


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









