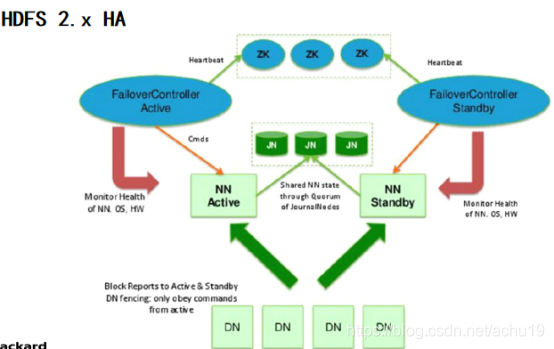
NN单点故障,难以应用于在线场景 HA NN压力过大,且内存受限,影响扩展 F(联邦机制)
官网配置页面
实现逻辑名称到物理服务器的映射 hdfs-site.xml (HA有两个namenode,一个是active,一个是standby,需要指定具体的物理节点,rpc和http地址做配置端口) core-site.xml 指定hdfs访问的入口 配置journalnode集群(同步元数据) , 配置故障转移实现的代理类和实现方式 开启自动化,启动ZKFC进程 配置zookeeper集群,指定namenode入口 配置细节 Configuring automatic failover设置自动化,配置zookeeper集群
开启四台虚拟机,并用secureCRT进行连接。通过交互窗口同步时间,查看每个服务器当前执行的进程:jps 停掉完全分布式方式:stop-dfs.sh再用jps查看 实现NN节点与其他节点间免密钥: 保存副本,以便于恢复 先对一台服务器进行配置,在hdfs-site.xml中删除secondary所在的4行(4dd),另外添加以下代码 < property> < name> </ name> < value> </ value> </ property> < property> < name> </ name> < value> </ value> </ property> < property> < name> </ name> < value> </ value> </ property> < property> < name> </ name> < value> </ value> </ property> < property> < name> </ name> < value> </ value> </ property> < property> < name> </ name> < value> </ value> </ property> < property> < name> </ name> < value> </ value> </ property> < property> < name> </ name> < value> </ value> </ property> < property> < name> </ name> < value> </ value> </ property> < property> < name> </ name> < value> </ value> </ property> < property> < name> </ name> < value> </ value> </ property> < property> < name> </ name> < value> </ value> </ property> 配置core-site.xml,将hadoop.tmp.dir的value改成/var/hpe/hadoop/ha,另外利用下方配置修改或覆盖原文件 < property> < name> </ name> < value> </ value> </ property> < property> < name> </ name> < value> </ value> </ property> 剩余的node02~node04相应的配置文件要同步 搭建Zookeeper集群 相关配置pwdpwd 启动zookeeper 启动JNN 实现ZKFC 查看active的NN与standby的NN之间的转化 以后停掉或开启dfs相关进程(集群开启之前要先启动node02~node04:zookeeper)注
























 4734
4734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









