







引言:为什么大模型应用需要事件驱动架构?
想象你经营一家大型快递物流中心:每天有上万件包裹需要分拣、运输、派送。如果采用“专人全程跟进”模式(类似传统请求响应架构),一个快递员负责从收件到派送的所有环节,一旦某个环节堵塞(如分拣延迟),整个流程就会瘫痪。而事件驱动模式就像现代物流系统——每个包裹贴有统一格式的快递单(事件),分拣中心(事件总线)根据目的地将包裹分发到不同站点(事件消费者),每个站点专注处理自己的环节(如北京站点处理北京地区派送),全程异步协同,即使某个站点忙碌,其他环节仍能正常运转。
大模型应用正面临类似的“物流困境”:
- 场景复杂多样:一个电商平台可能同时需要实时推荐(用户浏览时)、智能客服(用户咨询时)、售后分析(订单完成后)等多个大模型场景;
- 事件触发频繁:用户点击、订单支付、库存变动等行为不断产生,需实时响应;
- 服务松耦合需求:推荐模型、客服模型、分析模型需独立迭代,互不干扰。
事件驱动架构(EDA) 通过“事件发布-订阅”模式,让系统组件像物流站点一样松耦合协作,完美解决这些问题。本文将用“快递物流系统”的类比,结合电商订单处理的实战案例,解析大模型事件驱动架构的设计原则、核心组件和落地技巧。
一、大模型事件驱动架构的核心设计原则
大模型应用的事件驱动架构设计,需在“事件为中心、松耦合协作”的基础上,结合大模型推理特性(长耗时、资源密集)和业务场景需求(实时/非实时、因果关联),遵循五大核心原则:
1.1 事件标准化:统一“快递单”格式(让所有站点能识别)
事件是系统通信的“快递单”,必须遵循统一格式,否则不同服务(站点)无法解析。就像快递单必须包含收件人、目的地、物品类型等关键信息,大模型应用的事件需包含固定元数据和业务数据。
事件格式示例:
{
"event_id": "order_created_12345", // 全局唯一事件ID(快递单号)
"event_type": "order.created", // 事件类型(如订单创建、库存变动)
"timestamp": 1695000000, // 事件发生时间戳
"source": "order-service", // 事件来源服务(寄件人)
"data": { // 业务数据(包裹内容)
"order_id": "ORD789",
"user_id": "U123",
"items": [{"product_id": "P456", "quantity": 2}],
"total_amount": 299.00
},
"metadata": { // 元数据(附加信息)
"priority": "high", // 事件优先级(加急件/普通件)
"trace_id": "TRACE001" // 链路追踪ID
}
}
优势:新服务接入时无需修改现有生产者,只需解析标准事件格式,降低集成成本。例如,新增“用户行为分析服务”时,直接订阅“order.created”事件即可,无需订单服务适配。
1.2 松耦合设计:站点独立运作(分拣中心不关心派送细节)
事件生产者(如订单服务)只需发布事件,无需知道谁会消费(处理)事件;消费者(如推荐服务)只需订阅感兴趣的事件,无需知道事件来源。就像分拣中心只需按目的地分发包裹,无需关心派送员如何送货。
松耦合实现:
- 生产者无感知:订单服务发布“order.created”事件后,不关心是推荐服务、库存服务还是物流服务在消费;
- 消费者自主选择:推荐服务可随时订阅或取消订阅“order.created”事件,不影响其他服务;
- 技术栈无关:生产者用Java实现,消费者可用Python(大模型常用语言),通过事件总线通信。
案例:某电商平台新增“智能营销服务”,只需订阅“order.paid”事件(订单支付成功),即可触发大模型生成个性化优惠券,无需修改订单服务代码。
1.3 异步优先:非紧急件走“普通物流”(避免堵塞)
大模型推理中,多数场景无需同步响应(如订单完成后的售后分析、批量商品描述生成)。将这些场景异步化,就像非紧急快递走普通物流,不占用加急通道资源。
异步场景分类:
- 事后分析:用户下单后,异步触发大模型分析购买意图,用于后续推荐;
- 批量处理:夜间低峰期,处理全天积累的“商品评价情感分析”事件;
- 跨系统通知:订单状态变更后,异步通知仓储、物流等外部系统。
数据支撑:某内容平台将“用户评论审核”从同步调用改为异步事件后,系统响应延迟从500ms降至80ms,大模型资源利用率提升40%(因批量处理减少GPU idle时间)。
1.4 事件溯源:物流轨迹全程可查(问题可追溯)
事件溯源(Event Sourcing)是指将系统状态变化记录为事件序列,而非直接存储当前状态。就像快递物流全程记录“已收件→已分拣→运输中→已派送”轨迹,可随时追溯异常原因。
大模型场景应用:
- 推理过程回溯:记录“用户请求→模型调用→结果返回”完整事件链,当推荐结果异常时,可追溯是输入数据问题还是模型版本问题;
- 状态恢复:系统故障后,通过重放事件序列恢复大模型服务状态(如重新计算用户偏好);
- 合规审计:记录所有大模型调用事件(用户ID、输入文本、输出结果),满足数据合规要求。
1.5 容错与幂等:快递丢件可重发(确保最终一致性)
事件传输可能因网络抖动丢失,消费者可能重复接收事件。需设计容错机制(丢件重发)和幂等处理(重复处理不影响结果),就像快递丢件可重发,且多次派送同一包裹不会导致用户多收。
实现手段:
- 事件持久化:事件总线(如Kafka)持久化事件,确保消费者宕机后可重新消费;
- 幂等键:消费者通过“event_id”判断事件是否已处理,避免重复计算;
- 重试机制:生产者未收到事件确认时,自动重试(如最多3次,间隔指数退避)。
二、核心组件解析:大模型事件驱动架构的“物流系统”
一个完整的大模型事件驱动架构由六大核心组件构成,像快递物流系统的“寄件人、快递单、分拣中心、派送站点、轨迹记录、异常处理中心”,各司其职又协同工作:
2.1 事件生产者:寄件人(产生事件)
作用:业务系统中产生事件的组件,如订单服务(产生“订单创建”事件)、用户行为服务(产生“用户点击”事件)。
大模型场景特殊需求:
- 事件优先级标记:实时场景(如用户咨询客服)标记“high”优先级,非实时场景(如批量分析)标记“low”;
- 大模型输入预处理:生产者可对原始数据预处理后再发布事件(如用户行为事件中附加“最近7天浏览商品列表”,减少消费者处理成本)。
技术实现:在业务代码中嵌入事件发布逻辑,如订单创建接口成功后,调用事件总线SDK发布“order.created”事件。
2.2 事件总线:分拣中心(路由事件)
作用:连接生产者和消费者的“中枢神经”,负责事件的接收、存储、路由和分发,是事件驱动架构的核心组件。
大模型场景关键能力:
- 高吞吐:支持每秒数十万事件(如电商大促时的订单事件洪峰);
- 多主题隔离:按业务域划分主题(Topic),如“order-events”“user-events”“model-events”,避免干扰;
- 持久化存储:事件默认保存7天,支持消费者回溯消费(如大模型服务重启后重新处理历史事件)。
技术选型:
- Kafka:高吞吐(百万级/秒)、持久化,适合大模型事件流(如用户行为数据);
- RabbitMQ:支持复杂路由(如按事件属性过滤),适合业务逻辑复杂的事件(如订单状态变更);
- Apache Pulsar:多租户支持,适合多团队协作的大型平台。
2.3 事件消费者:派送站点(处理事件)
作用:订阅并处理事件的服务,是大模型能力的主要载体,如推荐服务(消费“用户点击”事件生成推荐)、客服服务(消费“用户咨询”事件调用对话模型)。
大模型消费者分类:
- 实时推理消费者:低延迟处理(毫秒级),如“用户搜索事件”触发实时推荐模型;
- 批量推理消费者:高吞吐处理(分钟级),如“夜间批量事件”触发商品评价情感分析模型;
- 模型训练消费者:消费标注数据事件(如“用户反馈事件”),用于模型微调。
技术实现:消费者通过事件总线SDK订阅主题,拉取事件后调用大模型处理,如Python消费者用confluent-kafka库订阅Kafka主题。
2.4 事件存储:物流轨迹数据库(持久化事件)
作用:长期存储事件数据,支持事件溯源、审计和数据分析,就像物流系统的轨迹查询系统。
存储方案:
- 时序数据库:如InfluxDB、TimescaleDB,适合存储带时间戳的事件流(如大模型推理延迟指标事件);
- 文档数据库:如MongoDB,适合存储结构灵活的事件(如包含非结构化文本的用户咨询事件);
- 对象存储:如S3、OSS,适合存储大模型推理输入输出事件(如包含图片的多模态事件)。
2.5 规则引擎:智能分拣系统(动态路由事件)
作用:根据事件内容动态决定如何处理或路由事件,就像物流中心的智能分拣系统,根据包裹大小、目的地自动选择运输方式。
大模型场景应用:
- 事件过滤:只将“高价值用户”(消费金额>1000元)的订单事件发送给大模型推理服务;
- 动态路由:“用户咨询”事件中,包含“退货”关键词的路由到售后客服模型,其他路由到售前客服模型;
- 组合事件触发:当用户连续3次浏览同一商品(“浏览事件”)且加入购物车(“加购事件”)时,触发“限时优惠”模型。
技术选型:Drools(规则引擎)、Apache Flink(流处理规则)、云厂商Serverless工作流(如AWS Step Functions)。
2.6 监控与追溯:物流监控中心(保障系统稳定)
作用:监控事件流转全链路状态,包括事件生产速率、消费延迟、大模型推理性能等,确保系统稳定运行。
关键监控指标:
- 事件指标:事件吞吐量(每秒事件数)、消费延迟(事件产生到处理完成的时间)、未消费事件堆积量;
- 大模型指标:推理延迟(P99/P95)、模型调用成功率、GPU利用率;
- 业务指标:推荐点击率(事件处理效果)、客服问题解决率(大模型输出质量)。
技术选型:Prometheus+Grafana(指标监控)、ELK Stack(日志分析)、Jaeger(分布式追踪)。
三、实战案例:电商订单处理的事件驱动架构
为让架构设计更具体,我们以“电商订单全链路处理系统”为例,解析如何用事件驱动架构集成大模型能力,实现“订单创建→库存检查→智能推荐→物流调度→售后分析”的全流程自动化。
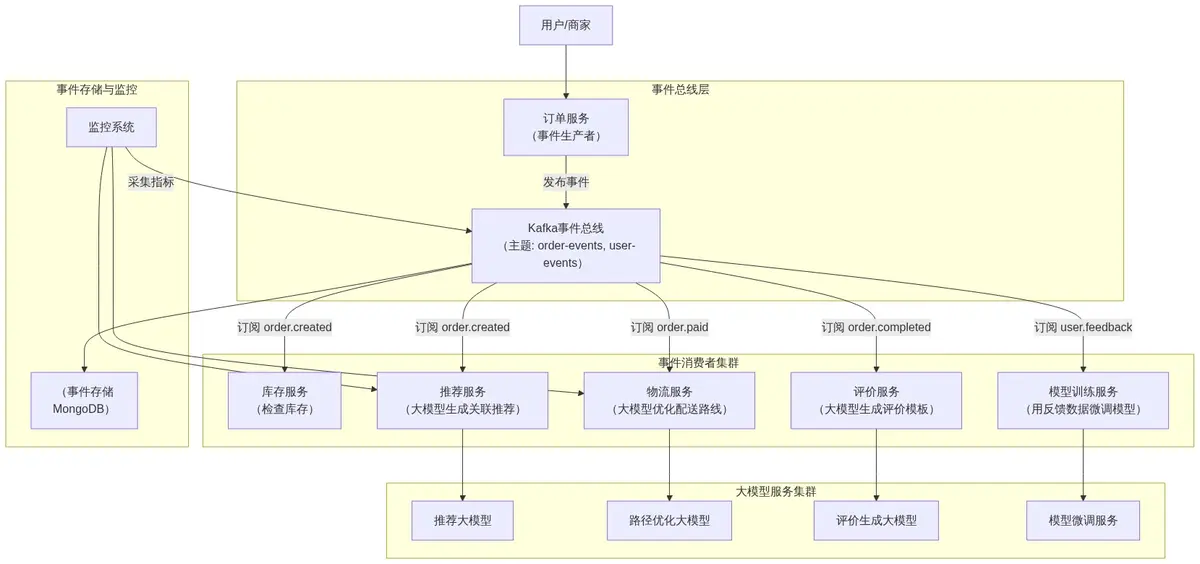
3.1 系统架构图(Mermaid可视化)
该系统包含五大事件消费者(服务),通过Kafka事件总线串联,大模型能力嵌入各环节:
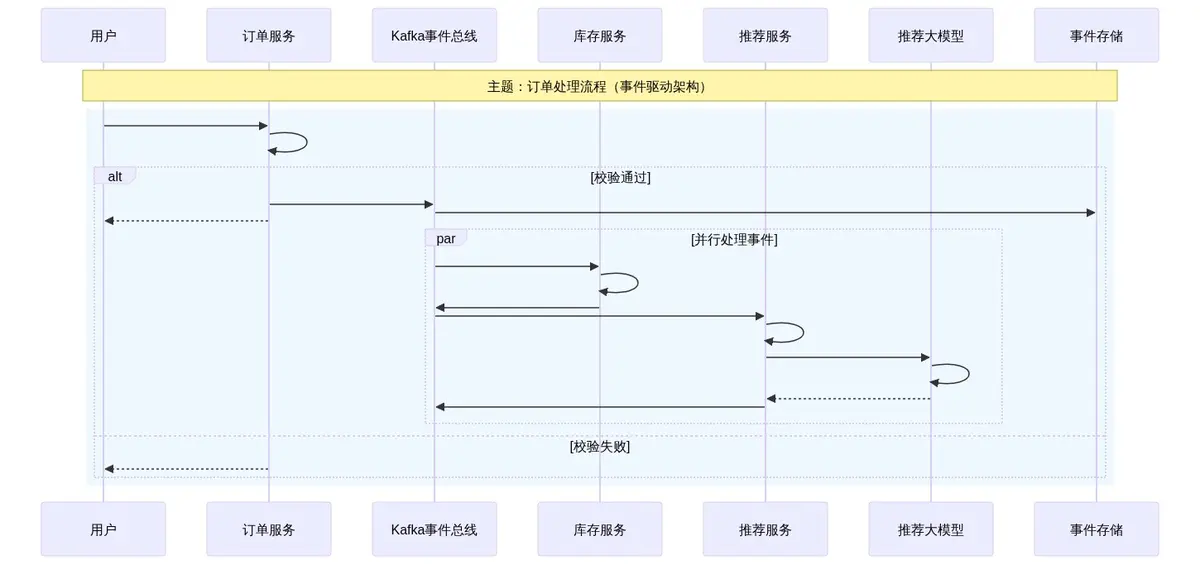
3.2 核心流程时序图:订单创建到推荐生成
用户下单后,系统自动触发库存检查和智能推荐的完整事件流(含大模型推理环节):
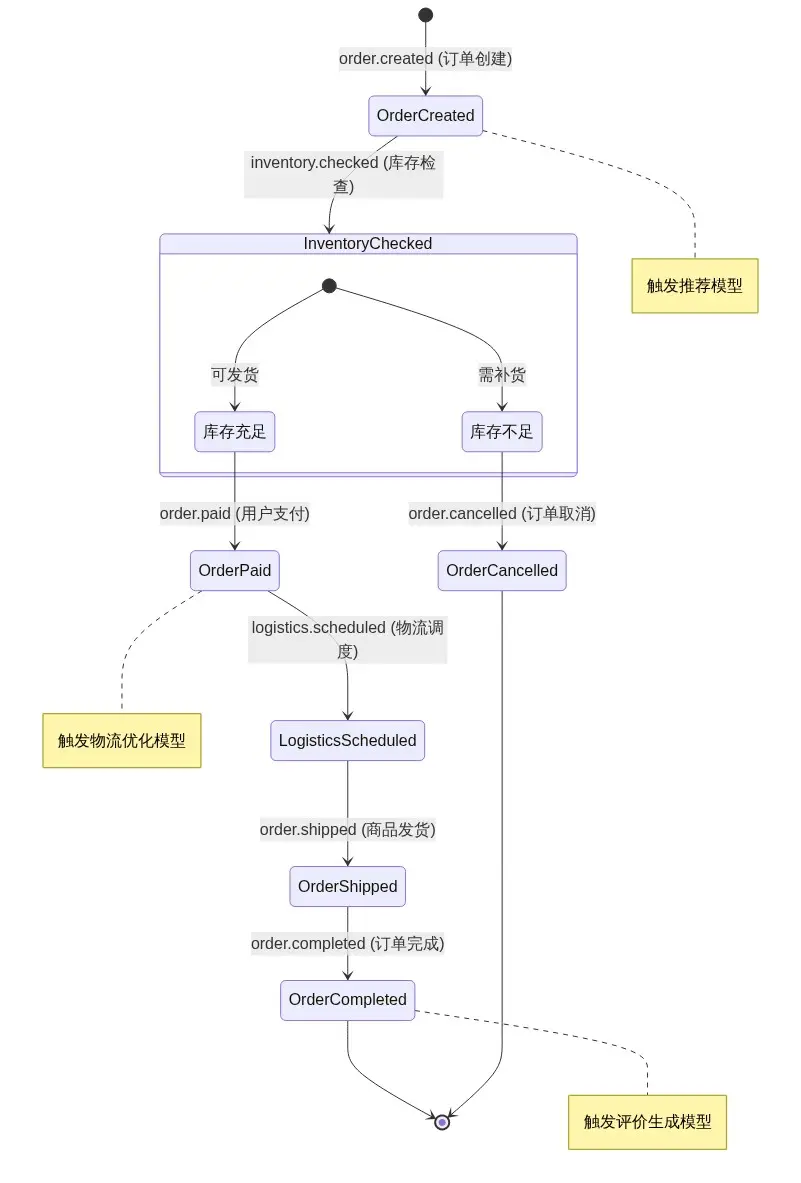
3.3 事件状态流转图:订单全生命周期
订单从创建到完成的全生命周期包含多个事件状态,每个状态变更触发不同的大模型服务:
3.4 规则引擎决策流程图:智能客服事件路由
用户咨询事件进入系统后,规则引擎根据内容动态路由到不同大模型:

3.5 关键设计解析
(1)大模型推理的异步化与优先级控制
- 异步推理:推荐服务消费“order.created”事件后,异步调用推荐模型(无需阻塞订单创建流程),推理结果通过“recommendation.generated”事件发布,前端可通过轮询或WebSocket获取;
- 优先级队列:Kafka主题按事件优先级分区(如“order-events-high”“order-events-low”),推荐模型优先处理高优先级事件(VIP用户订单),确保核心用户体验。
(2)事件溯源实现推理过程可追溯
- 完整事件链:系统记录“order.created→recommendation.request→recommendation.response→recommendation.generated”全链路事件,包含每个环节的输入输出;
- 问题定位:当用户反馈推荐结果不准确时,可通过“trace_id”查询对应事件链,检查是用户行为数据缺失(事件数据问题)还是模型版本错误(推理服务问题)。
(3)容错与幂等处理确保系统稳定
- 事件重试:推荐服务调用模型超时后,发布“recommendation.failed”事件,由重试服务消费并重试(最多3次);
- 幂等消费:推荐服务通过“event_id”判断事件是否已处理,避免重复调用模型(如Kafka因网络抖动重发事件)。
四、代码解析:事件消费者实现(推荐服务调用大模型)
以下是基于Python+Kafka的推荐服务消费者完整实现,负责订阅“order.created”事件,调用大模型生成关联推荐,并发布“recommendation.generated”事件。
4.1 核心代码实现
import json
import time
import uuid
import torch
from confluent_kafka import Consumer, Producer, KafkaError
from pydantic import BaseModel
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from typing import Dict, Any
# === 配置 ===
KAFKA_BOOTSTRAP_SERVERS = "kafka:9092"
ORDER_TOPIC = "order-events" # 订阅订单事件主题
RECOMMEND_TOPIC = "recommendation-events" # 发布推荐事件主题
GROUP_ID = "recommend-service" # 消费者组ID
MODEL_PATH = "./recommendation-model-v1" # 大模型路径
MAX_RETRIES = 3 # 事件处理重试次数
RETRY_BACKOFF = 1 # 重试退避时间(秒)
# === 数据模型 ===
class OrderCreatedEvent(BaseModel):
event_id: str
event_type: str = "order.created"
timestamp: int
source: str
data: Dict[str, Any] # 包含order_id, user_id, items等
metadata: Dict[str, Any]
class RecommendationEvent(BaseModel):
event_id: str
event_type: str = "recommendation.generated"
timestamp: int
source: str = "recommend-service"
data: Dict[str, Any] # 包含order_id, user_id, recommended_items
metadata: Dict[str, Any]
# === 大模型加载 ===
print(f"Loading model from {MODEL_PATH}...")
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
model = AutoModelForSequenceClassification.from_pretrained(
MODEL_PATH,
device_map="auto", # 自动使用GPU
torch_dtype=torch.float16 # 量化为FP16减少显存占用
)
model.eval() # 推理模式
print("Model loaded successfully")
# === Kafka消费者 ===
def create_consumer() -> Consumer:
"""创建Kafka消费者"""
consumer_config = {
"bootstrap.servers": KAFKA_BOOTSTRAP_SERVERS,
"group.id": GROUP_ID,
"auto.offset.reset": "earliest", # 从最早未消费事件开始
"enable.auto.commit": False, # 手动提交偏移量,确保事件处理完成
"max.poll.records": 10, # 每次拉取10条事件,避免处理超时
"session.timeout.ms": 6000,
"heartbeat.interval.ms": 2000
}
consumer = Consumer(consumer_config)
consumer.subscribe([ORDER_TOPIC])
return consumer
# === Kafka生产者 ===
def create_producer() -> Producer:
"""创建Kafka生产者"""
producer_config = {
"bootstrap.servers": KAFKA_BOOTSTRAP_SERVERS,
"acks": "all", # 等待所有副本确认,确保事件可靠投递
"retries": 3,
"linger.ms": 5, # 批量发送延迟,提升吞吐量
"compression.type": "lz4" # 启用压缩,减少网络传输
}
return Producer(producer_config)
def delivery_report(err, msg):
"""事件发送结果回调"""
if err is not None:
print(f"事件发送失败: {err}")
else:
print(f"事件发送成功: {msg.topic()} [{msg.partition()}]")
# === 事件处理逻辑 ===
def extract_user_preferences(event: OrderCreatedEvent) -> Dict[str, Any]:
"""从订单事件中提取用户偏好(简化示例)"""
user_id = event.data["user_id"]
items = event.data["items"]
# 实际应用中应从用户画像服务获取详细数据
return {
"user_id": user_id,
"recent_purchases": [item["product_id"] for item in items],
"preferred_categories": ["electronics", "home"] # 假设从用户画像获取
}
def call_recommendation_model(preferences: Dict[str, Any]) -> Dict[str, Any]:
"""调用推荐大模型生成关联商品"""
# 1. 准备模型输入
input_text = f"User {preferences['user_id']} purchased {preferences['recent_purchases']}. " \
f"Recommend similar items in categories: {preferences['preferred_categories']}"
inputs = tokenizer(
input_text,
return_tensors="pt",
padding=True,
truncation=True,
max_length=512
).to(model.device)
# 2. 模型推理(禁用梯度计算加速)
with torch.no_grad():
outputs = model(**inputs)
scores = torch.softmax(outputs.logits, dim=1).tolist()[0]
# 3. 模拟推荐结果(实际应用中应映射到真实商品ID)
# 这里简化为返回模拟商品ID和分数
mock_products = [f"P{1000 + i}" for i in range(10)]
return {
"user_id": preferences["user_id"],
"recommended_items": [
{"product_id": mock_products[i], "score": round(scores[i], 3)}
for i in range(5) # 返回Top5推荐
]
}
def process_order_event(event: OrderCreatedEvent, producer: Producer) -> bool:
"""处理订单创建事件,调用大模型生成推荐并发布结果事件"""
try:
# 1. 提取用户偏好
preferences = extract_user_preferences(event)
# 2. 调用推荐模型
recommendation = call_recommendation_model(preferences)
# 3. 构建推荐事件
recommend_event = RecommendationEvent(
event_id=f"recommend_{uuid.uuid4().hex[:12]}",
timestamp=int(time.time()),
data={
"order_id": event.data["order_id"],
"user_id": preferences["user_id"],
"recommended_items": recommendation["recommended_items"]
},
metadata={
"trace_id": event.metadata.get("trace_id", ""),
"model_version": "v1.2.0"
}
)
# 4. 发布推荐事件
producer.produce(
topic=RECOMMEND_TOPIC,
key=event.data["user_id"], # 按用户ID分区,确保同一用户事件顺序处理
value=json.dumps(recommend_event.dict()),
on_delivery=delivery_report
)
producer.flush()
print(f"Processed order event {event.event_id}, generated recommendation {recommend_event.event_id}")
return True
except Exception as e:
print(f"Failed to process event {event.event_id}: {str(e)}")
return False
# === 主消费循环 ===
def main():
consumer = create_consumer()
producer = create_producer()
try:
while True:
# 拉取事件(超时1秒)
msg = consumer.poll(timeout=1.0)
if msg is None:
continue # 无事件时继续轮询
if msg.error():
if msg.error().code() == KafkaError._PARTITION_EOF:
# 分区消费到末尾,正常现象
continue
else:
print(f"Consumer error: {msg.error()}")
break
# 解析事件
try:
event_data = json.loads(msg.value().decode("utf-8"))
event = OrderCreatedEvent(**event_data)
# 只处理order.created事件
if event.event_type != "order.created":
consumer.commit(msg)
continue
# 处理事件(带重试)
success = False
for attempt in range(MAX_RETRIES):
if process_order_event(event, producer):
success = True
break
if attempt < MAX_RETRIES - 1:
time.sleep(RETRY_BACKOFF * (2 ** attempt)) # 指数退避重试
if success:
consumer.commit(msg) # 处理成功后提交偏移量
else:
print(f"Failed to process event {event.event_id} after {MAX_RETRIES} retries")
except json.JSONDecodeError:
print(f"Invalid JSON format: {msg.value()}")
consumer.commit(msg) # 跳过无效消息
except Exception as e:
print(f"Error processing message: {str(e)}")
consumer.commit(msg) # 避免死循环,提交偏移量
finally:
consumer.close()
if __name__ == "__main__":
main()
代码解析:
- 组件化设计:将消费者、生产者、事件处理逻辑拆分为独立函数,便于维护;
- 可靠性保障:实现事件重试(指数退避)、手动提交偏移量、生产者消息确认(acks=all),确保事件不丢失;
- 大模型集成:通过PyTorch加载量化模型,推理时禁用梯度计算提升性能;
- 幂等处理:通过Kafka消费者组和偏移量提交,确保事件至少处理一次;
- 监控友好:详细日志输出,便于问题排查和监控告警。
五、性能优化与最佳实践
5.1 事件驱动架构性能优化手段
(1)事件处理吞吐量优化
- 批量消费:消费者一次拉取多条事件(如10-50条)批量处理,减少模型调用次数(如合并多个用户请求批量推理);
- 并行处理:同一消费者组内启动多个消费者实例,并行消费不同分区事件;
- 异步IO:使用异步HTTP客户端调用大模型服务(如aiohttp),避免阻塞事件处理线程。
(2)大模型推理延迟优化
| 优化手段 | 实现方式 | 延迟降低 | 适用场景 |
|---|---|---|---|
| 模型量化 | FP32→INT8/FP16 | 40%-60% | 所有场景 |
| 模型缓存 | 缓存高频输入的推理结果 | 80%+ | 推荐、客服等场景 |
| 预加载模型 | 消费者启动时加载模型到内存 | 消除运行时加载延迟 | 实时推理场景 |
5.2 最佳实践与避坑指南
(1)事件设计最佳实践
- 事件命名规范:采用“领域.动作”格式(如“order.created”“user.logged_in”),清晰表达事件含义;
- 事件版本控制:事件结构变更时通过版本号兼容(如“order.created.v2”),避免消费者解析失败;
- 避免超大事件:单事件大小控制在1MB以内,大文件通过对象存储引用(如事件中包含图片URL而非二进制数据)。
(2)常见问题与解决方案
| 问题 | 解决方案 | 实施效果 |
|---|---|---|
| 事件风暴(短时间大量重复事件) | 1. 事件去重;2. 合并相似事件;3. 限流保护 | 事件量减少90%,避免模型服务被压垮 |
| 消费者滞后(事件堆积) | 1. 增加消费者实例;2. 优化处理逻辑;3. 临时扩容资源 | 堆积事件从10万降至0,消费延迟从5分钟降至2秒 |
| 模型推理超时 | 1. 设置超时时间;2. 降级为轻量级模型;3. 异步重试 | 成功率从90%提升至99.9% |
六、总结
大模型应用的事件驱动架构设计,核心是通过“事件为中心的异步协作”,解决大模型多场景集成、资源利用率低、系统耦合紧的痛点。就像高效的物流系统需要标准化快递单(事件格式)、智能分拣中心(事件总线)、专业派送站点(事件消费者),大模型事件驱动架构通过六大组件的协同,实现了“按需触发、松耦合集成、全链路可追溯”的系统能力。
未来,大模型事件驱动架构将向三个方向演进:
- AI原生事件处理:事件总线内置AI能力(如自动识别事件意图、预测事件影响),实现“智能路由+自动处理”;
- 实时流处理与大模型融合:Flink/Spark Streaming等流处理引擎直接集成大模型推理能力,支持毫秒级实时分析;
- 边缘事件处理:边缘设备产生的事件在本地通过轻量级模型处理,敏感数据无需上传云端,兼顾实时性与隐私保护。
对于互联网开发者而言,掌握大模型事件驱动架构设计,不仅能提升系统的灵活性和可扩展性,更能让大模型能力像“水电”一样按需使用,在降本增效的同时加速业务创新。
附录:关键技术栈选型参考
| 组件类型 | 推荐工具 | 优势 | 适用场景 |
|---|---|---|---|
| 事件总线 | Apache Kafka | 高吞吐、持久化、分区机制 | 高并发大模型事件流(如用户行为) |
| 流处理/规则引擎 | Apache Flink | 实时计算、复杂事件处理 | 事件过滤、组合事件触发、实时特征工程 |
| 事件存储 | MongoDB | 文档模型灵活、支持复杂查询 | 存储非结构化事件数据(如用户咨询文本) |
| 大模型推理框架 | vLLM/TGI | 高吞吐量、PagedAttention优化 | 批量事件的大模型推理加速 |
| 监控工具 | Prometheus+Grafana | 时序指标监控、自定义仪表盘 | 事件吞吐量、模型推理延迟监控 |

















 1374
1374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









