







在机器学习模型训练过程中,过拟合(Overfitting)与欠拟合(Underfitting)就像两个隐藏的“陷阱”,时刻威胁着模型的实际应用效果。过拟合的模型就像一个“死记硬背”的学生,只能处理见过的题目;欠拟合的模型则如同基础薄弱的学习者,连简单问题都无法解决。本文将结合生活案例、直观图示和详细代码您深入理解过拟合与欠拟合的本质、检测方法及优化策略。
一、什么是过拟合与欠拟合?——从学生学习谈起
想象两位学生备考数学考试:
- 欠拟合学生:只掌握了基础公式,面对稍有变化的题目就束手无策,考试成绩不理想;
- 过拟合学生:记住了所有练习题的答案,但缺乏对知识点的理解,遇到新题型就无法应对。
在机器学习中:
- 欠拟合:模型未能学习到数据的内在规律,在训练集和测试集上表现均差;
- 过拟合:模型过度学习训练数据中的噪声和细节,训练集表现优异,但泛化到新数据时性能骤降。

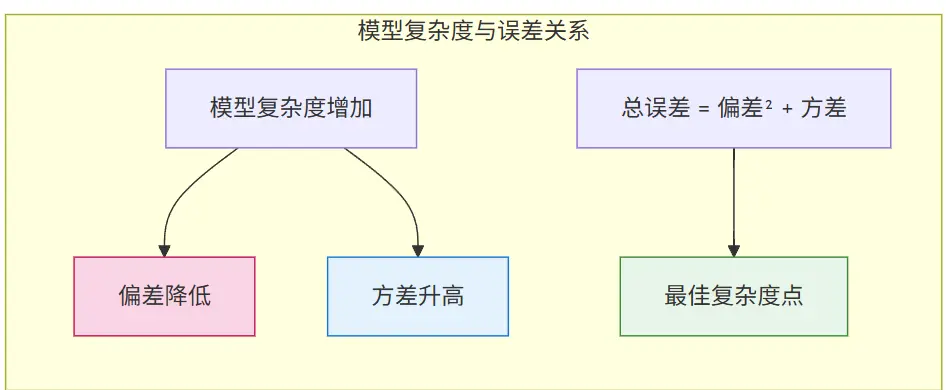
二、过拟合与欠拟合的数学原理:偏差-方差权衡
在机器学习中,预测误差可分解为:
[ 总误差 = 偏差^2 + 方差 + 噪声 ]
- 偏差(Bias):模型的预测值与真实值的偏离程度,欠拟合时偏差高;
- 方差(Variance):模型对训练数据微小变化的敏感程度,过拟合时方差高。
理想状态:在偏差和方差之间找到平衡点,使总误差最小。
三、过拟合与欠拟合的检测方法
1. 学习曲线(Learning Curve):直观诊断模型状态
学习曲线以训练样本数量为横轴,训练/测试误差为纵轴,展示模型在不同数据量下的表现。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import learning_curve
from sklearn.model_selection import ShuffleSplit
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
# 生成模拟数据
X, y = make_classification(n_samples=1000, n_features=20, random_state=42)
# 定义模型
model = RandomForestClassifier(n_estimators=10)
# 生成学习曲线数据
train_sizes, train_scores, test_scores = learning_curve(
model, X, y, cv=ShuffleSplit(n_splits=10, test_size=0.2, random_state=42),
train_sizes=np.linspace(0.1, 1.0, 10), scoring='accuracy')
# 计算平均值和标准差
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
# 绘制学习曲线
plt.figure(figsize=(10, 6))
plt.plot(train_sizes, train_mean, color='blue', marker='o', markersize=5, label='训练准确率')
plt.fill_between(train_sizes, train_mean + train_std, train_mean - train_std, alpha=0.15, color='blue')
plt.plot(train_sizes, test_mean, color='green', marker='s', markersize=5, label='测试准确率')
plt.fill_between(train_sizes, test_mean + test_std, test_mean - test_std, alpha=0.15, color='green')
plt.xlabel('训练样本数量')
plt.ylabel('准确率')
plt.title('随机森林模型学习曲线')
plt.legend(loc='lower right')
plt.show()
解读:
- 欠拟合:训练和测试曲线均处于低水平且接近;
- 过拟合:训练曲线准确率高且稳定,但测试曲线存在较大差距;
- 良好拟合:两曲线逐渐收敛且差距较小。
2. 验证曲线(Validation Curve):优化模型复杂度
验证曲线通过调整模型的某个超参数(如决策树的最大深度),观察训练/测试误差的变化。
from sklearn.model_selection import validation_curve
# 定义超参数范围
param_range = np.arange(1, 21)
# 生成验证曲线数据
train_scores, test_scores = validation_curve(
model, X, y, param_name="max_depth", param_range=param_range,
cv=ShuffleSplit(n_splits=10, test_size=0.2, random_state=42), scoring="accuracy")
# 计算平均值和标准差
train_mean = np.mean(train_scores, axis=1)
train_std = np.std(train_scores, axis=1)
test_mean = np.mean(test_scores, axis=1)
test_std = np.std(test_scores, axis=1)
# 绘制验证曲线
plt.figure(figsize=(10, 6))
plt.plot(param_range, train_mean, color='blue', marker='o', markersize=5, label='训练准确率')
plt.fill_between(param_range, train_mean + train_std, train_mean - train_std, alpha=0.15, color='blue')
plt.plot(param_range, test_mean, color='green', marker='s', markersize=5, label='测试准确率')
plt.fill_between(param_range, test_mean + test_std, test_mean - test_std, alpha=0.15, color='green')
plt.xlabel('决策树最大深度')
plt.ylabel('准确率')
plt.title('随机森林模型验证曲线(最大深度)')
plt.legend(loc='lower right')
plt.show()
解读:
- 测试曲线最高点对应的参数值为最优复杂度;
- 若测试曲线持续下降,可能存在过拟合。
四、过拟合与欠拟合的优化策略
1. 解决欠拟合:提升模型复杂度
- 增加特征:从原始数据中提取更多有价值的特征;
- 使用更复杂的模型:例如将线性模型替换为树模型或神经网络;
- 减少正则化强度:降低L1/L2正则化参数,允许模型更灵活。
2. 解决过拟合:降低模型复杂度
- 数据增强:在图像、文本等领域通过变换生成更多训练数据;
- 正则化:添加L1/L2正则项,约束模型参数;
- 早停(Early Stopping):在验证误差不再改善时停止训练;
- 集成学习:通过Bagging(如Random Forest)或Boosting(如XGBoost)降低方差。
3. 正则化示例(L2正则化)
from sklearn.linear_model import Ridge
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_regression
# 生成模拟数据
X, y = make_regression(n_samples=100, n_features=20, noise=10, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 无正则化的线性回归
model = Ridge(alpha=0) # alpha=0表示无正则化
model.fit(X_train, y_train)
train_score = model.score(X_train, y_train)
test_score = model.score(X_test, y_test)
print(f"无正则化:训练R²={train_score:.4f},测试R²={test_score:.4f}")
# 有正则化的线性回归
model = Ridge(alpha=1.0) # alpha=1.0表示使用L2正则化
model.fit(X_train, y_train)
train_score = model.score(X_train, y_train)
test_score = model.score(X_test, y_test)
print(f"有正则化:训练R²={train_score:.4f},测试R²={test_score:.4f}")
五、过拟合与欠拟合的实战案例
案例1:电商商品推荐模型
在电商平台的商品推荐系统中:
- 欠拟合表现:模型仅根据用户的少数浏览记录推荐商品,忽略用户的多样化需求,导致推荐结果单一;
- 过拟合表现:模型过度学习用户近期的购买行为,如用户偶然购买一次婴儿用品后,持续推荐母婴类商品,忽略用户的其他兴趣;
- 优化方案:通过特征工程增加用户行为特征,使用随机森林等集成模型平衡偏差和方差。
案例2:短视频内容分类模型
对于短视频平台的内容分类(如区分“美食”“旅游”类别):
- 欠拟合检测:学习曲线显示训练和测试准确率均低于60%,且曲线接近;
- 过拟合检测:训练准确率高达95%,但测试准确率仅70%,且验证曲线显示模型复杂度超过阈值后性能下降;
- 优化方案:增加训练数据量,应用Dropout技术(神经网络),调整树模型的最大深度。
六、总结与实践建议
过拟合与欠拟合是机器学习模型训练过程中的核心挑战,理解它们的本质和优化方法是成为合格AI工程师的关键一步。通过学习曲线和验证曲线,结合数据增强、正则化等技术,开发者能够有效诊断并解决模型的拟合问题。
实践建议:
- 在模型训练初期,优先使用简单模型快速验证假设,避免陷入过拟合;
- 始终使用交叉验证评估模型性能,避免测试集泄露;
- 通过可视化工具(如学习曲线)实时监控模型训练过程,及时调整策略;
- 记住“奥卡姆剃刀”原则:在性能相近的情况下,优先选择更简单的模型。
掌握过拟合与欠拟合的平衡艺术,将帮助您构建更稳定、更具泛化能力的机器学习模型!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









