




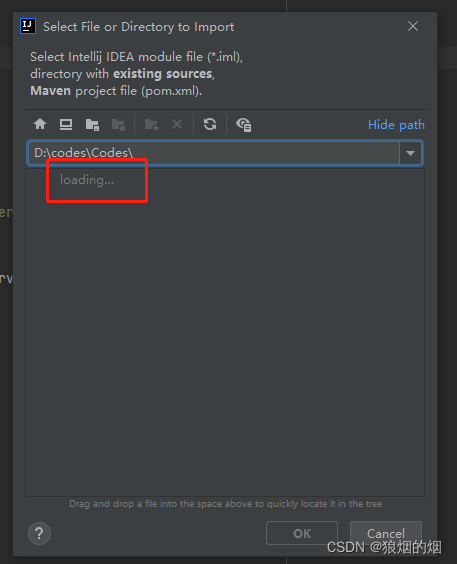
出现上面的界面大约过了十几分钟开始显示Codes下面的代码目录.
这个情况肯定是资源管理器在做什么事情.
我的问题是自己挂载了一个远程磁盘,每次涉及到应用软件在打开我的电脑的资源管理器的时候会检索远程磁盘,在远程磁盘响应慢的情况时候会出现等待时间特别长的情况
 本文描述了当资源管理器在打开包含远程磁盘的应用软件时遇到的问题,特别是远程磁盘响应较慢导致长时间等待的情况。
本文描述了当资源管理器在打开包含远程磁盘的应用软件时遇到的问题,特别是远程磁盘响应较慢导致长时间等待的情况。
出现上面的界面大约过了十几分钟开始显示Codes下面的代码目录.
这个情况肯定是资源管理器在做什么事情.
我的问题是自己挂载了一个远程磁盘,每次涉及到应用软件在打开我的电脑的资源管理器的时候会检索远程磁盘,在远程磁盘响应慢的情况时候会出现等待时间特别长的情况
 4812
2436
4812
2436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























