




 本文探讨了一系列深度学习训练技巧,这些技巧通过优化模型结构、数据预处理、损失函数及学习率策略,显著提升了图像分类任务的准确性。实验表明,组合使用这些技巧可将ResNet50在ImageNet上的top1准确率从75.3%提升至79.2%,并证实了优化后的模型在目标检测、语义分割等任务上的迁移学习表现更佳。
本文探讨了一系列深度学习训练技巧,这些技巧通过优化模型结构、数据预处理、损失函数及学习率策略,显著提升了图像分类任务的准确性。实验表明,组合使用这些技巧可将ResNet50在ImageNet上的top1准确率从75.3%提升至79.2%,并证实了优化后的模型在目标检测、语义分割等任务上的迁移学习表现更佳。
摘要:
图像分类任务当前取得的很多进展都可以归功于训练程序的优化,例如数据扩展与优化的方法。在文献中,大多数改进要不是作为实现细节简单提到,就是仅仅在源码中展现。本文中,我们会验证一系列这样的改进,并且利用切除实验的思想在实验中验证这些改进的效果。实验结果显示,通过将这些改进组合在一起可以显著的提升一些CNN模型的表现。例如,我们将RestNet50在ImageNet上的top1准确率从75.3%提升到79.2%。结果还显示出,在图像分类上准确率的优化使得在例如目标检测、分割等其他领域的应用上迁移学习的效果更好。
1、Introduction
自从2012年出现了AlexNet,图像分类的主要方法就被深度神经网络主宰了。从那时起,许多新的网络结构提了出来,包括VGG,NiN,Inception,ResNet,DenseNet,NASNet等。与此同时我们看到了模型进度持续进步的趋势。例如,ImageNet上top-1的准确率从AlexNet的62.5%上升到NASNet-A的82.7%。
但是这些进步并不单单来自模型结构的改进。训练流程的改进,包括loss函数,数据处理流程,优化方式的改进也起到了关键作用。过去这些年提出了大量的类似优化方法,但是得到的关注相对较少。在文献中,大多是仅仅作为实现细节简单带过,有些甚至只能在源码里找到。
本文中我们会实验一系列训练流程与模型结构的优化来提升模型的准确率,并基本不改变模型的计算复杂度。它们很多是不起眼的tricks例如修改特定卷积层的stridesize,修正学习率的调整计划等。然而整体来看它们创造了很大的不同。我们会在不同数据集与网络结构上评估这些tricks,并且得到它们对最终模型准确率的影响。
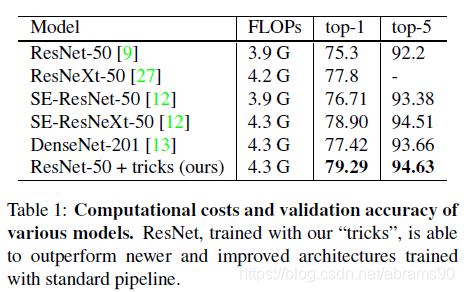
我们的实现显示一些tricks对准确率的提升起到了很大的作用,将他们级联在一起使用可以更好的提升模型的进度。我们在使用这些tricks到ResNet50后,与表1中的其他相关网络进行了对比。可以看到这些tricks将ResNet50在ImageNet上的top-1准确率从75.3%提升到79.29%。这些tricks还提升了其他更新的并且已经改进了的网络结构的下过,例如SE-ResNeXt-50。此外,我们还展示了我们的方法可以推广到其他例如Incptionv3,Mobilenet网络与其它数据集例如Place365。此外实现还展示出利用我们tricks训练出的模型在其他例如目标检测或者语义分割上的迁移学习表现更好。
论文大纲:
我们首先在第二章设定标准训练流程,然后在第三章讨论一些在新硬件上有效训练的tricks。在第四章,我们回顾三种对ResNet主要模型结构常用的微调方法,并提出一种新方法。在第五章会讨论其他四种训练流程优化方法。最后,在第六张我们会研究这些更加精确的模型会不会在迁移学习是有用。
我们模型实现与训练脚本在GluonCV上开源了。
2、训练流程
使用小批量随机梯度下降法训练神经网络的模板如Algorithm1所示。在每一次迭代中,我们随机选择b图片来计算梯度,之后更新网络权重。训练当K跑完整个数据集后停止。Algorithm1中所有的功能与超参数都可以有多种不同的方式实现。本章中,我们指定一个Algorithm1的baseline实现。

2.1 baseline训练流程
我们将广泛使用的RetNet50的实现作为我们的baseline。训练与验证阶段的处理流程是不同的。在训练阶段,我们一步一步执行以下步骤:
- 随机采样样本,将图片转成值在[0,255]间的32位浮点数。
- 随机crop矩形区域,长宽比在[3/4,4/3]范围内随机,面积随机在[8%,100%]间随机,将crop出的区域resize到224*224尺寸。
- 使用0.5的概率对样本进行水平翻转。
- 色度、饱和度、亮度统一置为[0.6,1.4]。
- 增加参数从服从
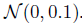 分布中采样的PCA噪声。
分布中采样的PCA噪声。 - 通过RGB通道分别减去123.68,116.779,103.939,除以58.393, 57.12,57.375进行正则化。
在验证阶段,我们将每张样本的短边resize成256大小,并保持长宽比。下一步以中间为中点,crop出一个224*224的区域,并使用相同的方法对RGB通道进行正则化。在验证阶段我们不进行任何随机数据扩展。
卷积层与全连接层的参数都使用Xavier算法进行初始化。特别的是,我们将参数统一设置为[-a,a]之间的值,这里![]() 。
。![]() 与
与![]() 分别表示输入与输出的通道大小。所有的biases都初始化为0。对于BN层,
分别表示输入与输出的通道大小。所有的biases都初始化为0。对于BN层,![]() 向量初始化为1,
向量初始化为1,![]() 向量为0。
向量为0。
NAG(Nesterov Accelerated Gradient)下降法【20】用来进行训练。每个模型都在8块V100显卡的服务器上以batchsize256训练120个epochs。初始化学习率为0.1,分别在第10、30、60、90epoch时除以10。
2.2 实验结果
我们评估了三个CNNs:ResNet50【9】,Inception-V3【1】,MobileNet【11】。对于Inception-V3我们将输入样本resize到299*299。我们使用ISLVRC2012【23】数据集,包含100类,130万样本。验证准确率如表2所示。明显看的出来,ResNet-50结果比对比结果要好,baseline的Inception-V3与MobileNet由于不同的训练流程准确率略低。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6184
6184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









