



项目简介
Python版本:python3.7+
前端:vue.js+elementui
框架:django/flask都有,都支持
后端:python
数据库:mysql
数据库工具:Navicat
开发软件:PyCharm
系统截图
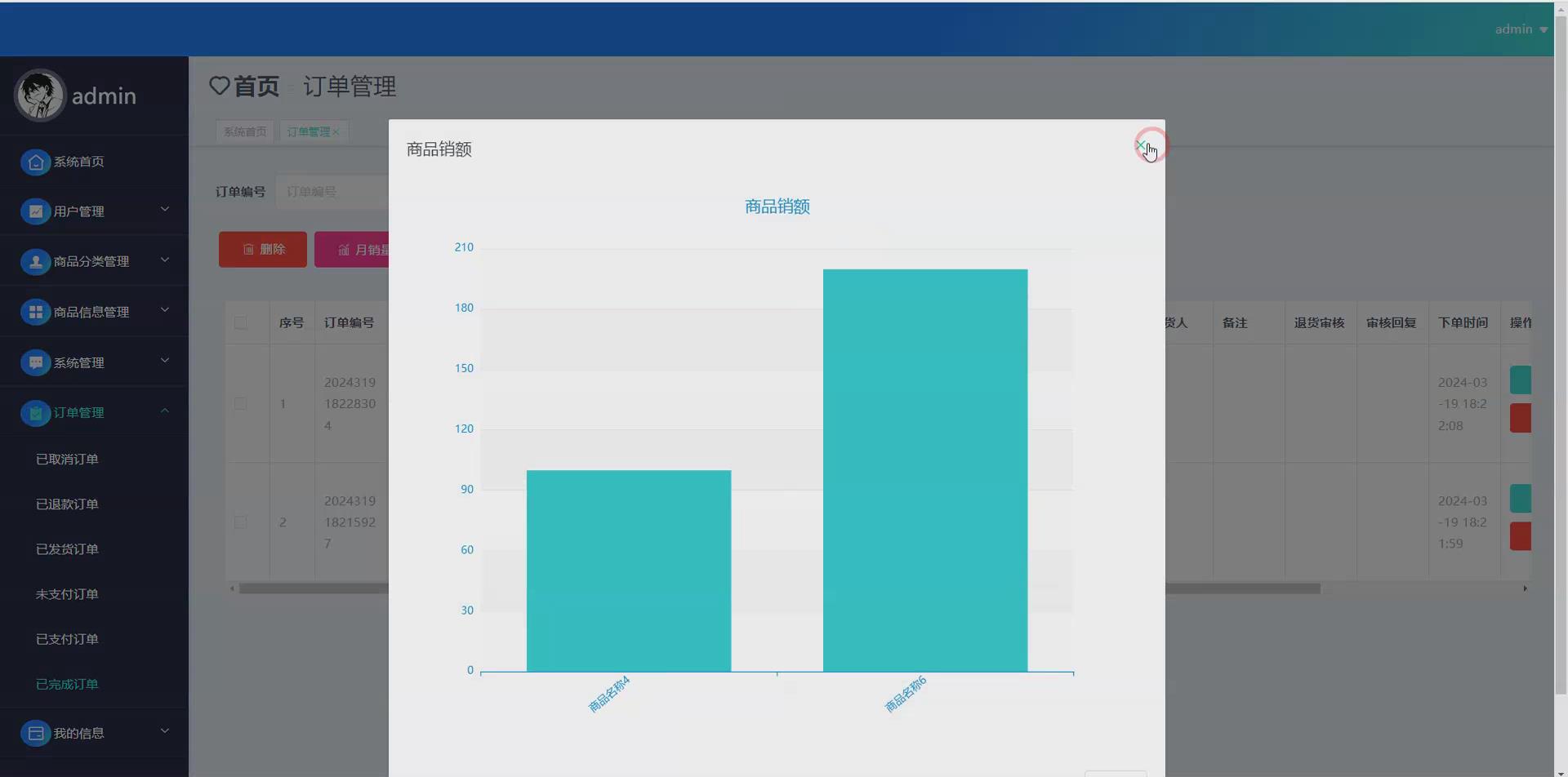
大数据系统开发流程
Scrapy作为高性能的网络爬虫框架,负责从各类目标网站上抓取数据,为系统提供丰富的数据源。Pandas则用于数据的清洗、整理和分析,它能够处理复杂的数据操作,确保数据的准确性和可靠性。在数据可视化方面,Echarts和Vue.js发挥重要作用。Echarts提供直观、生动、可交互的数据可视化图表,帮助用户更好地理解数据背后的价值;Vue.js作为一种流行的前端开发框架,为数据可视化提供了强大的支持,使界面更加友好和易用。Flask框架和django框架用于搭建系统的后端服务,提供基本的路由、模板和静态文件服务功能。MySQL数据库则用于存储和管理从爬虫获取的数据、用户信息以及分析结果等,为系统提供高效的数据存储和查询能力。
爬虫原理
基本上所有Python爬虫初学者都会接触到两个工具库,requests和BeautifulSoup,这二者作为最为常见的基础库,其使用方式也截然不同,其中request工具库主要是用来获取网页的源代码,其需要向服务器发送url请求指令;而beautifulsoup则主要用来对网页的源语言,包括且不限于HTML\xml进行读取和解析,提取重要信息。这两个库模拟了人们访问网页、阅读网页以及复制粘贴相应信息的过程,可以批量快速抓取数据。
数据清洗
数据清洗技术主要是通过使用python语言中的正则表达式技术,通过其大量收集目标数据,并进一步进行提取。2、数据转换技术主要是通过加载法,将源数据中收集到的字符串按照相应的规则和序列转换成字典。3、数据去重即用unique方法,返回没有重复元素的数组或列表。 预处理后保存到CSV文件中。
数据挖掘
数据挖掘主要是通过运用设计好的算法对已有的数据进行分析和汇总,并按照数据的特征进行情感分析。统计数据过程中多使用snownlp类库来实现这一基本的情感分析的操作,通过计算弹幕的数据值,来分析其中的倾向性。情感分析中长用sentiment来指明实际的情感值。其中,数据一旦越靠近1则越表明其正面属性,越接近0越负面,相关的结果数据可以作为情感分析的基础数据而得到。
数据可视化大屏分析
数据可视化模块主要采用饼图、词云和折线图等手段来实现最终的数据可视化。并通过matplotlib库等技术来进一步地研究和分析数据的特点,最终通过图表的模式来展示数据的深层含义。可视化模块包括各时段视频播放量比例图、热词统计图、每周不同时间视频播放量线图、情绪比例图等可视化图形。
主要运用技术介绍
Python语言
Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言,其设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有比其他语言更有特色语法结构。
Flask框架
Flask 是一个轻量级的 Web 框架,使用 Python 语言编写,较其他同类型框架更为灵活、轻便且容易上手,小型团队在短时间内就可以完成功能丰富的中小型网站或 Web 服务的实现。
Flask 具有很强的定制性,用户可以根据自己的需求来添加相应的功能,在保持核心功能简单的同时实现功能的丰富与扩展,其强大的插件库可以让用户实现个性化的网站定制,开发出功能强大的网站。
Djiango框架
MVC是众所周知的模式,即:将应用程序分解成三个组成部分:model(模型),view(视图),和 controller(控制 器)。其中:
M——管理应用程序的状态(通常存储到数据库中),并约束改变状态的行为(或者叫做“业务规则”)。
C——接受外部用户的操作,根据操作访问模型获取数据,并调用“视图”显示这些数据。控制器是将“模型”和“视图”隔离,并成为二者之间的联系纽带。
V——负责把数据格式化后呈现给用户。
B/S框架
b/s 是browser/server指浏览器和服务器端,在客户机端不用装专门的软件,只要一个浏览器即可.B/S最大的优点:客户可以在任何地方进行操作而不用安装任何专门的软件。只要有一台能上网的电脑就能使用,客户端零维护。
前台框架Vue.js
主要采用Vue技术:这是基于整个Python体系设计开发Web的技术,我们利用这一技术可以建立的动态网站是安全、先进并能跨平台
参考文献
[1]么士宇. 基于分布式计算的网络爬虫技术研究[D].大连海事大学,2025.
[2]史宝明,贺元香,吴崇正. 主题搜索引擎中爬虫搜索策略的研究[J]. 计算机工程与应用,2024.
[3]宋春颖. 基于Python的数据挖掘与分析[A]. 天津市电子学会、天津市仪器仪表学会.第三十四届中国(天津)2020’IT、网络、信息技术、电子、仪器仪表创新学术会议论文集[C].天津:天津市电子学会、天津市仪器仪表学会:天津市电子学会,2024:3.
[4]叶惠仙,游金水.Python语言在大数据处理中的应用[J].北京:网络安全技术与应用,2023(05):51-54.
[5] 迎梅.大数据挖掘关键技术的分析[J].北京:电子技术,2024,50(04):92-93.
[6] 于娟,刘强.主题网络爬虫研究综述[J].计算机工程与科学. 2025(02)
[7] 杨雨凡. 基于数据挖掘的电影票房分析[J]. 现代商贸工业,2020,41(25):42-44.
[8]陈华庆,冼远清,赖建明.网站弹幕视频数据的挖掘与分析[J].福建电脑,2019,35(08):102-103.
[9]马宁,陈曦,陈正铭.基于Python的流程自动执行关键技术研究与实现[J].电脑知识与技术,2025,15(32):77-79.
[10]蔡瑞瑞.改进K-means算法下大数据精准挖掘[J].新乡学院学报,2024,38(03):27-31.
[11]李晓朋. 基于聚类分析的高校学生综合测评成绩评价——以闽江学院X专业第一课堂、第二课堂学生成绩为例[J]. 山西青年,2024,(05):1-4.
结论
独立开发程序期间,才会发现有许多知识都是现学现用得来的,毕竟大学期间所学知识比较有限,专业知识掌握得比较浅显,这也给自己制造了许多麻烦,比如程序开发期间遇到的中文乱码问题,程序对应数据库的数据安全问题,程序开发中框架的使用问题等,这些问题都需要随时去翻阅书籍,或通过浏览器等方式寻找解决办法,这也耽误了许多程序开发的宝贵时间,后期我也通过对周边同学的请教,以及指导老师的悉心指导,让我找到了程序开发的相关技巧,也积累了一定的知识量,慢慢地纠正了许多不该犯的错误。也推动了我的程序开发进程。
源码获取联系我,文章末尾联系方式点我名片
文章下方名片联系我即可~


















 3605
3605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











