







Mybatis在生产环境,是否应该开启缓存功能
软件设计活跃区 6天前
首先,让我们来测试下Mybatis的一级缓存和二级缓存。
1. Mybatis的一级缓存测试
实验1
开启一级缓存,范围为会话级别,调用三次getStudentById,代码如下所示:
public void getStudentById() throws Exception {SqlSession sqlSession = factory.openSession(true); // 自动提交事务StudentMapper studentMapper = sqlSession.getMapper(StudentMapper.class);System.out.println(studentMapper.getStudentById(1));System.out.println(studentMapper.getStudentById(1));System.out.println(studentMapper.getStudentById(1));}
执行结果:
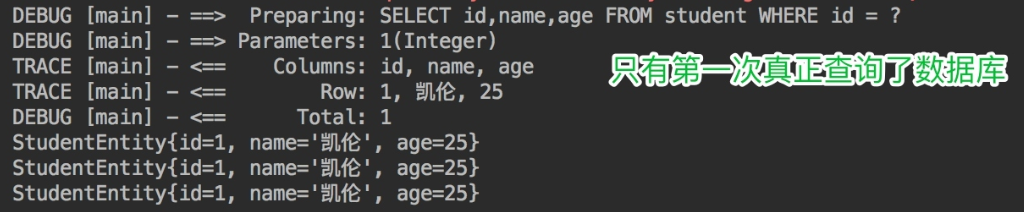
我们可以看到,只有第一次真正查询了数据库,后续的查询使用了一级缓存。
实验2
增加了对数据库的修改操作,验证在一次数据库会话中,如果对数据库发生了修改操作,一级缓存是否会失效。
在修改操作后执行的相同查询,查询了数据库,一级缓存失效。
实验3
开启两个SqlSession,在sqlSession1中查询数据,使一级缓存生效,在sqlSession2中更新数据库,验证一级缓存只在数据库会话内部共享。
@Testpublic void testLocalCacheScope() throws Exception {SqlSession sqlSession1 = factory.openSession(true);SqlSession sqlSession2 = factory.openSession(true);StudentMapper studentMapper = sqlSession1.getMapper(StudentMapper.class);StudentMapper studentMapper2 = sqlSession2.getMapper(StudentMapper.class);System.out.println("studentMapper读取数据: " + studentMapper.getStudentById(1));System.out.println("studentMapper读取数据: " + studentMapper.getStudentById(1));System.out.println("studentMapper2更新了" + studentMapper2.updateStudentName("小岑",1) + "个学生的数据");System.out.println("studentMapper读取数据: " + studentMapper.getStudentById(1));System.out.println("studentMapper2读取数据: " + studentMapper2.getStudentById(1));}
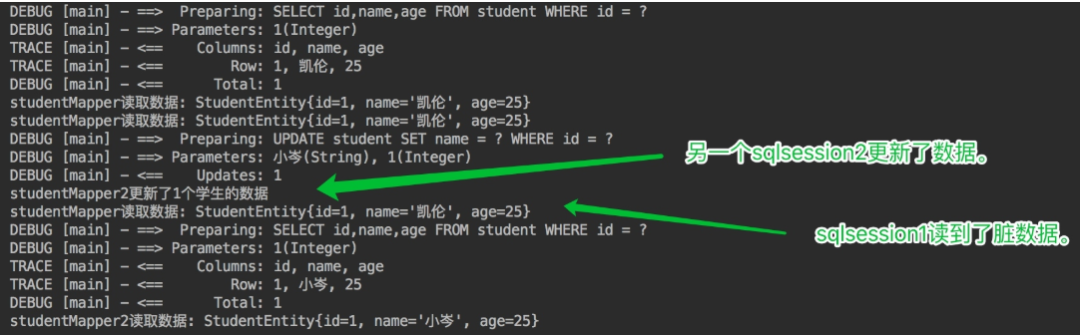
sqlSession2更新了id为1的学生的姓名,从凯伦改为了小岑,但session1之后的查询中,id为1的学生的名字还是凯伦,出现了脏数据,也证明了之前的设想,一级缓存只在数据库会话内部共享。
总结
1) MyBatis一级缓存的生命周期和SqlSession一致。每次执行update前都会清空localCache。
2) MyBatis一级缓存内部设计简单,只是一个没有容量限定的HashMap,在缓存的功能性上有所欠缺。
3) MyBatis的一级缓存最大范围是SqlSession内部,有多个SqlSession或者分布式的环境下,数据库写操作会引起脏数据,建议设定缓存级别为Statement。
(以上内容来自美团大牛的技术分享。)
2.Mybatis的二级缓存测试
二级缓存实验
接下来我们通过实验,了解MyBatis二级缓存在使用上的一些特点。
实验1
测试二级缓存效果,不提交事务,sqlSession1查询完数据后,sqlSession2相同的查询是否会从缓存中获取数据。
当sqlsession没有调用commit()方法时,二级缓存并没有起到作用。
实验2
测试二级缓存效果,当提交事务时,sqlSession1查询完数据后,sqlSession2相同的查询是否会从缓存中获取数据。
sqlsession2的查询,使用了缓存,缓存的命中率是0.5。
实验3
测试update操作是否会刷新该namespace下的二级缓存。
在sqlSession3更新数据库,并提交事务后,sqlsession2的StudentMapper namespace下的查询走了数据库,没有走Cache。
实验4
验证MyBatis的二级缓存不适应用于映射文件中存在多表查询的情况。
通常我们会为每个单表创建单独的映射文件,由于MyBatis的二级缓存是基于namespace的,多表查询语句所在的namspace无法感应到其他namespace中的语句对多表查询中涉及的表进行的修改,引发脏数据问题。
实验5
为了解决实验4的问题呢,可以使用Cache ref,让ClassMapper引用StudenMapper命名空间,这样两个映射文件对应的SQL操作都使用的是同一块缓存了。
不过这样做的后果是,缓存的粒度变粗了,多个Mapper namespace下的所有操作都会对缓存使用造成影响。
总结
MyBatis的二级缓存相对于一级缓存来说,实现了SqlSession之间缓存数据的共享,同时粒度更加的细,能够到namespace级别,通过Cache接口实现类不同的组合,对Cache的可控性也更强。
MyBatis在多表查询时,极大可能会出现脏数据,有设计上的缺陷,安全使用二级缓存的条件比较苛刻。
在分布式环境下,由于默认的MyBatis Cache实现都是基于本地的,分布式环境下必然会出现读取到脏数据,需要使用集中式缓存将MyBatis的Cache接口实现,有一定的开发成本,直接使用Redis、Memcached等分布式缓存可能成本更低,安全性也更高。
全文总结
本文对介绍了MyBatis一二级缓存的基本概念,并从应用及源码的角度对MyBatis的缓存机制进行了分析。最后对MyBatis缓存机制做了一定的总结,个人建议MyBatis缓存特性在生产环境中进行关闭,单纯作为一个ORM框架使用可能更为合适。
(以上内容来自美团大牛的技术分享。由于篇幅有限,省略了例子代码。)
3. Mybatis的缓存能在生产环境上用吗
看完,我们不禁要问,MyBatis的一级缓存那么容易读取脏数据,有实用价值吗? 每次有更改的情况,MyBatis都清空所有的一级缓存,是不是太过于一刀切了?
二级缓存,查询数据,都要使用commit提交,才能应用缓存,加大开发者的负担。namespace也需要配置声明,同时使用commit提交,查询才有可能使用上缓存。
看了全文总结,更让我们大吃一惊,居然建议"MyBatis缓存特性在生产环境中进行关闭",难道那么出名的MyBatis,连缓存功能都不能在生产环境用吗? 我们不禁会想,我们学的MyBatis,它的缓存功能只是给我们学习而矣吗? 我们花了那么多学习成本,只是为了学习而学习?
我们,最,最想知道的是,Mybatis的缓存能在生产环境上用吗? 如何你是大公司的运维,在生产环境上,你会开启Mybatis的缓存功能吗? 期待大牛的你们,给我们更多的建议!
4. 我们想要的缓存功能
我们希望ORM框架可以有如下缓存功能:
1)将查询结果放入到ORM缓存中一定时间(可由用户设置),下次查询时,缓存有值,可以从缓存获取,而不用每次都访问数据库。(如图1 有缓存功能的查询流程图 所示)
2)当有更改操作:Update, Insert,Delete,将影响到的表所对应的缓存都删除,以免查询到脏数据;但没有影响到的表的缓存不能删,以提高查询效率。
3)希望系统启动时,可以将数据库表中的一些配置信息永久放入缓存,在系统运行期间不能更改。
4)希望系统启动时,可以将数据库表中的一些配置信息加载放入缓存,数据库对应的表信息没有修改时,缓存的值一直不用刷新;但当对应表的信息有修改时,希望不用重启程序就可以拿到新的配置信息。
5)缓存容量大小可设置。
6)查询的结果集超过一定的数量时,不会放缓存,即太大了,不想放缓存。具体数量,可以由用户设置。
7)缓存容量使用率设置。添加缓存,检测达到该使用率则清除一定比例缓存。
8)有些表不想放入缓存。
如何查询数据库的数据与放在缓存的数据是一样的,缓存又没有过期,那就应该从缓存获取。分一级缓存,二级缓存,命名空间,有必要吗? 不是加重了学习成本!
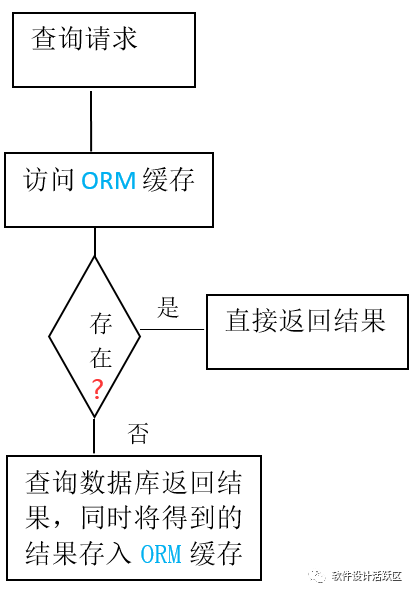
图1 有缓存功能的查询流程图
在一个新的ORM框架Bee中,实现了以上的缓存功能。并可以通过properties文件配置相关信息。详细配置文件,以下所示。更为重要的是,使用者可以感知不到缓存的存在,缓存对于他们是透明的。提供了配置的入口,但是可以不配置,使用默认配置就可以应用缓存功能;当要优化时,可根据特定场景进行优化。
#cache=======================start#缓存类型#bee.osql.cache.type=FIFO#缓存集数据量数目bee.osql.cache.map.size=100000#resultset超过一定的值将不会放缓存bee.osql.cache.work.resultSet.size=300#缓存保存时间(毫秒 ms)bee.osql.cache.timeout=180000#检测到超时,超过这个使用比例则顺便起线程清除缓存bee.osql.cache.startDeleteCache.rate=0.6#缓存容量使用率;添加缓存,检测达到该使用率则清除一定比例缓存bee.osql.cache.fullUsed.rate=0.8#添加缓存,检测到缓存容量快满时,删除缓存数的比例bee.osql.cache.fullClearCache.rate=0.2#use table name, not entity name#不缓存表的列表;#bee.osql.cache.never=user#永久缓存表的列表#bee.osql.cache.forever=constant#永久缓存,但有更改时也会清除缓存,以便同步新的值到缓存#bee.osql.cache.forever.modifySyn=para#since v1.7.2. default value is: false (use cache)#bee.osql.cache.nocache=false#cache=======================end
查询的例子,第二次可以使用上缓存。代码中,并不需要声明是使用缓存,缓存对于编程者来说是透明的。
Suid suid = BeeFactory.getHoneyFactory().getSuid();Orders orders1 = new Orders();suid.select(orders1); //selectsuid.select(orders1); //select 第二次可以使用上缓存
打印的日志,第二次查询时,提醒是从缓存中获取([Bee] ==========get from cache.)。
[Bee] select SQL:select id,userid,name,total,createtime,remark,sequence,abc,updatetime from orders[Bee] select SQL:select id,userid,name,total,createtime,remark,sequence,abc,updatetime from orders[Bee] ==========get from cache.
到这里,缓存相关的内容就介绍完了。要是想了解项目更多详细的情况,请访问文末项目首页的地址。要是有什么建议,记得告诉我们哦!
----------------------------------------
Bee简单易用:单表操作、多表关联操作,可以不用写sql,极少语句就可以完成SQL操作;10分钟即可学会使用。
Bee功能强大:复杂查询也支持向对象方式,分页查询性能更高,一级缓存即可支持个性化优化。高级需求,还可以方便自定义SQL语句。
互联网刷新了整个软件技术栈。微服务、大数据,软件需求变化快,编码量大。全新理念的ORM框架Bee, 以应对互联网时代软件需求快速变化的代码编写。Bee入门简单,使用方便,功能强大。
AI智能编程,产品原型出来,软件原型也出来了。所见的效果,所得就是可运行的代码。
用Bee+Spring+SringMVC开发JavaWeb项目效率更高。可以比原来提高至少50%。Java改善后也不懒,开发速度不比PHP慢!
用 Bee+SpringBoot+Spring Cloud开发微服务,开发效率更高!
想了解更多Bee+Spring+SpringMVC来开发JavaWeb,请关注公众号。

长按二维码可关注
更多重磅文章等着你!
https://github.com/automvc/bee
https://gitee.com/automvc/bee

----------------------------------------------
QQ群: 992650213
微信群: IT软件设计交流群3


















 793
793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









