



导读:本文是 “数据拾光者” 专栏的第一百一十三篇文章,这个系列聚焦广告行业自然语言处理与推荐系统实践。今天我们聊一个颠覆性的多模态模型 ——DeepSeek-OCR,它用 “光学压缩” 思路解决了大模型长文本处理的核心痛点,既不用堆参数也不用牺牲效果。本文会从业务痛点出发,用生活化例子拆解原理,详解模型架构与代码细节,展示实测效果,最后给出落地指南和应用场景,全程深入浅出,技术小白也能看懂~
欢迎转载,转载请注明出处以及链接,更多关于自然语言处理、推荐系统优质内容请关注如下频道。
知乎专栏:数据拾光者
公众号:数据拾光者
摘要:DeepSeek-OCR 提出 “上下文光学压缩” 新范式,将长文本渲染为图像,通过自研 DeepEncoder 压缩为少量视觉 Token,再用 MoE 解码器还原文本,彻底解决 LLM 处理长序列时的计算复杂度问题。本文先介绍它要解决的核心痛点与优化方向,再拆解 “编码器 + 解码器” 的完整架构(含核心代码解析),接着用实测数据验证其 “少 Token + 高性能” 的优势,最后分享源码使用方法和典型应用场景。无论是想了解技术原理,还是想快速落地提效,这篇文章都能给你带来启发。
01 核心痛点:LLM 处理长文本为啥 “力不从心”?
1.1 长文本处理的 “计算爆炸” 难题
做过 LLM 应用的同学都知道,大模型处理长文本时就像 “负重跑步”——Transformer 的自注意力机制计算复杂度是 O (N²),文本长度 N 翻倍,计算量就翻四倍,普通 GPU 根本扛不住。
举个生活中的例子:如果把文本 Token 比作人群,自注意力就像每个人都要和其他人握手。100 人的小群体要握 4950 次手,但 1000 人的大群体要握 499500 次手,这就是 “平方级增长” 的恐怖之处。LLM 处理长文本时,要么截断文本(丢信息),要么用复杂的稀疏注意力(难实现),很难有完美解决方案。
1.2 光学压缩:换个思路 “降维打击”
DeepSeek-OCR 的核心灵感特别简单:一张图片能承载海量文本,且视觉 Token 数远少于文本 Token 数。比如一张 A4 纸的文档,包含 2000 字文本,转化为文本 Token 大概是 1000 个,但用视觉模型处理这张图片,只需要 256 个视觉 Token 就能捕捉全部信息 —— 这就是 “光学压缩” 的本质:把一维的长文本序列,转化为二维的图像,再通过视觉编码器压缩为少量 Token,最后解码回文本。
让我们用一个生动的例子来说明:假设你有一篇3000字的文章,直接让LLM处理可能需要3000+个文本token。但如果将这篇文章渲染成图像,DeepSeek-OCR可能只需要300个视觉Token就能“看懂”并完整还原出原文——这就是10倍的压缩率!更令人惊叹的是,在这种高压缩比下,模型仍能保持97%的字符级识别精度,几乎实现了无损压缩。
1.3 DeepSeek-OCR 的三大核心优化点
- 压缩效率拉满:
用最少的视觉 Token 承载最多的文本信息,比如 100 个视觉 Token 就能解码 1000 字文本(10 倍压缩);
- 低激活内存:
处理高分辨率图像时,不会因为 Token 数多导致 GPU 显存溢出,普通 A100 就能支撑超高清文档处理;
- 多场景适配:
支持从 512×512 手机截图到超高清报纸图像的不同输入,还能解析图表、化学公式、多语言文本。
02 模型架构:DeepSeek-OCR 是如何 “压缩 + 解码” 的?
DeepSeek-OCR 的架构特别简洁,就是 “编码器 + 解码器” 的端到端设计,但每个模块都藏着巧思。整体流程:图像输入 → DeepEncoder(压缩)→ 视觉Token → MoE解码器(解码)→ 文本输出,下面逐个拆解核心模块。DeepSeek-OCR 的架构图如下所示:
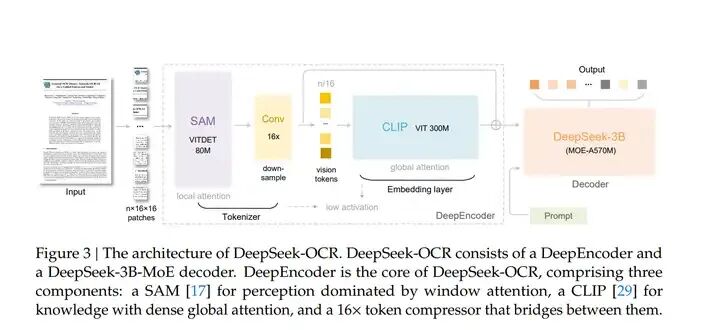
2.1 核心引擎 DeepEncoder:压缩的 “秘密武器”
介绍DeepEncoder之前,先看下当前主流的视觉编码器存在的问题。当前开源 VLM 的视觉编码器主要分为双塔架构、基于图块的方法、自适应分辨率编码三类,无法同时满足 “高分辨率处理、低激活内存、少视觉 Token” 的核心需求。

三种主流视觉编码器的详细介绍:
(1) 双塔架构(Dual-tower Architecture)
- 代表模型:Vary
- 工作原理:
采用并行的 SAM(Segment Anything Model)编码器,通过增加视觉词汇参数,适配高分辨率图像处理。
- 核心缺陷:
需执行双重图像预处理流程,大幅增加部署复杂度。
训练阶段难以实现编码器的流水线并行,限制训练效率提升。
虽能控制参数和激活内存,但工程落地成本高,不适合大规模推广。
(2)基于图块的方法(Tile-based Method)
- 代表模型:InternVL2.0
- 工作原理:
将图像分割为多个小图块(Tile),通过并行计算降低高分辨率输入下的激活内存消耗。
- 核心缺陷:
原生编码器分辨率极低(通常低于 512×512),处理大图像时会过度碎片化。
碎片化导致生成大量视觉 Token,反而增加后续推理的计算负担。
仅能适配极高分辨率场景,通用性不足,对中小分辨率图像处理效率低。
(3)自适应分辨率编码(Adaptive Resolution Encoding)
- 代表模型:Qwen2-VL(基于 NaViT 范式)
- 工作原理:
通过基于图块的分割直接处理完整图像,无需图块并行,可灵活适配不同分辨率输入。
- 核心缺陷:
处理大图像时激活内存消耗剧增,易引发 GPU 内存溢出。
训练阶段需构建极长的序列长度,增加训练难度。
长视觉 Token 会同时减慢推理的预填充(prefill)和生成(generation)阶段,降低推理速度。
三类编码器缺陷汇总表:
编码器类型 | 代表模型 | 核心优势 | 关键缺陷 |
|---|---|---|---|
双塔架构 | Vary | 参数和激活内存可控 | 双重预处理、部署复杂、不支持流水线并行 |
基于图块的方法 | InternVL2.0 | 支持极高分辨率输入 | 原生分辨率低、图像碎片化、视觉 Token 过多 |
自适应分辨率编码 | Qwen2-VL | 分辨率适配灵活 | 大图像内存溢出、训练序列过长、推理速度慢 |
正因为这三类编码器均无法平衡 “高分辨率处理、低激活内存、少视觉 Token、易部署” 四大核心需求,论文才针对性设计了 DeepEncoder—— 通过 “SAM+16× 卷积压缩器 + CLIP” 的串行架构,同时解决上述痛点,为光学压缩范式提供基础。DeepEncoder 是整个模型的灵魂,专门解决 “高分辨率输入→低 Token 输出” 的问题,由三个部分串行组成,就像一条 “压缩流水线”:
(1)第一站:SAM-base(局部特征提取)
SAM(Segment Anything Model)主要用于捕捉图像的局部细节。DeepEncoder 用的是 80M 参数的 SAM-base,输入高分辨率图像后,先把图像分割成 16×16 的小 patches(比如 1024×1024 图像会分成 64×64=4096 个 patches)。
这一步的作用就像 “显微镜观察细节”:SAM 用窗口注意力机制处理这些 patches,能精准捕捉文字的笔画、排版的间距等局部信息,而且窗口注意力的计算量可控,不会因为 patches 多就内存爆炸。
(2)第二站:16× 卷积压缩器(Token “瘦身”)
4096 个 patches 还是太多,这一步就是 “强力压缩”:用两层卷积网络对 patches 进行 16 倍下采样,把 4096 个 Token 压缩到 256 个(4096/16=256)。
卷积层的参数很简单: kernel size=3,stride=2,padding=1,通过两次下采样实现 16 倍压缩。这一步就像 “把多张照片拼成一张缩略图”,在保留核心信息的前提下,大幅减少 Token 数量。
(3)第三站:CLIP-large(全局语义整合)
CLIP-large(300M 参数)擅长捕捉全局语义,它接收压缩后的 256 个 Token,用全局注意力机制整合信息 —— 比如理解文档的整体排版、段落关系,而不只是单个文字。
这里有个小细节需要注意:CLIP 的输入不是原始图像,而是 SAM 输出的特征图,所以去掉了 CLIP 原本的 patch embedding 层,直接对接压缩后的 Token。这一步就像 “从缩略图还原整体场景”,让压缩后的 Token 包含全局语义信息。
DeepEncoder 的维度变化(以 1024×1024 图像为例):
输入图像(1024×1024)→ SAM分割 → 4096个patches(每个768维)→ 卷积压缩 → 256个Token(每个1024维)→ CLIP全局编码 → 256个视觉Token(每个1024维)
2.2 MoE 解码器:高效解码的 “聪明大脑”
解码器用的是 DeepSeek-3B-MoE(混合专家模型),这是个 “性价比之王”:
总参数 3B,但推理时只激活 64 个专家中的 6 个 + 2 个共享专家,实际激活参数只有 570M;
既拥有 3B 大模型的解码能力,又有 500M 小模型的推理速度,完美匹配 “快速解码压缩 Token” 的需求。
解码的核心公式很简单:Ŷ = f_dec(Z),其中 Z 是 DeepEncoder 输出的 n 个视觉 Token,Ŷ是解码后的 N 个文本 Token(n≤N)。这个函数 f_dec 就是 MoE 学到的 “压缩 Token→文本” 的映射关系,相当于 “把缩略图还原成完整文本”。
2.3 多分辨率模式:全场景覆盖的 “灵活切换”
不同场景的图像分辨率差异很大:手机截图可能是 512×512,论文页面是 1024×1024,报纸图像可能是 4096×2048。DeepEncoder 支持 5 种分辨率模式,能按需切换:
模式 | 原生分辨率 | 视觉 Token 数 | 适用场景 |
|---|---|---|---|
Tiny | 512×512 | 64 | 手机截图、短文本图片 |
Small | 640×640 | 100 | 普通文档、单页 PDF |
Base | 1024×1024 | 256 | 论文页面、复杂排版文档 |
Large | 1280×1280 | 400 | 高清文档、多图表页面 |
Gundam | 640+1024 | n×100+256 | 超高清图像(报纸、海报) |
Gundam-M | 1024+1280 | n×256+400 | 超大型文档(书籍扫描件) |
举个例子:处理一张报纸图像(3072×2048),Gundam 模式会把它切成 n 个 640×640 的小图块(局部视图)+1 个 1024×1024 的全局视图,Token 数 = n×100+256,既不会因为图像太大导致内存溢出,又能保留全局信息。

2.4 DeepSeek-OCR 解决传统 OCR 只认文本不认布局的痛点
OCR 1.0 数据是 DeepSeek-OCR 的核心训练素材(以文档 OCR 为主),而精细标注(fine annotations)是模型实现 “高精度文本识别 + 布局还原” 的关键。下图通过可视化样例,直观展示了这种标注的具体格式,本质是为模型提供 “文本内容→空间位置→类型标签” 的三元组监督信号,解决传统 OCR 只认文本、不认布局的痛点。

(1)标注格式的详细拆解
上图中包含两部分:(a) 原始标注图像(ground truth image)和 (b) 带布局的精细标注文本(fine annotations with layouts),核心格式是 “坐标 + 标签 + 文本” 的交织结构,每段文本都对应唯一的空间定位信息:
- 坐标信息:
标注文本在原始图像中的位置,用归一化后的四元组表示(如 [7,93,45,36])。
归一化规则:将图像的宽和高均分成 1000 个 bin(区间),坐标值范围为 0-1000,避免因图像分辨率不同导致坐标体系混乱。
举例:一张 1024×768 的文档图像,某段文本的左上角坐标 (100, 200)、右下角坐标 (300, 500),归一化后为 (98, 261, 293, 651)(计算方式:x/1024×1000,y/768×1000,四舍五入取整)。
- 标签信息:
文本的布局类型(如段落、标题、表格、公式等),用
<ref>标签包裹(如<ref>table/ef|>代表表格类型)。 - 文本内容:
对应坐标位置的原始文本,保持语义完整性(如段落文本、表格内容、公式符号等)。
(2)标注格式样例
<reftable/e|><<|dt>[57,450,30,50/et> tbe3/tt/tct/tct4/tt/tl
2.nai imbic i rt, ,1, /
reptet/reep, 15,293,53/
etet/re,515,45,54/
irepteetb, 515, 6353/
rimr iti2tj2其中第一行 <reftable/e|><<|dt>[57,450,30,50/et> 是 “表格类型” 标签 + 归一化坐标(x1=57, y1=450, x2=30, y2=50),后续内容是该表格中的文本内容,实现 “表格位置→表格内容” 的精准关联。
(3)标注格式优势
这种标注格式有以下几点优势:
- 空间信息与文本语义绑定:
模型训练时能同时学习 “文本是什么” 和 “文本在图中哪里”,后续可输出带布局的 OCR 结果(如 Markdown 格式的文档),而非单纯的纯文本。
- 适配多分辨率图像:
坐标归一化到 1000 bins 后,无论输入图像是 512×512 还是 4096×4096,坐标体系统一,模型无需额外适配不同分辨率,降低训练复杂度。
- 支撑复杂布局解析:
通过类型标签(段落、表格、公式等),模型能区分不同布局元素,为后续 “深度解析”(如表格转 HTML、公式转 SMILES)打下基础。
(4)标注数据的来源与规模
这种精细标注并非人工逐字标注,而是通过 “模型协同 + 人工校验” 的高效方式构建:
数据规模:中英文各 200 万页文档,覆盖新闻、论文、财报、教材等多种场景。
标注工具:用 PP-DocLayout(布局检测模型)识别文本位置和类型,用 MinerU、GOT-OCR2.0(高精度 OCR 模型)识别文本内容,最后人工校验错误标注(如坐标偏移、类型误判)。
minority 语言处理:对小语种文档,利用布局模型的泛化能力检测位置,用 Fitz 切割小 patch 训练专属 OCR 模型,再批量标注,最终构建 60 万条小语种精细标注数据。
(5)对模型训练的核心价值
DeepSeek-OCR 能实现 “少 Token 高精度”,离不开这种精细标注的支撑:
训练阶段:模型通过坐标和标签信息,学会 “不同布局类型的文本该如何压缩为视觉 Token”(如表格文本的 Token 分配更密集,避免信息丢失)。
推理阶段:模型能根据视觉 Token 反推文本的布局位置和类型,输出结构化结果(如将 PDF 转为带表格、公式的 Markdown 文档),而非杂乱的纯文本。
2.5 核心代码片段解析(简化版)
下面是 DeepEncoder 的核心代码简化版,主要展示模块连接关系,不用纠结复杂细节:
import torch
import torch.nn as nn
class DeepEncoder(nn.Module):
def __init__(self):
super().__init__()
# 1. SAM-base(局部特征提取)
self.sam = build_sam_vit_b() # 80M参数,输出4096个patches
# 2. 16×卷积压缩器
self.compressor = nn.Sequential(
nn.Conv2d(768, 512, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(512, 1024, kernel_size=3, stride=2, padding=1)
) # 两次下采样,16倍压缩
# 3. CLIP-large(全局语义整合)
self.clip = build_clip_l() # 300M参数,去掉patch embedding层
# 4. 特征投影层(对接解码器维度)
self.projector = nn.Linear(1024, 2560) # 映射到MoE解码器的隐藏层维度
def forward(self, x):
# x: 输入图像张量 [B, 3, H, W](比如[1, 3, 1024, 1024])
# 第一步:SAM提取局部特征
sam_features = self.sam(x) # [B, 768, 64, 64] → 4096个patches
sam_features = sam_features.permute(0, 2, 3, 1) # [B, 64, 64, 768]
# 第二步:卷积压缩(16倍下采样)
compressed = self.compressor(sam_features.permute(0, 3, 1, 2)) # [B, 1024, 16, 16]
compressed = compressed.permute(0, 2, 3, 1).flatten(1, 2) # [B, 256, 1024] → 256个Token
# 第三步:CLIP全局编码
global_features = self.clip(compressed) # [B, 256, 1024]
# 第四步:投影到解码器维度
visual_tokens = self.projector(global_features) # [B, 256, 2560]
return visual_tokens
# 解码器简化版
class MoEDecoder(nn.Module):
def __init__(self):
super().__init__()
self.moe = build_deepseek_3b_moe() # 3B MoE模型,激活570M参数
def forward(self, visual_tokens, prompt):
# prompt: 用户指令(比如"Free OCR")
# 拼接视觉Token和prompt Token
input_tokens = torch.cat([visual_tokens, prompt], dim=1)
# 解码生成文本
output_text = self.moe.generate(input_tokens)
return output_text这段代码能帮你快速理解核心逻辑:DeepEncoder 负责 “图像→视觉 Token”,MoE 解码器负责 “视觉 Token + 指令→文本”,整个流程端到端,不用额外的预处理步骤。
03 实验效果:少 Token 真能达到 SOTA 性能?
DeepSeek-OCR 的实验数据特别有说服力,核心结论就是 “用较少的 Token,达到很好的效果”。我们从两个核心数据集和实际场景来看看它的表现。
3.1 Fox 数据集:压缩率与精度的平衡
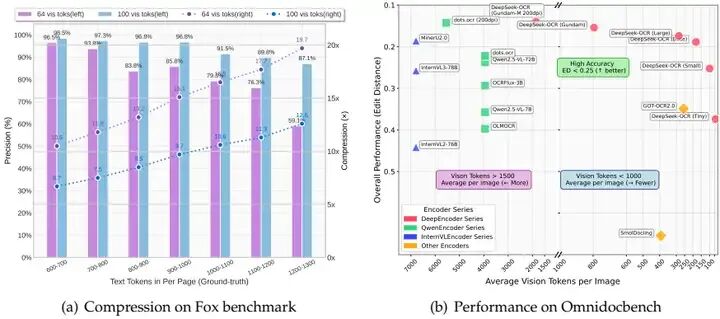
Fox 数据集主要测试 “文本 Token→视觉 Token” 的压缩 - 解码能力,选择了 600-1300 字的英文文档(文本 Token 数 600-1300),测试不同视觉 Token 数下的 OCR 精度:
文本 Token 数 | 视觉 Token=64(Tiny 模式) | 视觉 Token=100(Small 模式) |
|---|---|---|
600-700 | 精度 96.5%,压缩率 10.5× | 精度 98.5%,压缩率 6.7× |
800-900 | 精度 83.8%,压缩率 13.2× | 精度 96.8%,压缩率 8.5× |
1200-1300 | 精度 59.1%,压缩率 19.7× | 精度 87.1%,压缩率 12.6× |
关键结论:
10 倍压缩以内(文本 Token 是视觉 Token 的 10 倍),精度能达到 97% 左右,几乎是 “无损解码”—— 比如 1000 字文本用 100 个视觉 Token 解码,只有 3% 的字符误差;
即使压缩到 20 倍(1200 字文本用 64 个视觉 Token),精度还有 59.1%,对于不需要完全精准的场景(比如文本摘要、关键词提取)完全够用;
Small 模式(100Token)的精度比 Tiny 模式高很多,说明适当增加 Token 数能显著提升效果,且 Token 数仍远少于其他模型。
3.2 OmniDocBench:碾压主流模型的 “效率 - 效果” 曲线
OmniDocBench 是真实文档解析的权威基准,测试不同模型的编辑距离(越低越好)和视觉 Token 数(越少越好),DeepSeek-OCR 的表现堪称 “降维打击”:
模型 | 视觉 Token 数 | 英文编辑距离 | 中文编辑距离 |
|---|---|---|---|
GOT-OCR2.0 | 256 | 0.287 | 0.411 |
MinerU2.0 | 6790 | 0.133 | 0.238 |
DeepSeek-OCR(Small) | 100 | 0.221 | 0.284 |
DeepSeek-OCR(Gundam) | 795 | 0.127 | 0.181 |
关键结论:
Small 模式(100Token)的英文编辑距离 0.221,远超 GOT-OCR2.0(256Token,0.287)—— 用更少的 Token 实现更好的效果;
Gundam 模式(795Token)的英文编辑距离 0.127,超过 MinerU2.0(6790Token,0.133)——Token 数只有后者的 1/8,效果还略胜一筹;
对比其他大模型(比如 InternVL3-78B 用 6790Token,编辑距离 0.218),DeepSeek-OCR 用 1/8 的 Token 达到了更好的效果,效率优势巨大。
3.3 实际场景实测:不止于纯文本
DeepSeek-OCR 还支持图表、化学公式、多语言解析,实测效果如下:
图表解析:能把折线图、柱状图转化为 HTML 表格,准确率 90% 以上(比如金融报告中的数据图表,直接提取结构化数据);
化学公式:能识别 PDF 中的化学公式,转化为 SMILES 格式,支持后续化学计算;
多语言:支持近 100 种语言,包括阿拉伯语、僧伽罗语等小众语言,中文 / 英文准确率 98%+,小语种准确率 85%+;
自然图像:能解析文档中的自然图像(比如书籍中的插图),生成详细描述。
04 实践落地:如何快速上手?
4.1 环境搭建与基础调用
DeepSeek-OCR 的源码已开源(https://https://github.com/deepseek-ai/DeepSeek-OCR),下面是简化的上手步骤,新手也能快速跑通:
(1)环境搭建
# 克隆仓库
git clone https://github.com/deepseek-ai/DeepSeek-OCR.git
cd DeepSeek-OCR
# 安装依赖
pip install -r requirements.txt
# 安装torch(需匹配GPU版本)
pip install torch==2.1.0+cu118 torchvision==0.16.0+cu118(2)基础调用代码(OCR 识别)
fromdeepseek_ocrimportDeepSeekOCR
# 初始化模型(自动下载权重)
ocr=DeepSeekOCR(model_size="base")# model_size: tiny/small/base/large/gundam
# 单张图片OCR
image_path="test_document.png"# 支持PNG/JPG/PDF格式
result=ocr(image_path,prompt="Free OCR")# prompt控制输出格式
print("OCR识别结果:",result)
# 批量处理PDF(生成LLM训练数据)
pdf_path="long_document.pdf"
ocr.batch_process(
input_path=pdf_path,
output_path="ocr_train_data.jsonl",
mode="gundam",# 处理长PDF用gundam模式
batch_size=8
)
print("批量处理完成,训练数据已保存到ocr_train_data.jsonl")(3)高级功能:图表解析
# 图表解析(输出HTML表格)
chart_image = "financial_chart.png"
chart_result = ocr(chart_image, prompt="Parse the figure and convert to HTML table")
print("图表解析结果:", chart_result)
# 多语言识别(阿拉伯语文档)
arabic_image = "arabic_document.png"
arabic_result = ocr(arabic_image, prompt="Free OCR, output in Arabic")
print("阿拉伯语识别结果:", arabic_result)4.2 推荐应用场景
(1) 大规模LLM训练数据生成
DeepSeek-OCR在生产环境中每天可以处理20万+页面(单张A100-40G),是构建LLM训练数据的理想工具。传统的文档处理流程需要多个专家模型串联,而DeepSeek-OCR提供端到端的解决方案,大幅提升效率。
(2) 对话历史压缩
在多轮对话系统中,可以将历史对话渲染成“对话卷轴”图像,实现理论上的无限长对话记忆。通过调整图像分辨率,可以模拟人类的记忆衰减机制——近期对话保持高清晰度,历史对话逐渐模糊。
(3) 代码库理解与分析
将整个代码库渲染成图像,让VLM从宏观结构和微观细节两个层面理解代码。这种“代码快照”的方式比传统文本处理更能捕捉代码的空间结构和关系。
(4)历史文档数字化
对于古籍、历史档案等珍贵文档,DeepSeek-OCR的高压缩特性使得能够在保持识别精度的同时,大幅降低存储和计算成本。
4.3 高级功能:深度解析能力
DeepSeek-OCR支持“深度解析”模式,能够进一步解析文档中的图表、几何图形、化学公式等复杂内容:
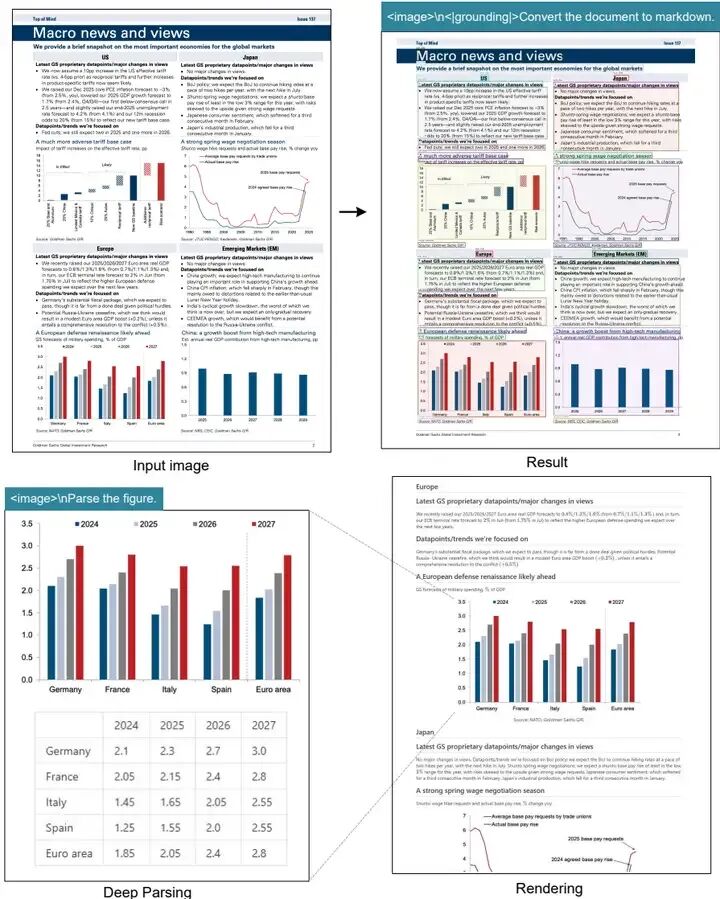
深度解析示例:
# 图表解析
chart_data = model.deep_parse(image, content_type="chart") # 输出HTML表格格式
# 化学公式识别
smiles_string = model.deep_parse(image, content_type="chemical") # 输出SMILES格式
# 几何图形解析
geometry_dict = model.deep_parse(image, content_type="geometry") # 输出结构化字典4.4 性能优化建议
选择合适的模式:短文本用 Small 模式(100Token,速度最快),长文档用 Gundam 模式(平衡速度和效果),超高清图像用 Gundam-M 模式;
批量处理提速:批量处理 PDF 时,设置 batch_size=8(A100-40G),能最大化 GPU 利用率;
显存优化:如果 GPU 显存不足,用 Tiny 模式(64Token),或启用模型量化(--load_in_8bit),显存占用减少 50%。
五、技术展望与局限性
5.1 当前局限性
尽管DeepSeek-OCR取得了突破性成果,但仍存在一些限制:
- 压缩边界:
超过10倍压缩率后性能明显下降,可能是低分辨率下图像模糊或复杂布局难以区分
- 任务泛化:
目前主要验证了OCR任务,在通用视觉问答任务上的表现有待验证
- 渲染开销:
文本到图像的渲染过程需要额外计算成本
- 非对话优化:
模型未经过指令微调,不是聊天机器人,需要通过特定提示词激活能力
5.2 未来发展方向
论文为未来研究开辟了广阔空间:
- 数字-光学文本交错预训练:
探索在LLM预训练阶段就引入光学压缩能力
- 多模态上下文管理:
将光学压缩与现有上下文窗口管理技术结合
- 自适应压缩策略:
根据内容类型动态调整压缩比率
- 跨模态检索增强:
结合压缩表示和原始文本的优势
六、总结:OCR技术的新篇章
DeepSeek-OCR代表的不仅是一项技术创新,更是一种范式转变。它没有在现有技术路线上“卷”参数或优化算法,而是提出了一个颠覆性的“光学压缩”框架来应对LLM的长上下文挑战。
核心价值总结:
- 理论创新:
提出“光学压缩”新范式,为长上下文处理提供全新思路
- 技术突破:
10倍压缩率下保持97%精度,实现近乎无损的文本压缩
- 实用性强:
在OmniDocBench上达到SOTA性能,具备大规模生产应用能力
- 开源开放:
代码模型全面开源,推动整个领域的发展
随着多模态AI技术的快速发展,DeepSeek-OCR开创的“光学压缩”思路很可能成为未来长上下文处理的标准范式之一。无论是LLM的预训练数据构建、对话系统上下文管理,还是文档智能处理,这项技术都将发挥重要作用。
对于AI从业者和研究者来说,DeepSeek-OCR不仅提供了一个强大的工具,更重要的是展示了一种跳出框架思考的创新方式——有时候,最复杂的文本问题,可以用最直观的“视觉”方式来解决。
最新最全的文章请关注我的微信公众号或者知乎专栏:数据拾光者。
码字不易,欢迎小伙伴们关注和分享。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









