






导读:本文是“数据拾光者”专栏的第七十五篇文章,这个系列将介绍在广告行业中自然语言处理和推荐系统实践。本篇主要是学习wangshusen老师的《工业界的推荐系统之涨指标》课程笔记,值得反复观看和学习反思。
欢迎转载,转载请注明出处以及链接,更多关于自然语言处理、推荐系统优质内容请关注如下频道。
知乎专栏:数据拾光者
公众号:数据拾光者
摘要:本篇主要是学习wangshusen老师的《工业界的推荐系统之涨指标》课程笔记,主要从召回、排序模型、提升多样性、特殊对待特殊人群和利用交互行为五个方面来提升推荐系统指标,分享了很多涨指标的优化实践方法,非常有借鉴价值,值得反复观看和学习反思,
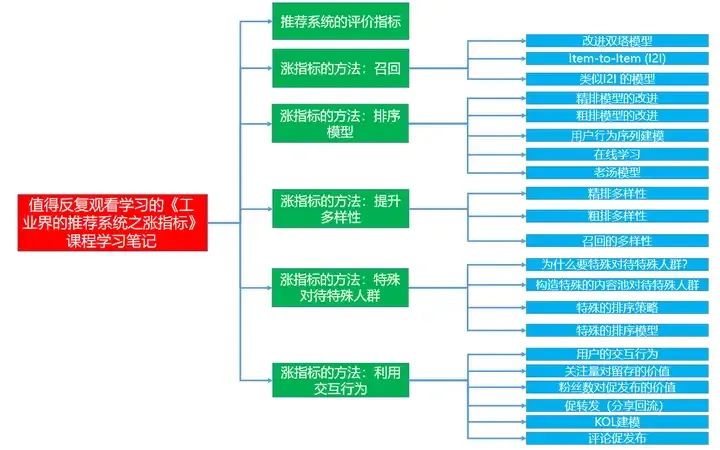
下面主要按照如下思维导图进行学习分享:
背景
最近因为业务需要在做商店召回项目,在B站刷到wangshusen老师的《工业界的推荐系统之涨指标》课程,里面干货满满。这里记录下学习笔记,方便后面反复学习实践。
01 推荐系统的评价指标


02 涨指标的方法有哪些?

2.1 涨指标的方法:召回

2.1.1 改进双塔模型
(1)优化正样本和负样本-主要优化点

因为进入排序序列,说明用户可能对物品感兴趣。但是排序靠后,说明兴趣不大,所以可以作为困难负样本。
(2)改进神经网络结构

DCN深度交叉网络。
多向量模型:
用户塔可以输出多个向量,比如点击向量、点赞向量、收藏向量和完播向量等,各自的向量维度和物品塔的维度一样。如果针对不同的目标(点击、点赞、收藏等)分别构建索引,需要构建多个向量索引库,需要多套ANN索引,特别复杂,代价太大。让物品塔只构建一个向量索引库,代价就降低很多。
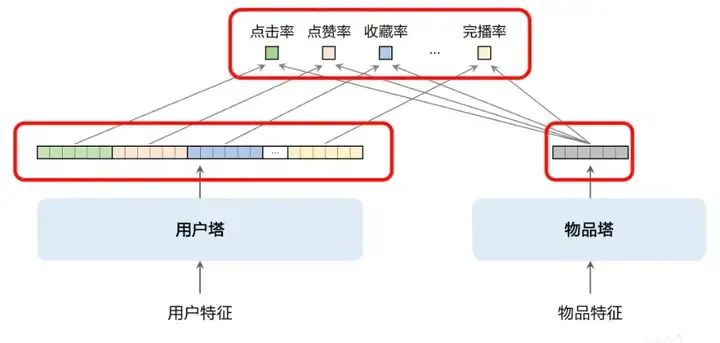
(3)改进模型的训练方法

因为冷门物品的点击数据太少,导致学习的embedding效果不好,通过自监督学习的方法可以提升效果。
2.1.2 Item-to-Item (I2I)

2.1.3 类似I2I 的模型

这些模型搭建的召回通道可能配额很小,但是对于推荐系统指标提升有一定效果。
总结:改进召回模型

2.2 涨指标的方法:排序模型

2.2.1 精排模型的改进
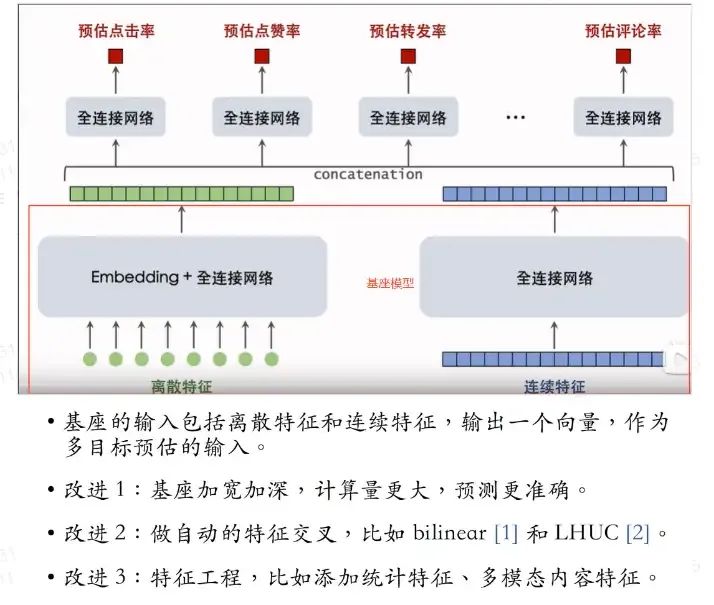
精排模型:多目标预估。

2.2.2 粗排模型的改进
改进点1:使用三塔模型(取代多向量双塔模型)

改进点2:粗精排一致性建模

2.2.3 ⽤户⾏为序列建模
用户交互过N个物品,这里取lastK个物品,得到每个物品的embedding,然后取平均得到一个embedding。

用户行为序列建模的几个改进点:

使用BERT或者CLIP来提取物品内容特征。
2.2.4 在线学习
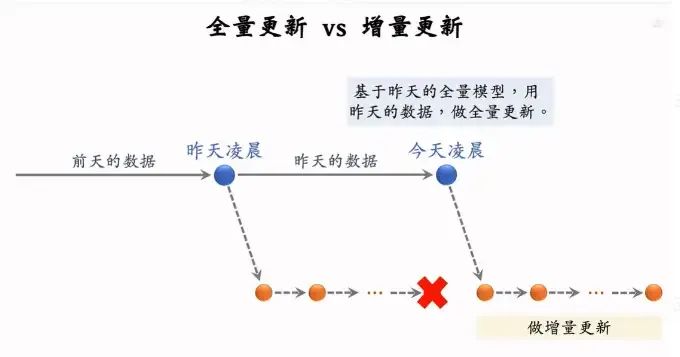
分钟级别的增量更新。虽然在线学习可以有效提升模型效果,但是会消耗资源,增加成本。


2.2.5 老汤模型

老汤模型带来的两个问题以及解决办法:


2.3 涨指标的方法:提升多样性
2.3.1 精排多样性

2.3.2 粗排多样性

2.3.3 召回的多样性
(1)添加噪声

(2)抽样用户行为序列



总结:提升多样性

2.4 涨指标的方法:特殊对待特殊人群
2.4.1 为什么要特殊对待特殊人群?

2.4.2 通过构造特殊的内容池对待特殊人群

(1)如何构造特殊内容池

(2)特殊内容池的召回

2.4.3 特殊的排序策略
(1)排除低质量物品

(2)差分化的融分方式

2.4.4 特殊的排序模型

小模型在这里起到了纠偏的作用。

错误的做法

所以不建议对每个特殊的人群都构建排序模型,最好只训练一个统一的排序模型,针对特殊人群构建小模型进行纠偏和校准。
总结:特殊对待特殊用户人群

2.5 涨指标的方法:利用交互行为
2.5.1 用户的交互行为

2.5.2 关注量对留存的价值
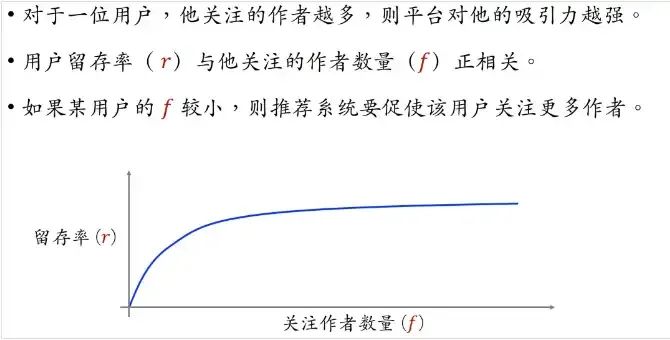

2.5.3 粉丝数对促发布的价值

通过隐式关注关系来涨粉。

2.5.4 促转发(分享回流)

2.5.5 KOL建模

方法2:构造促转发内容池和召回通道,对站外KOL生效。
2.5.6 评论促发布

总结:利用交互行为

参考资料
【1】ShusenWang的B站视频:https://space.bilibili.com/1369507485/video
【2】https://github.com/wangshusen/RecommenderSystem
最新最全的文章请关注我的微信公众号或者知乎专栏:数据拾光者。

码字不易,欢迎小伙伴们关注和分享。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









