




 本文介绍了数据库的基本概念,包括数据库的特点、主流数据库系统及其适用场景,SQL语言分类,以及数据库对象的名称长度限制等内容。
本文介绍了数据库的基本概念,包括数据库的特点、主流数据库系统及其适用场景,SQL语言分类,以及数据库对象的名称长度限制等内容。
一、基本概念
1、什么是数据库
文件存储的缺点
- 文件的安全性问题
- 文件不利于查询和对数据的管理
- 文件不利于存放海量数据
- 文件在程序中控制不方便
数据库:高效的存储和处理数据的介质(介质主要是两种:磁盘和内存)
磁盘型数据库:mysql
内存型数据库:Redis
2、理想的数据库的特征 - 充足的容量—-主要用于海量数据的存储
- 足够的安全和审核—-数据的安全存储,防止不安全行为的发生,同时还要防止免受硬件故障与自然灾害或无意的改动
- 多用户环境—-对于同时处于不同安全级别的用户是可访问的,并且要保持数据的一致性
- 效率和查找能力—–以高效的算法来处理数据(包括查询、替换等)
- 可伸缩性—-灵活,不断的适用于商业的变化与要求以及数据库的可移植性
- 用户友好—- 使得用户易于操作,非技术人员通过简单的操作也可以对其使用
3、目前主流的数据库 - SQL Sever: 微软的产品,.Net程序员的最爱,中大型项目
- Oracle: 甲骨文产品, Java程序员,大型项目,适合处理复杂的业务逻辑,对并发一般来说不如MySQL。
- MySQL:sun公司产品,现在也属于甲骨文,中型和大型项目。并发性好,不适合做复杂的业务。主要用在电商,SNS,论坛。对简单的SQL处理效果好。
- DB2:IBM公司, 处理海量数据,大型项目,功能很强悍。
- informix: IBM公司,安全非常强。
4、SQL分类
DDL 数据定义语言,用来维护存储数据的结构—–代表指令 :create,drop,alter
DML 数据操纵语言,用来对数据进行操作(表中的内容)—-代表指令:insert,delete,update
DML中又单独分了一个DQL—-代表指令:select
DCL数据控制语言,主要负责权限管理和事务—-代表指令:grant,revoke,commit
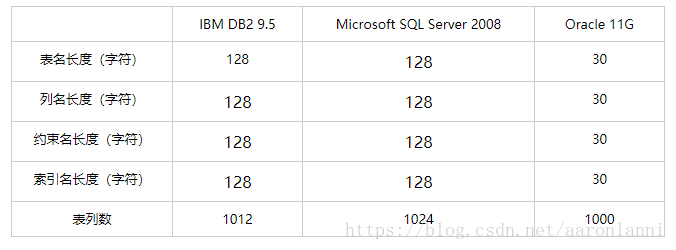
5、一些数据库对象的最大名称长度限制
二、数据库的基本使用
1、数据库的连接(可以在Windows下的cmd)
mysql [-h 主机] -u 用户 -p
说明:
如果没有写 -h 127.0.0.1 默认是连接本地
如果需要登录到另外一个mysql,则需要修改配置,一般情况不让远程登录。
2、Linux下的登录与启动
(均为root用户下)
启动:service mysqld start
关闭:service mysqld start
三、有关数据库的操作
1、基本知识
create database 库名;——>建库
use 库名;—–>使用数据库
show databases;—–>展示数据库
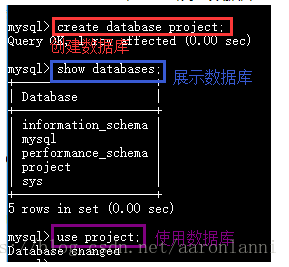
数据在数据库中的存储形式是以表的形式存在,且以行为基本单位

2、创建数据库 - 语法: CREATE DATABASE [IF NOT EXISTS] db_name(数据库名) [create_specification [, create_specification] …]
- 有关create_specification
create_specification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name - 说明:
大写的表示关键字
[] 是可选项
CHARACTER SET: 指定数据库采用的字符集(UTF-8:所有语言均支持的字符集标准)
COLLATE:指定数据库字符集的比较方式(默认utf8_ general_ ci,一般不指定)
查看系统默认字符集以及校验规则的命令为:
系统默认字符集以及校验规则的命令为:
show variables like ‘character_set_database’;
show variables like ‘collation_database’;
show variables like ‘character_set_database’;查看字符集
show variables like ‘collation_database’;查看校验规则 - 创建数据库的完整语句
create database if not exists test(数据库名)charset=utf8(设置字符集)
collate utf8_general_ci(设置校验规则);
系统默认的字符集一般是utf-8,校验规则是:utf8_ general_ ci - 查看数据库支持哪些字符集(字符集主要是控制用什么语言。比如utf8就可以装中文)
show charset; - 检验规则
校验规则:
1)区分大小写
select *from tt1 name=‘a’;//此处在查询时,如果插入“A”,”a”,在查询时查询”A”,会将两个结果都列出来。
使用utf8_ general_ ci:不区分大小写(默认校验规则)
使用utf8_bin:区分大小写
2)影响排序
select* from tt1order by name;//查询
使用utf8_ general_ ci:按照字母顺序
使用utf8_bin:按照ascii码排序
3、显示数据库创建语句
show create database 数据库名;

1) MySQL 建议我们关键字使用大写,但是不是必须的。
2) 数据库名字的反引号“,是为了防止使用的数据库名刚好是关键字
3) /!40100 default…. / 这个不是注释,表示当前mysql 版本大于4.01版本,就执行这句话。
show create database 数据库名 \G:显示数据库创建的规则

4、数据库的删除
DROP DATABASE [IF EXISTS] db_ name;(此处不区分大小写,在执行命令之时,大小写均可)
对应的数据库文件夹被删除,级联删除,里面的数据表全部被删。
5、查看当前数据库的连接情况
show processlist;

6、备份与恢复数据库
备份:os(windows下cmd) > mysqldump -u root -p -B db_name1 db _name2… > address(路径):备份数据库
os(windows下cmd) > mysqldump -u root -p -B db_name1 tab(数据库名)表名1 表名2 >(这个符号后面接路径) address(路径):备份数据库中的表
-B: 免去创建新库
sql> source 路径名
恢复:
进入mysql控制台,我们先删除原来的库。
要恢复数据库,必须先创建一个空的数据库。最好和以前的数据库名字一致。
source /root/Desktop/mytest.sql(刚才备份之后的数据库的路径) #将数据库恢复回来。
7、修改数据库
ALTER DATABASE [IF EXISTS] db_name [alter_spacification [,alter_spacification]…]
alter_spacification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name
更改字符集
alter database test charset=gdk;
更改校验规则
alter database test collate utf8_bin
对数据库的修改主要指的是修改数据库的字符集,校验规则
四、数据库的数据类型
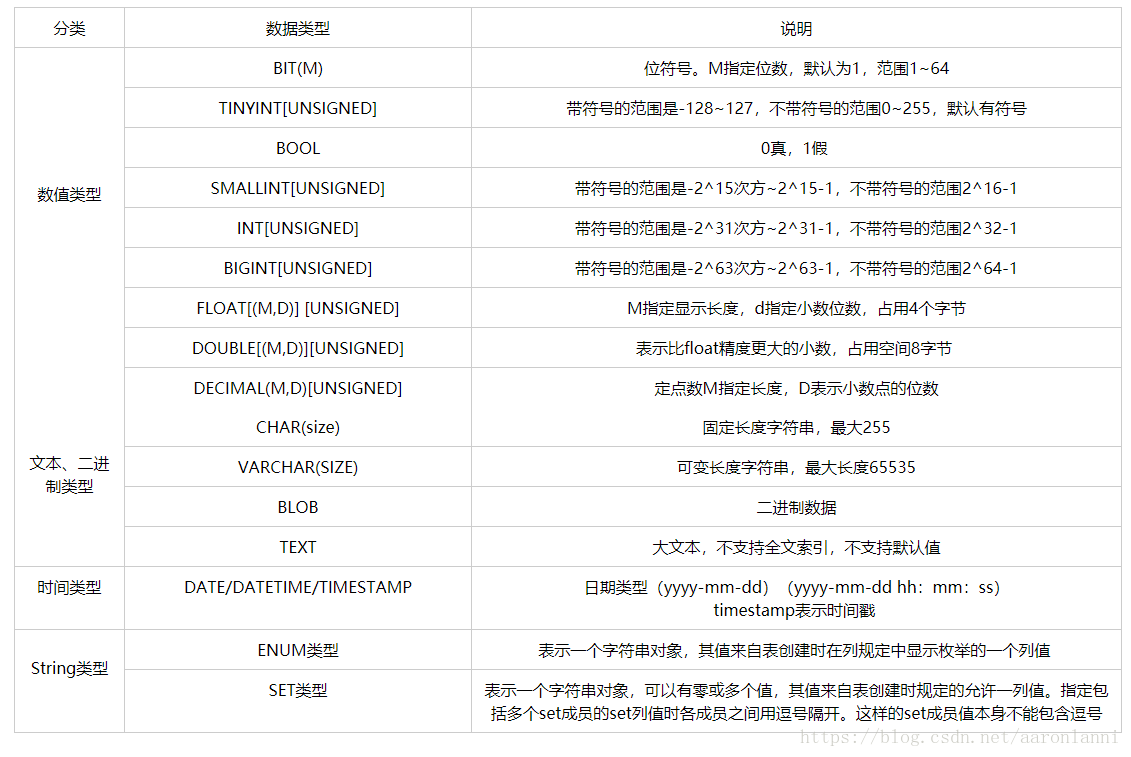
1、字符串
字符串可以被定义为某个预定义字符集的字符序列,字符串的长度就是该序列中的字符数,每个字符可以用一个或者多个字节表示,具体取决于字符所属的字符集。
长度为0的字符串称为空字符串,也可以用NULL表示
(1)固定长度字符串(char)
系统会在内存或硬盘上分配需要的字节数
char(L): 固定长度字符串,L是可以存储的长度,单位为字符,最大长度值可以为255
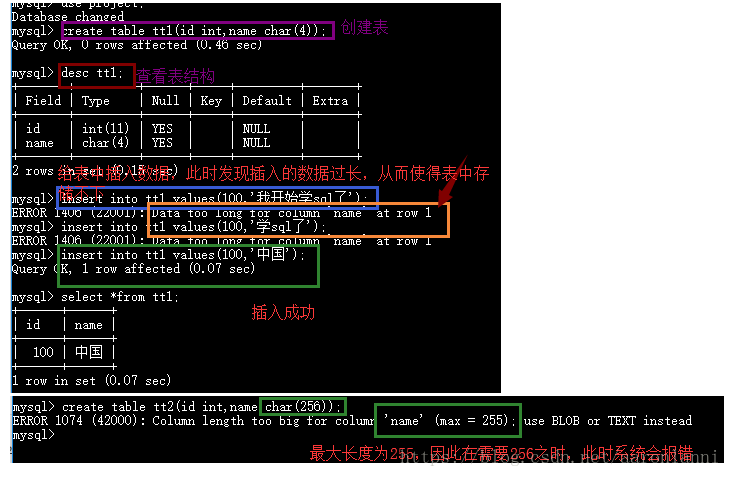
char(4) 表示可以存放两个字符,可以是字母或汉字,但是不能超过4个。最多只能是255
(2)可变长度字符串
varchar(M):不定长字符串,M表示字节,最大为65535字节
varchar(M)中M一行可最大放varchar为21844
varchar的测试同上面char类似,这里大家自己给出测试实例即可。
关于varchar(len),len到底是多大,这个len值,和表的编码密切相关:
varchar长度可以指定为0到65535之间的值,但是有1 - 3 个字节用于记录数据大小,所以说有效字节数
是65532。
当我们的表的编码是utf8时,varchar(n)n最大值是65532/3=21844[因为utf中,一个汉字占用3个字
节],如果编码是gbk,varchar(n)n最大是65532/2=32766(因为gbk中,一个汉字占用2字节)。

注意:mysql规定,一行记录的长度不能超过65535,而我们的大小4(int的大小)+21844(varchar)*3+3(用于记录数据的大小)>65535
varchar(15000):一般来说不会超过15000,超过会拖慢数据库的效率,超过之后使用text大文本类型。
char与varchar的区别
name char(4)
name1 varchar(4)//一般表示名字
name:’ab’:4*3+3=15
name1:’ab’:2*3+3=9 - 定长字符串与变长字符串的优缺点
定长字符创会造成磁盘空间浪费,但查找效率高
变成字符串节省空间,但查找效率低 - 定长与变长的使用场景
如果数据确定长度都一样,就使用定长,比如身份证,手机号,md5加密的密码… …
如果数据长度有变化,就使用变长,比如,名字,地址,但是你要保证最长的能存的进去。
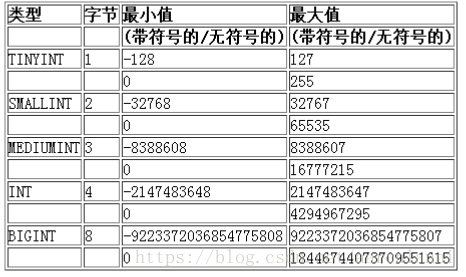
2、数值类型

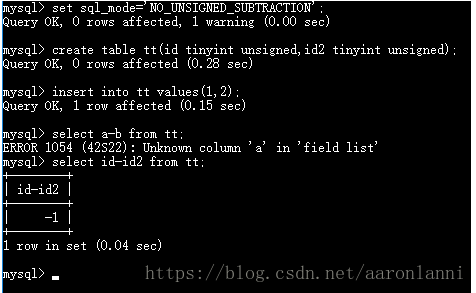
为了使得无符号数相减可以得到正确的结果,设置set sql_mode=’NO_UNSIGNED_SUBTRACTION’;不同的版本下,结果不同,5.7版本不可以设置
有关bit的使用
基本语法: bit[(M)] 位字段类型。M表示每个值的位数,范围从1到64。如果M被忽略,默认为1。

bit字段在显示时,是按照ASCII码对应的值显示。
如果我们有这样的值,只存放0或1,这时可以定义bit(1)。这样可以节省空间。
有关小数的使用 - float[(m, d)][unsigned]
M指定显示长度,d指定小数位数,占用空间4个字节,最多支持7位小数,超过精度丢失
小数:float(4,2)表示的范围是-99.99 ~ 99.99,MySQL在保存值时会进行四舍五入。如果定义的是float(4,2) unsigned 这时,因为把它指定为无符号的数,范围是 0 ~ 99.99
create table tt3(num float(5,2));表示范围(有符号-999.99~999.99) - decimal(m,d)[unsigned]:在mysql中表示小数,定点数m指定长度,d表示小数点的位数
decimal(5,2) 表示的范围是 -999.99 ~ 999.99
decimal(5,2) unsigned 表示的范围 0 ~ 999.99
decimal与float的区别:表示的精度不同,float表示小数后7位之后就看不见了,而decimal表示的精度更加准确,m最大65,d最大支持30位
建议:如果希望小数的精度高,推荐使用decimal。
3、日期类型
datetime 时间日期格式 ‘yyyy-mm-dd HH:ii:ss’ 表示范围从1000到9999,占用八字节
date:日期 ‘yyyy-mm-dd’,占用三字节
timestamp:时间戳,从1970年开始的 yyyy-mm-dd HH:ii:ss 格式和datetime完全一致,占用四字节,mysql自动添加,每当发生数据插入或者数据更新的时候,系统时间会自动更新
4、枚举和set
单选:枚举,enum(‘选项1’,’选项2’,’选项3’,…);,这些值
实际存储的是“数字”,因为这些选项,每个选项值,一次对应如下数字:1,2,3,….最多65535个;当我们添加枚举值时,也可以添加对应的数字编号
多选:set,set(‘选项值1’,’选项值2’,’选项值3’, …);每个选项值,一次对应如下数字:1,2,4,8,16,32,….最多64个;
find_in_set(“要查询的属性”,查询的列);
find_in_set(sub,str_list);
如果sub在str_list中,则返回下标,如果不在,返回0
str_list用逗号分隔的字符串。
这世上哪有什么奇迹,奇迹源于不放弃!!!

















 894
894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









