



1.打开putty,输入连接账号和密码,点击save保存以后都可以直接使用。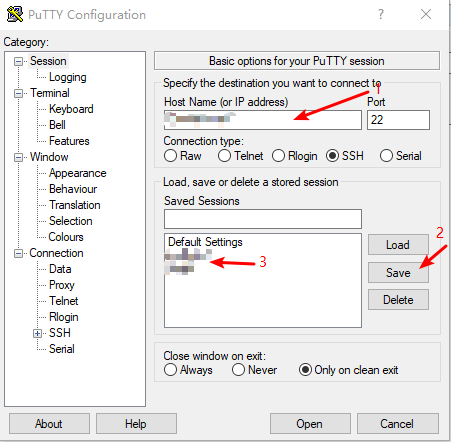
2.进入要上传的文件夹的上一层,使用git将项目上传上去:
scp -r XXX(项目名/文件夹名) username@ip:超算目录 //上传文件夹
scp XXX(文件名) username@ip:超算目录 //上传文件
3.putty进入超算项目中存在main函数的目录
如果前台运行,命令是
python main.py使用前台运行,好处是可以明显看到报错等,问题是长时间不用可能会断……
如果使用后台运行,并把log保存在main.out中:
nohup python -u main.py > main.out 2>&1 &多回车几次看有没有运行起来,如果没运行起来,即exit了,则
vim main.out查看哪里报错。
如果是没有环境,这里为了方便环境不会混淆,每个用户都创建不同的环境:
conda create -n xiaoyimin(用户名) python=3.6 pip
pip install xxx(你需要的环境)这样每次要运行之前需要先进入自己的环境:
conda activate xiaoyimin如果是楼下的超算,命令是
source activate xym否则无法使用环境。
不报错,可以实时看结果:
tail -fn 50 main.out4.如果需要停掉
top //查看端口数
kill xxx(端口数) //杀死端口

















 1703
1703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









