 OC源码学习:锁的种类、原理及问题解决
OC源码学习:锁的种类、原理及问题解决




「OC」源码学习——锁
锁的原因
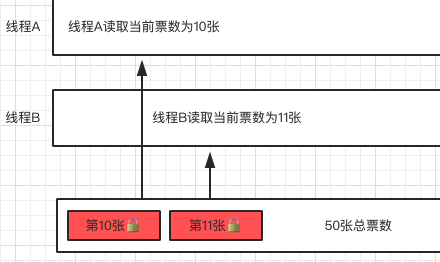
在多线程编程中,锁的作用是确保共享资源的线程安全,防止多个线程同时修改同一数据导致的数据混乱、逻辑错误甚至程序崩溃。
@interface TicketManager : NSObject
@property (nonatomic, assign) NSInteger ticketCount;
@end
@implementation TicketManager
- (void)sellTicketUnsafe {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
while (YES) {
if (self.ticketCount > 0) {
[NSThread sleepForTimeInterval:0.1]; // 模拟耗时操作
self.ticketCount--;
NSLog(@"窗口A售出1张票,剩余:%ld", self.ticketCount);
} else {
NSLog(@"票已售罄");
break;
}
}
});
dispatch_async(dispatch_get_global_queue(0, 0), ^{
while (YES) {
if (self.ticketCount > 0) {
[NSThread sleepForTimeInterval:0.1];
self.ticketCount--;
NSLog(@"窗口B售出1张票,剩余:%ld", self.ticketCount);
} else {
break;
}
}
});
}
@end
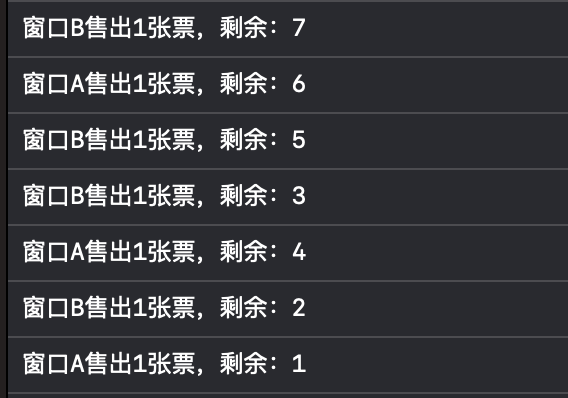
我们可以发现售出的票基本都是乱序的,也就是说访问的时候,不同线程访问同个内容出现了问题,这时候就需要锁来规范顺序
锁的种类
自旋锁
线程会反复检查变量是否可用。由于线程这个过程中一致保持执行,所以是一种忙等待。 一旦获取了自旋锁,线程就会一直保持该锁,直到显式释放自旋锁。自旋锁避免了进程上下文的调度开销,因此对于线程只会阻塞很短时间的场合是有效的。
互斥锁
互斥锁通过阻塞线程实现资源独占访问,确保临界区代码的原子性。
普通的互斥锁不支持递归,当我们在锁之中尝试重复加锁,会造成死锁。当线程首次调用lock()方法时,锁会被标记为“已占用”;若该线程未释放锁(未调用unlock())就再次调用lock(),系统会强制线程进入阻塞状态,等待锁释放。
递归锁
递归锁是特殊的互斥锁,允许同一线程多次加锁,避免嵌套死锁。
针对这种情况我们可以用 @synchronized 来解决,也可以用 NSRecursiveLock 来解决。但是 NSRecursiveLock是不支持多线程的执行
NSRecursiveLock *lock = [[NSRecursiveLock alloc] init];
// 线程1:递归加锁
dispatch_async(dispatch_get_global_queue(0, 0), ^{
static void (^block)(int);
block = ^(int value) {
[lock lock];
if (value > 0) {
NSLog(@"线程1: value=%d", value);
[NSThread sleepForTimeInterval:0.5];
block(value - 1);
}
[lock unlock];
};
block(3);
});
// 线程2:并发加锁
dispatch_async(dispatch_get_global_queue(0, 0), ^{
[lock lock];
NSLog(@"线程2: 获取锁成功");
[lock unlock];
});
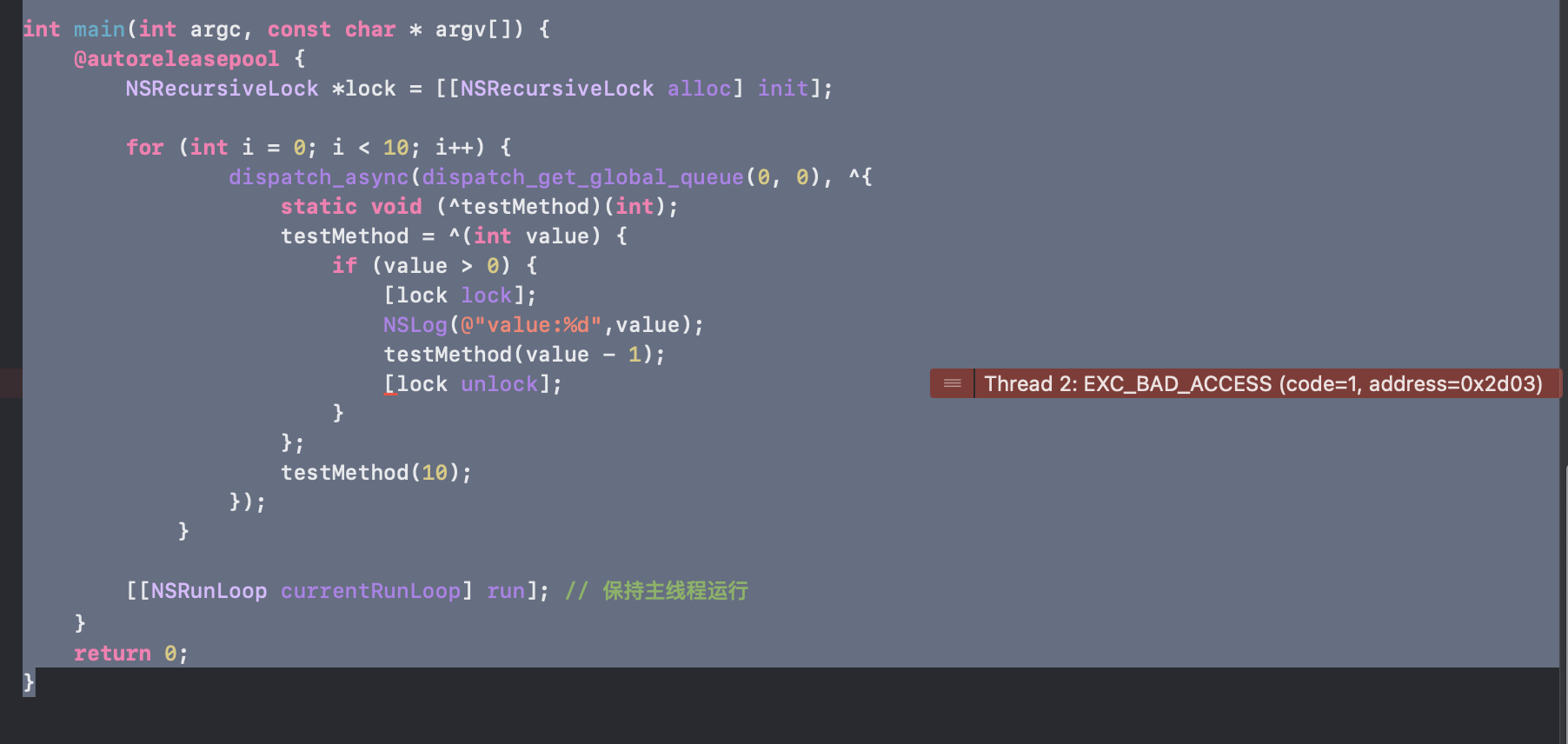
可以看到原本多线程的任务,这个代码只完成了一次
条件锁
条件锁就是条件变量,当进程的某些资源要求不满足时就进入休眠,即锁住了,当资源被分配到了,条件锁打开了,进程继续运行
@interface StageTaskExample : NSObject
@property (nonatomic, strong) NSConditionLock *conditionLock;
@end
@implementation StageTaskExample
- (instancetype)init {
self = [super init];
if (self) {
// 初始条件值为0
_conditionLock = [[NSConditionLock alloc] initWithCondition:0];
}
return self;
}
// 阶段1:初始化
- (void)stage1 {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
[self.conditionLock lock];
NSLog(@"阶段1:初始化完成");
[self.conditionLock unlockWithCondition:1]; // 解锁并设置条件值为1
});
}
// 阶段2:加载数据
- (void)stage2 {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
[self.conditionLock lockWhenCondition:1]; // 等待条件值为1
NSLog(@"阶段2:数据加载完成");
[self.conditionLock unlockWithCondition:2]; // 解锁并设置条件值为2
});
}
// 阶段3:渲染界面
- (void)stage3 {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
[self.conditionLock lockWhenCondition:2]; // 等待条件值为2
NSLog(@"阶段3:界面渲染完成");
[self.conditionLock unlock];
});
}
@end
锁的性能

synchronized原理
通过汇编语言我们可以发现,在调用@ synchronized的时候会走底层的objc_sync_enter 和 objc_sync_exit方法
objc_sync_enter
int objc_sync_enter(id obj)
{
int result = _objc_sync_enter_kind(obj, SyncKind::atSynchronize);
if (result != OBJC_SYNC_SUCCESS)
OBJC_DEBUG_OPTION_REPORT_ERROR(DebugSyncErrors,
"objc_sync_enter(%p) returned error %d", obj, result);
return result;
}
int _objc_sync_enter_kind(id obj, SyncKind kind)
{
int result = OBJC_SYNC_SUCCESS;
if (obj) {
SyncData* data = id2data(obj, kind, ACQUIRE);
ASSERT(data);
data->mutex.lock();
} else {
// @synchronized(nil) does nothing
if (DebugNilSync) {
_objc_inform("NIL SYNC DEBUG: @synchronized(nil); set a breakpoint on objc_sync_nil to debug");
}
objc_sync_nil();
if (DebugNilSync == Fatal)
_objc_fatal("@synchronized(nil) is fatal");
}
return result;
}
objc_sync_exit
int objc_sync_exit(id obj)
{
int result = _objc_sync_exit_kind(obj, SyncKind::atSynchronize);
if (result != OBJC_SYNC_SUCCESS)
OBJC_DEBUG_OPTION_REPORT_ERROR(DebugSyncErrors,
"objc_sync_exit(%p) returned error %d", obj, result);
return result;
}
int _objc_sync_exit_kind(id obj, SyncKind kind)
{
int result = OBJC_SYNC_SUCCESS;
if (obj) {
SyncData* data = id2data(obj, kind, RELEASE);
if (!data) {
result = OBJC_SYNC_NOT_OWNING_THREAD_ERROR;
} else {
bool okay = data->mutex.tryUnlock();
if (!okay) {
result = OBJC_SYNC_NOT_OWNING_THREAD_ERROR;
}
}
} else {
// @synchronized(nil) does nothing
}
return result;
}
我们从源码可以看出来,无论是进还是出,其实本质上都调用id2data
id2data
// 核心函数:根据对象和同步类型获取/创建同步数据(SyncData)
static SyncData* id2data(id object, SyncKind kind, enum usage why)
{
ASSERT(kind != SyncKind::invalid); // 同步类型有效性检查
spinlock_t *lockp = &LOCK_FOR_OBJ(object); // 获取对象关联的自旋锁指针
SyncData **listp = &LIST_FOR_OBJ(object); // 获取对象关联的SyncData链表头指针
SyncData* result = NULL; // 存储最终找到/创建的SyncData
#if ENABLE_FAST_CACHE // 快速缓存功能开关
// 步骤1:检查线程本地存储(TLS)快速缓存
bool fastCacheOccupied = NO;
SyncData *data = syncData; // TLS中缓存的SyncData指针(线程最近使用的锁)
if (data) {
fastCacheOccupied = YES;
if (data->matches(object, kind)) { // 检查对象和同步类型是否匹配
result = data;
// 有效性验证:线程计数和锁计数必须>0(防逻辑错误)
if (result->threadCount <= 0 || syncLockCount <= 0) {
_objc_fatal("id2data fastcache is buggy");
}
// 根据操作类型更新锁计数
switch(why) {
case ACQUIRE: { // 加锁操作
++syncLockCount; // 递增TLS中的嵌套锁计数
break;
}
case RELEASE: // 解锁操作
if (--syncLockCount == 0) { // 锁计数归零时清理缓存
syncData = nullptr; // 清空TLS缓存
AtomicDecrement(&result->threadCount); // 原子减少线程计数
}
break;
case CHECK: // 检查操作(无状态变更)
break;
}
return result; // 快速返回已缓存的SyncData
}
}
#endif // ENABLE_FAST_CACHE
// 步骤2:检查线程本地缓存(SyncCache)
SyncCache *cache = fetch_cache(NO); // 获取当前线程的缓存池(不自动创建)
if (cache) {
for (unsigned int i = 0; i < cache->used; i++) { // 遍历缓存条目
SyncCacheItem *item = &cache->list[i];
if (!item->data->matches(object, kind)) continue;
result = item->data;
// 有效性检查(同上)
if (result->threadCount <= 0 || item->lockCount <= 0) {
_objc_fatal("id2data cache is buggy");
}
switch(why) { // 更新锁计数逻辑
case ACQUIRE:
item->lockCount++; // 增加缓存条目中的锁计数
break;
case RELEASE:
if (--item->lockCount == 0) { // 锁计数归零时清理
cache->list[i] = cache->list[--cache->used]; // 用最后条目覆盖当前
AtomicDecrement(&result->threadCount); // 原子减少线程计数
}
break;
case CHECK:
break;
}
return result; // 返回缓存中的SyncData
}
}
// 步骤3:全局锁保护下的全局链表操作
lockp->lock(); // 获取自旋锁(防止多线程竞争)
{
SyncData* p;
SyncData* firstUnused = NULL; // 用于复用空闲SyncData节点
// 遍历全局链表查找匹配项
for (p = *listp; p != NULL; p = p->nextData) {
if (p->matches(object, kind)) { // 找到匹配的SyncData
result = p;
AtomicIncrement(&result->threadCount); // 原子增加线程计数
goto done; // 跳转到解锁和缓存处理
}
// 记录第一个未使用的SyncData(内存复用优化)
if (!firstUnused && p->threadCount == 0) firstUnused = p;
}
// 未找到且非释放/检查操作时创建新节点
if (why == ACQUIRE) {
result = firstUnused ? firstUnused : (SyncData*)posix_memalign(...); // 复用或分配内存
result->object = (objc_object *)object; // 绑定对象
result->kind = kind; // 设置同步类型
result->threadCount = 1; // 初始化线程计数
new (&result->mutex) recursive_mutex_t(fork_unsafe); // 初始化递归互斥锁
result->nextData = *listp; // 插入链表头部
*listp = result;
}
}
done:
lockp->unlock(); // 释放自旋锁
// 步骤4:缓存新获取的SyncData
if (result && why == ACQUIRE) {
#if ENABLE_FAST_CACHE
if (!fastCacheOccupied) { // 若TLS未占用则存入
syncData = result; // 存储到TLS
syncLockCount = 1; // 初始化锁计数
} else
#endif
{ // 否则存入线程缓存
if (!cache) cache = fetch_cache(YES); // 不存在则创建线程缓存
cache->list[cache->used++] = {result, 1}; // 添加新条目
}
}
return result; // 返回最终的SyncData
}
调用流程
┌──────────────────────┐
│ 调用入口 │
└──────────┬───────────┘
↓
┌──────────────────────┐
│ 第一步:TLS快速缓存查找 │
└──────────┬───────────┘
├─ 成功 → 更新 lockCount 并返回 SyncData
↓
┌──────────────────────┐
│ 第二步:SyncCache线程缓存│
└──────────┬───────────┘
├─ 成功 → 更新 lockCount 并返回 SyncData
↓
┌──────────────────────┐
│ 第三步:全局链表操作 │
└──────────┬───────────┘
├─ 创建/复用 SyncData → 更新缓存
↓
┌──────────────────────┐
│ 返回 SyncData │
└──────────────────────┘
那么TLS和程序之中的SyncCache 有什么区别呢?为什么需要先查找TLS再查找SyncCache呢?
| 维度 | TLS(线程局部存储) | SyncCache(同步缓存) |
|---|---|---|
| 存储内容 | 单个线程最近使用的锁对象(SyncData)及锁计数(lockCount) | 同一线程持有的多个锁对象(SyncData链表)及各自的锁计数 |
| 访问速度 | O(1) 直接访问(通过线程控制块快速定位) | O(n) 需遍历数组(速度稍慢但支持多锁管理) |
| 生命周期 | 与线程绑定,线程销毁时自动释放;锁计数归零时主动清理 | 锁计数归零时动态移除条目,缓存池复用SyncData节点 |
| 适用场景 | 高频单锁递归(如嵌套@synchronized) | 多锁交替使用(如循环内对不同对象加锁) |
| 数据结构 | 单条目快速缓存(仅存储最近使用的SyncData) | 动态数组(存储多个SyncCacheItem,每个条目包含SyncData指针和lockCount) |
查找步骤分析
-
TLS 快速缓存(Thread Local Storage)
- 作用:存储线程 最近一次使用的锁对象(
SyncData)及其 嵌套锁计数(lockCount)。 - 操作逻辑:
- 查找:通过
tls_get_direct获取线程绑定的SyncData。 - 匹配条件:检查
data->object是否与当前对象匹配。 - 计数更新:
- ACQUIRE(加锁):
lockCount++,更新 TLS 缓存。 - RELEASE(解锁):
lockCount--,若归零则移除 TLS 缓存并原子递减threadCount。
- ACQUIRE(加锁):
- 错误处理:若
threadCount ≤ 0或lockCount ≤ 0,触发崩溃。
- 查找:通过
- 作用:存储线程 最近一次使用的锁对象(
-
SyncCache 线程缓存
- 作用:存储线程 已持有的多个锁对象,支持多锁交替使用。
- 操作逻辑:
- 查找:通过
fetch_cache(NO)获取线程缓存池,遍历SyncCacheItem数组。 - 匹配条件:检查
item->data->object是否匹配。 - 计数更新:
- ACQUIRE:
item->lockCount++。 - RELEASE:
item->lockCount--,若归零则从数组中移除并原子递减threadCount。
- ACQUIRE:
- 查找:通过
-
全局链表与 SyncData 创建
- 数据结构:
- SyncList:全局哈希表结构,通过
sDataLists管理所有SyncData节点。 - SyncData:链表节点,含
object(锁对象)、threadCount(线程持有数)、mutex(递归锁)。
- SyncList:全局哈希表结构,通过
- 操作逻辑:
- 加锁保护:通过自旋锁
lockp->lock()确保线程安全。 - 链表遍历:查找匹配的
SyncData或首个空闲节点(firstUnused)。 - 节点创建:若未找到,通过
posix_memalign分配内存,初始化并插入链表头部。 - 缓存更新:新
SyncData存入 TLS 或 SyncCache。
- 加锁保护:通过自旋锁
- 数据结构:
| 场景 | 处理路径 |
|---|---|
| 首次加锁 | TLS → 未命中 → SyncCache → 未命中 → 全局链表创建 SyncData → 存入 TLS |
| 同一线程递归加锁 | TLS 命中 → lockCount++ |
| 不同线程访问同一锁 | TLS → 未命中 → SyncCache → 未命中 → 全局链表匹配 → threadCount++ |
synchronized的雷点
- (void)cjl_testSync{
_testArray = [NSMutableArray array];
for (int i = 0; i < 200000; i++) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
@synchronized (self.testArray) {
self.testArray = [NSMutableArray array];
}
});
}
}
我们运行代码会发现,程序会报错,我们来探究一下原因
锁对象的不稳定性(核心原因)
代码中 @synchronized 的锁对象是 self.testArray,但循环内每次异步任务都会对 self.testArray 重新赋值一个新的 NSMutableArray 实例。这导致以下问题:
- 锁对象动态变化:每个线程可能使用不同的
testArray实例作为锁对象,导致 同步失效。例如,线程A锁的是旧的array1,线程B锁的是新的array2,两者互不干扰,无法实现真正的互斥。 - 全局链表管理冲突:
@synchronized底层通过全局哈希表管理锁对象(SyncData链表)。若锁对象频繁变化,会触发大量SyncData节点的创建和销毁,导致内存管理异常或链表断裂。
解决方案
-
固定锁对象:
使用一个 独立且稳定的对象 作为锁(如self或专用NSObject实例),避免锁对象动态变化:@synchronized (self) { self.testArray = [NSMutableArray array]; } -
控制线程并发量:
改用串行队列或限制并发数(如NSOperationQueue.maxConcurrentOperationCount),避免资源耗尽。

















 895
895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









