




小样本学习系列(一):MAML代码解析
本文核心产出
参考链接
- Elegant PyTorch implementation of paper Model-Agnostic Meta-Learning (MAML) 这里的内容比较详细且模块化,但对初学者不太友好
- MAML代码踩坑 这里面的内容比较适合初学者
- Github地址https://github.com/daetz-coder/Pytorch-MAML-Tutorial
一、Omniglot数据生成
这部分不是本文的关键,这里简单介绍一下,这里面按照如下两种方式进行数据加载
- 如果你只是希望了解一下MAML的执行过程,可以直接random一个npy出来(好处就是不需要下载数据集),用于数据加载,代码实例如下
import numpy as np
import os
# 定义 Omniglot 数据集的尺寸参数
num_classes = 1623 # 总类别数
samples_per_class = 20 # 每个类别的样本数
img_height, img_width = 28, 28 # 图像尺寸
# 随机生成数据
omniglot_data = np.random.randint(0, 256, size=(num_classes, samples_per_class, 1, img_height, img_width), dtype=np.uint8)
# 保存路径
save_path = './data/omniglot.npy'
# 保存数据
np.save(save_path, omniglot_data)
save_path
import numpy as np
# 加载数据
data_path = './data/omniglot.npy'
data = np.load(data_path)
# 获取数据占用的内存大小,单位为字节
memory_size_bytes = data.nbytes
memory_size_mb = memory_size_bytes / (1024**2)
print(f"The memory size of the data is: {memory_size_bytes} bytes")
print(f"The memory size of the data is: {memory_size_mb} MB")
The memory size of the data is: 25448640 bytes
The memory size of the data is: 24.26971435546875 MB
- 【推荐】使用omniglot数据,你需要访问https://github.com/brendenlake/omniglot选择images_background.zip和
images_evaluation.zip下载即可,如果无法访问可通过如下链接访问
百度网盘链接: https://pan.baidu.com/s/1IN5WExnkwF2PY_Xj90lyuA?pwd=2024
接下来进行解压缩和生成npy文件
!unzip ./images_background.zip
!unzip images_evaluation.zip
import os
def count_files_and_directories(root_dirs):
total_files = 0
total_directories = 0
level_one_directories = 0
level_two_directories = 0
for root_dir in root_dirs:
# 初始化用于标识目录层级的计数器
current_level_dirs = {}
for root, dirs, files in os.walk(root_dir):
if root == root_dir:
# 当前是根目录,这里的子目录是一级目录
level_one_directories += len(dirs)
for d in dirs:
current_level_dirs[os.path.join(root, d)] = 1
elif root in current_level_dirs:
# 当前是二级目录
level_two_directories += len(dirs)
# 更新二级目录的标识
for d in dirs:
current_level_dirs[os.path.join(root, d)] = 2
total_directories += len(dirs)
total_files += len(files)
return total_files, total_directories, level_one_directories, level_two_directories
# 指定要遍历的根目录列表
root_directories = ['images_background', 'images_evaluation']
files_count, directories_count, level_one_count, level_two_count = count_files_and_directories(root_directories)
print(f"Total directories: {directories_count}")
print(f"Total files: {files_count}")
print(f"Level one directories: {level_one_count}")
print(f"Level two directories: {level_two_count}")
Total directories: 1673
Total files: 32460
Level one directories: 50
Level two directories: 1623
最后注意检查一下这个Level two directories: 1623是否是1623个类型,如果没问题进行npy文件的生成
import os
import numpy as np
from PIL import Image
def load_images_to_numpy(root_dirs, img_size=(28, 28)):
data = []
categories = []
for root_dir in root_dirs:
# 遍历每个字母表
for alphabet_dir in sorted(os.listdir(root_dir)):
alphabet_path = os.path.join(root_dir, alphabet_dir)
# 遍历每个字母表中的字符
for character_dir in sorted(os.listdir(alphabet_path)):
character_path = os.path.join(alphabet_path, character_dir)
character_images = []
# 确保路径指向的是文件
for img_file in sorted(os.listdir(character_path)):
img_path = os.path.join(character_path, img_file)
if os.path.isfile(img_path):
# 加载图像,转换为灰度并调整大小
with Image.open(img_path) as img:
img = img.convert('L').resize(img_size)
img_array = np.array(img)
character_images.append(img_array[np.newaxis, :, :]) # 添加新的轴以表示通道
if len(character_images) == 20:
data.append(character_images)
categories.append(character_dir)
# 转换为 numpy 数组: (类别数, 每类样本数, 通道数, 高, 宽)
data = np.array(data)
return data, categories
# 指定要遍历的根目录列表
root_directories = ['images_background', 'images_evaluation']
image_data, image_categories = load_images_to_numpy(root_directories)
# 保存为 .npy 文件
np.save('omniglot_data.npy', image_data)
print(f"Data saved with shape {image_data.shape}")
二、MAML代码解析
0、前言
- 本实验对硬件环境要求较低,笔者使用cpu(GPU也可)2G内存即可满足要求(5way 1-shot)
1、数据划分
import torch
import numpy as np
import os
root_dir = './data/'
img_list = np.load(os.path.join(root_dir, 'omniglot_data.npy')) # (1623, 20, 1, 28, 28)
x_train = img_list[:1200]
x_test = img_list[1200:]
num_classes = img_list.shape[0]
datasets = {'train': x_train, 'test': x_test}
这里是选择前1200个类型用于训练集的数据,后续的类型用于测试集
2、参数定义
### 准备数据迭代器
n_way = 5 ## N-way K-shot在广义上来讲N代表类别数量,K代表每一类别中样本数量
# n_way 定义了每个分类任务涉及的类别数。在 N-way K-shot 任务中,这意味着每个任务需要分类的不同类别数为 5。
k_spt = 1 ## support data 的个数
# k_spt 定义了每个类别在支持集中的样本数量。在这里,每个类别有 1 个样本用于训练模型。
k_query = 15 ## query data 的个数
# k_query 定义了每个类别在查询集中的样本数量。在这里,每个类别有 15 个样本用于测试模型在学习后的表现。
imgsz = 28
# imgsz 设置图像的大小,这里图像的尺寸为 28x28 像素。这通常对应于处理的图像数据的分辨率。
resize = imgsz
# resize 通常用于调整图像数据的大小到一个标准的分辨率,这里直接设为 imgsz,意味着不改变原始尺寸。
task_num = 8
# task_num 定义了每次迭代生成的任务数量。在元学习中,这意味着每次训练迭代中将处理 8 个不同的 N-way K-shot 任务。
# 需要注意的是这里面的一个Task既包含了支持集也包含了查询集
batch_size = task_num
# batch_size 设置为 task_num,意味着每个批次处理的任务数量与 task_num 相等。这在训练元学习模型时,每个批次将包含 8 个任务。
# 在元学习中的batch_size、epoch、迭代次数与常见的有些区别(后续会分析)
indexes = {"train": 0, "test": 0}
# `indexes` 字典存储了用于训练集和测试集的当前索引,初始化为0。这些索引可以用来控制从数据集中获取批次数据的位置。后续通过indexes[mode]来获取当前模式的索引。
datasets = {"train": x_train, "test": x_test}
# `datasets` 字典将字符串键 "train" 和 "test" 映射到相应的数据集。x_train 是训练数据集,x_test 是测试数据集。
# 这样设置允许代码以统一的方式通过键访问这些数据集,便于在训练和测试过程中加载数据。
print("DB: train", x_train.shape, "test", x_test.shape)
3、数据加载缓存
def load_data_cache(dataset):
"""
Collects several batches data for N-shot learning
:param dataset: [cls_num, 20, 84, 84, 1]
:return: A list with [support_set_x, support_set_y, target_x, target_y] ready to be fed to our networks
"""
# 定义单个支持集和查询集的大小
setsz = k_spt * n_way # 每个类支持集样本数 * 类数
querysz = k_query * n_way # 每个类查询集样本数 * 类数
data_cache = []
# 预加载10个批次的数据,感觉这里的10个批次数据是为了减少数据加载时间
for sample in range(10):
x_spts, y_spts, x_qrys, y_qrys = [], [], [], []
for i in range(batch_size): # 每一个批次都包含多个Task
x_spt, y_spt, x_qry, y_qry = [], [], [], []
selected_cls = np.random.choice(dataset.shape[0], n_way, replace=False) # 随机选择n_way个类
for j, cur_class in enumerate(selected_cls): #生成一个Task 包含n_way个类别 k_spt + k_query
selected_img = np.random.choice(20, k_spt + k_query, replace=False) # 从每个选中的类中随机选择图片
# 构建支持集和查询集
x_spt.append(dataset[cur_class][selected_img[:k_spt]]) # 支持集图片
x_qry.append(dataset[cur_class][selected_img[k_spt:]]) # 查询集图片
# 从当前类别cur_class中选择前k_spt个图像作为支持集的图像,支持集和查询集的类型是一致的,
# 这里选择前k_spt作为spt,剩下的作为query。
y_spt.append([j for _ in range(k_spt)]) # 支持集标签
y_qry.append([j for _ in range(k_query)]) # 查询集标签
# 列表推导式(List Comprehension):[j for _ in range(k_spt)] 生成一个长度为 k_spt 的列表,其中每个元素都是 j。
# 这里 j 是当前类别的索引,用于标记支持集和查询集的标签。
# 批内随机打乱支持集和查询集
perm = np.random.permutation(n_way * k_spt)
# 生成随机索引(perm):np.random.permutation(n_way * k_spt) 生成一个从 0 到 n_way * k_spt-1 的随机序列,
# 这里 n_way 是类别数,k_spt 是每个类别在支持集中的样本数。这个随机序列用于重新排列支持集中的样本。
x_spt = np.array(x_spt).reshape(n_way * k_spt, 1, resize, resize)[perm]
y_spt = np.array(y_spt).reshape(n_way * k_spt)[perm]
perm = np.random.permutation(n_way * k_query)
x_qry = np.array(x_qry).reshape(n_way * k_query, 1, resize, resize)[perm]
y_qry = np.array(y_qry).reshape(n_way * k_query)[perm]
# 将支持集和查询集添加到对应的列表中
x_spts.append(x_spt)
y_spts.append(y_spt)
x_qrys.append(x_qry)
y_qrys.append(y_qry)
# 将收集的数据转换为适合网络输入的形状
x_spts = np.array(x_spts).astype(np.float32).reshape(batch_size, setsz, 1, resize, resize)
y_spts = np.array(y_spts).astype(np.int64).reshape(batch_size, setsz)
x_qrys = np.array(x_qrys).astype(np.float32).reshape(batch_size, querysz, 1, resize, resize)
y_qrys = np.array(y_qrys).astype(np.int64).reshape(batch_size, querysz)
# 将处理好的一个批次数据添加到数据缓存中,包含了10个批次的数据(并不是一个epoch的概念),这一步只是为了减少数据加载时间,不是必须的
data_cache.append([x_spts, y_spts, x_qrys, y_qrys])
return data_cache
这里每次组合10个batch_size,笔者感觉最外层的for循环只是为了减少数据加载时间,不是必须的,一次取一个batc_hsize也问题不大(后续会分析)
4、批次迭代器
# 创建一个字典,存储训练集和测试集的数据缓存
datasets_cache = {"train": load_data_cache(x_train), # 加载并缓存训练数据
"test": load_data_cache(x_test)} # 加载并缓存测试数据
def next(mode='train'):
"""
从数据集中获取下一个批次的数据。
:param mode: 数据集的分割名称("train"、"val" 或 "test" 其中之一)
:return: 返回下一个数据批次
"""
# 如果当前索引大于或等于数据缓存的长度,重置索引并重新加载数据到缓存
if indexes[mode] >= len(datasets_cache[mode]):
indexes[mode] = 0 # 重置索引
datasets_cache[mode] = load_data_cache(datasets[mode]) # 重新加载数据到缓存
# 从缓存中获取下一批数据
next_batch = datasets_cache[mode][indexes[mode]]
indexes[mode] += 1 # 更新索引以指向下一个批次
x_spts, y_spts, x_qrys, y_qrys = next_batch
return next_batch # 返回获取的批次数据
5、基础模型(CNN)
这是一个为 MetaLearner 提供基础网络功能的类,同样继承自 torch.nn.Module。BaseNet 包含了多个卷积层、批处理归一化层和一个全连接层,支持通过外部传入的参数进行快速前向传播。这种设计使得 BaseNet 能够在元学习场景中快速调整其参数以适应新的任务。
import torch
from torch import nn
from torch.nn import functional as F
from copy import deepcopy, copy
class BaseNet(nn.Module):
def __init__(self):
super(BaseNet, self).__init__()
self.vars = nn.ParameterList() # 存储所有可训练参数的列表
self.vars_bn = nn.ParameterList() # 存储批处理归一化层的运行时参数
# 第1个conv2d
# in_channels = 1, out_channels = 64, kernel_size = (3,3), padding = 2, stride = 2
weight = nn.Parameter(torch.ones(64, 1, 3, 3))
nn.init.kaiming_normal_(weight)
bias = nn.Parameter(torch.zeros(64))
self.vars.extend([weight, bias])
# 第1个BatchNorm层
weight = nn.Parameter(torch.ones(64))
bias = nn.Parameter(torch.zeros(64))
self.vars.extend([weight, bias])
running_mean = nn.Parameter(torch.zeros(64), requires_grad=False)
running_var = nn.Parameter(torch.zeros(64), requires_grad=False)
self.vars_bn.extend([running_mean, running_var])
# 第2个conv2d
# in_channels = 1, out_channels = 64, kernel_size = (3,3), padding = 2, stride = 2
weight = nn.Parameter(torch.ones(64, 64, 3, 3))
nn.init.kaiming_normal_(weight)
bias = nn.Parameter(torch.zeros(64))
self.vars.extend([weight, bias])
# 第2个BatchNorm层
weight = nn.Parameter(torch.ones(64))
bias = nn.Parameter(torch.zeros(64))
self.vars.extend([weight, bias])
running_mean = nn.Parameter(torch.zeros(64), requires_grad=False)
running_var = nn.Parameter(torch.zeros(64), requires_grad=False)
self.vars_bn.extend([running_mean, running_var])
# 第3个conv2d
# in_channels = 1, out_channels = 64, kernel_size = (3,3), padding = 2, stride = 2
weight = nn.Parameter(torch.ones(64, 64, 3, 3))
nn.init.kaiming_normal_(weight)
bias = nn.Parameter(torch.zeros(64))
self.vars.extend([weight, bias])
# 第3个BatchNorm层
weight = nn.Parameter(torch.ones(64))
bias = nn.Parameter(torch.zeros(64))
self.vars.extend([weight, bias])
running_mean = nn.Parameter(torch.zeros(64), requires_grad=False)
running_var = nn.Parameter(torch.zeros(64), requires_grad=False)
self.vars_bn.extend([running_mean, running_var])
# 第4个conv2d
# in_channels = 1, out_channels = 64, kernel_size = (3,3), padding = 2, stride = 2
weight = nn.Parameter(torch.ones(64, 64, 3, 3))
nn.init.kaiming_normal_(weight)
bias = nn.Parameter(torch.zeros(64))
self.vars.extend([weight, bias])
# 第4个BatchNorm层
weight = nn.Parameter(torch.ones(64))
bias = nn.Parameter(torch.zeros(64))
self.vars.extend([weight, bias])
running_mean = nn.Parameter(torch.zeros(64), requires_grad=False)
running_var = nn.Parameter(torch.zeros(64), requires_grad=False)
self.vars_bn.extend([running_mean, running_var])
##linear
weight = nn.Parameter(torch.ones([5, 64]))
bias = nn.Parameter(torch.zeros(5))
self.vars.extend([weight, bias])
def forward(self, x, params=None, bn_training=True):
'''
定义模型的前向传播
:param x: 输入数据
:param params: 外部传入的参数列表,用于一些特定情境
:param bn_training: 是否在训练模式下运行批处理归一化
:return: 模型的输出
'''
if params is None:
params = self.vars
weight, bias = params[0], params[1] # 第1个CONV层
x = F.conv2d(x, weight, bias, stride=2, padding=2)
weight, bias = params[2], params[3] # 第1个BN层
running_mean, running_var = self.vars_bn[0], self.vars_bn[1]
x = F.batch_norm(x, running_mean, running_var, weight=weight, bias=bias, training=bn_training)
x = F.max_pool2d(x, kernel_size=2) # 第1个MAX_POOL层
x = F.relu(x, inplace=[True]) # 第1个relu
weight, bias = params[4], params[5] # 第2个CONV层
x = F.conv2d(x, weight, bias, stride=2, padding=2)
weight, bias = params[6], params[7] # 第2个BN层
running_mean, running_var = self.vars_bn[2], self.vars_bn[3]
x = F.batch_norm(x, running_mean, running_var, weight=weight, bias=bias, training=bn_training)
x = F.max_pool2d(x, kernel_size=2) # 第2个MAX_POOL层
x = F.relu(x, inplace=[True]) # 第2个relu
weight, bias = params[8], params[9] # 第3个CONV层
x = F.conv2d(x, weight, bias, stride=2, padding=2)
weight, bias = params[10], params[11] # 第3个BN层
running_mean, running_var = self.vars_bn[4], self.vars_bn[5]
x = F.batch_norm(x, running_mean, running_var, weight=weight, bias=bias, training=bn_training)
x = F.max_pool2d(x, kernel_size=2) # 第3个MAX_POOL层
x = F.relu(x, inplace=[True]) # 第3个relu
weight, bias = params[12], params[13] # 第4个CONV层
x = F.conv2d(x, weight, bias, stride=2, padding=2)
x = F.relu(x, inplace=[True]) # 第4个relu
weight, bias = params[14], params[15] # 第4个BN层
running_mean, running_var = self.vars_bn[6], self.vars_bn[7]
x = F.batch_norm(x, running_mean, running_var, weight=weight, bias=bias, training=bn_training)
x = F.max_pool2d(x, kernel_size=2) # 第4个MAX_POOL层
x = x.view(x.size(0), -1) ## flatten
weight, bias = params[16], params[17] # linear
x = F.linear(x, weight, bias)
output = x
return output
def parameters(self):
return self.vars
6、元学习模型(MAML)
它包括了模型的初始化、前向传播、参数更新(内部和外部循环)、以及微调的实现。该类使用了一个自定义的神经网络 BaseNet 作为底层网络结构,实现了在多任务学习场景下的快速适应性。
import torch
from torch import nn
from torch.nn import functional as F
from copy import deepcopy
class MetaLearner(nn.Module):
def __init__(self):
super(MetaLearner, self).__init__()
self.update_step = 5 # 任务级别的内部更新步骤数
self.update_step_test = 5 # 测试时的更新步骤数
self.net = BaseNet() # 使用自定义的基础网络
self.meta_lr = 2e-4 # 元学习率
self.base_lr = 4 * 1e-2 # 基本学习率
self.inner_lr = 0.4 # 内部循环的学习率
self.outer_lr = 1e-2 # 外部循环的学习率
self.meta_optim = torch.optim.Adam(self.net.parameters(), lr=self.meta_lr) # 元优化器
def forward(self, x_spt, y_spt, x_qry, y_qry):
# 初始化
task_num, ways, shots, h, w = x_spt.size() # 解析支持集的维度
query_size = x_qry.size(1) # 查询集的大小
loss_list_qry = [0 for _ in range(self.update_step + 1)]
correct_list = [0 for _ in range(self.update_step + 1)]
for i in range(task_num): # 遍历每个任务
y_hat = self.net(x_spt[i], params=None, bn_training=True) # 第0步更新
loss = F.cross_entropy(y_hat, y_spt[i]) # 计算交叉熵损失
grad = torch.autograd.grad(loss, self.net.parameters()) # 计算梯度
tuples = zip(grad, self.net.parameters()) # 梯度和参数配对
fast_weights = list(map(lambda p: p[1] - self.base_lr * p[0], tuples)) # 应用梯度更新
# 在query集上计算损失和准确率
with torch.no_grad():
y_hat = self.net(x_qry[i], self.net.parameters(), bn_training=True)
loss_qry = F.cross_entropy(y_hat, y_qry[i])
loss_list_qry[0] += loss_qry
pred_qry = F.softmax(y_hat, dim=1).argmax(dim=1)
correct = torch.eq(pred_qry, y_qry[i]).sum().item()
correct_list[0] += correct
for k in range(1, self.update_step): # 进行更多的更新步骤
y_hat = self.net(x_spt[i], params=fast_weights, bn_training=True)
loss = F.cross_entropy(y_hat, y_spt[i])
grad = torch.autograd.grad(loss, fast_weights)
tuples = zip(grad, fast_weights)
fast_weights = list(map(lambda p: p[1] - self.base_lr * p[0], tuples))
y_hat = self.net(x_qry[i], params=fast_weights, bn_training=True)
loss_qry = F.cross_entropy(y_hat, y_qry[i])
loss_list_qry[k + 1] += loss_qry
with torch.no_grad():
pred_qry = F.softmax(y_hat, dim=1).argmax(dim=1)
correct = torch.eq(pred_qry, y_qry[i]).sum().item()
correct_list[k + 1] += correct
# 计算整体损失和准确率,然后进行梯度下降
loss_qry = loss_list_qry[-1] / task_num
self.meta_optim.zero_grad()
loss_qry.backward()
self.meta_optim.step()
accs = np.array(correct_list) / (query_size * task_num) # 计算平均准确率
loss = np.array(loss_list_qry) / (task_num) # 计算平均损失
return accs, loss
def finetunning(self, x_spt, y_spt, x_qry, y_qry):
assert len(x_spt.shape) == 4
query_size = x_qry.size(0)
correct_list = [0 for _ in range(self.update_step_test + 1)]
new_net = deepcopy(self.net) # 深拷贝网络进行微调
y_hat = new_net(x_spt)
loss = F.cross_entropy(y_hat, y_spt)
grad = torch.autograd.grad(loss, new_net.parameters())
fast_weights = list(map(lambda p: p[1] - self.base_lr * p[0], zip(grad, new_net.parameters())))
with torch.no_grad():
y_hat = new_net(x_qry, params=new_net.parameters(), bn_training=True)
pred_qry = F.softmax(y_hat, dim=1).argmax(dim=1)
correct = torch.eq(pred_qry, y_qry).sum().item()
correct_list[0] += correct
for k in range(1, self.update_step_test):
y_hat = new_net(x_spt, params=fast_weights, bn_training=True)
loss = F.cross_entropy(y_hat, y_spt)
grad = torch.autograd.grad(loss, fast_weights)
fast_weights = list(map(lambda p: p[1] - self.base_lr * p[0], zip(grad, fast_weights)))
y_hat = new_net(x_qry, fast_weights, bn_training=True)
with torch.no_grad():
pred_qry = F.softmax(y_hat, dim=1).argmax(dim=1)
correct = torch.eq(pred_qry, y_qry).sum().item()
correct_list[k + 1] += correct
del new_net
accs = np.array(correct_list) / query_size
return accs
7、测试和评估
import time
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 实例化MetaLearner模型并移至设备
meta = MetaLearner().to(device)
epochs = 60000 # 设置迭代次数
for step in range(epochs):
start = time.time() # 记录开始时间
x_spt, y_spt, x_qry, y_qry = next('train') # 获取训练数据
# 将数据转换为torch tensor并移动到指定设备
x_spt, y_spt, x_qry, y_qry = torch.from_numpy(x_spt).to(device), torch.from_numpy(y_spt).long().to(
device), torch.from_numpy(x_qry).to(device), torch.from_numpy(y_qry).long().to(device)
# 打印形状
accs, loss = meta(x_spt, y_spt, x_qry, y_qry) # 执行前向传播并获取准确率和损失
end = time.time() # 记录结束时间
if step % 10 == 0: # 每10步打印一次结果
print(f"Epoch: {step}-----------------------------------")
print(f"Epoch: {step}, Time: {end - start:.2f}s")
print(f"Training Accuracies: {accs}")
print(f"Training Loss: {loss}")
if step % 100 == 0: # 每100步进行一次更细致的测试
accs = []
for _ in range(100 // task_num): # 按任务数量进行测试迭代
x_spt, y_spt, x_qry, y_qry = next('test') # 获取测试数据
x_spt, y_spt, x_qry, y_qry = torch.from_numpy(x_spt).to(device), torch.from_numpy(y_spt).long().to(
device), torch.from_numpy(x_qry).to(device), torch.from_numpy(y_qry).long().to(device)
for x_spt_one, y_spt_one, x_qry_one, y_qry_one in zip(x_spt, y_spt, x_qry, y_qry): # 对每一个任务的样本进行微调测试
test_acc = meta.finetunning(x_spt_one, y_spt_one, x_qry_one, y_qry_one)
accs.append(test_acc)
accs = np.array(accs).mean(axis=0).astype(np.float16) # 计算所有测试准确率的平均值
print(f'Test Accuracies: {accs}') # 打印平均测试准确率
Epoch: 80, Time: 2.39s
Training Accuracies: [0.205 0. 0.665 0.685 0.67833333 0.66833333]
Training Loss: [1.61406946 0. 1.11111724 1.02459049 0.97860926 0.95577413]
Epoch: 90-----------------------------------
Epoch: 90, Time: 2.43s
Training Accuracies: [0.175 0. 0.55333333 0.54666667 0.54833333 0.55166667]
Training Loss: [1.61060357 0. 1.23749566 1.17854226 1.14995682 1.13922679]
Epoch: 100-----------------------------------
Epoch: 100, Time: 2.40s
Training Accuracies: [0.17666667 0. 0.68333333 0.70333333 0.71333333 0.72 ]
Training Loss: [1.60764313 0. 1.0608958 0.96170616 0.90772164 0.87736452]
Test Accuracies: [0.1895 0. 0.5767 0.589 0.5933 0.5957]
Epoch: 110-----------------------------------
Epoch: 110, Time: 2.28s
Training Accuracies: [0.155 0. 0.62833333 0.65333333 0.66 0.66666667]
Training Loss: [1.61183846 0. 1.09099686 0.99992669 0.95090383 0.92169094]
Epoch: 120-----------------------------------
Epoch: 120, Time: 2.39s
Training Accuracies: [0.20333333 0. 0.58 0.585 0.6 0.59833333]
Training Loss: [1.60731864 0. 1.14290452 1.07339585 1.03362572 1.01608634]
三、疑问和解答
这部分是本文的关键,如果有问题的地方欢迎指正交流
1、module ‘numpy’ has no attribute ‘int’.
AttributeError: module 'numpy' has no attribute 'int'.
`np.int` was a deprecated alias for the builtin `int`. To avoid this error in existing code, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.
The aliases was originally deprecated in NumPy 1.20; for more details and guidance see the original release note at:
https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
这个错误是由于在NumPy 1.20中 np.int 已经被弃用,并且在之后的版本中被移除了。np.int 之前指向的是Python内置的 int 类型,现在需要直接使用 int 或者指定具体的整数精度类型,比如 np.int64 或 np.int32。
2、Batch Size、Epoch、Iterations
-
Batch Size(批次大小):
- 常规学习:
batch_size通常指单次训练过程中输入模型的样本数量。 - 元学习:
batch_size在元学习中通常称为task_num或meta-batch size,表示每次训练迭代中处理的任务(task)数量。每个任务通常包括一个支持集(用于学习)和一个查询集(用于测试学习效果)。
- 常规学习:
-
Epoch(周期):
- 常规学习:一个
epoch指的是整个训练数据集完整地通过模型一次的过程。 - 元学习:由于元学习强调在多个任务上进行快速适应,一个
epoch可以涵盖多个batch_size(即多个任务)。这意味着,整个数据集被视为多个任务的集合,一个epoch可能涉及对这些任务的多次采样和训练。
- 常规学习:一个
-
Iterations(迭代次数):
- 常规学习:通常指数据集通过模型的次数,多个
batch_size组成一个epoch。 - 元学习:在元学习中,
iterations通常与单个任务相关,表示对每个任务内进行模型参数更新的次数(也称为内循环步骤)。这与传统意义上的迭代不同,每次迭代可能包括多个任务的学习过程。
- 常规学习:通常指数据集通过模型的次数,多个
在常规的深度学习训练过程中,一个epoch表示整个训练数据集通过模型训练一次的过程。这里的具体步骤通常包括:
- 数据集的完整遍历:一个epoch涵盖了整个训练数据集,确保每个数据样本都被模型看到一次。
- 批处理:为了有效地处理大量数据和利用硬件(如GPU)的并行处理能力,数据通常被分成多个批次(batch)。这样,一个epoch就包含了多个批次的处理。
- 迭代次数(Iterations):这是进行权重更新的步骤数,每处理一个批次算作一次迭代。因此,迭代次数通常等于训练数据集的样本数量除以批次大小(batch size)。例如,如果你有1000个训练样本和一个批次大小为100,则你需要10次迭代来完成一个epoch。
公式表示: 迭代次数 per epoch = 总样本数 批次大小 \text{迭代次数 per epoch} = \frac{\text{总样本数}}{\text{批次大小}} 迭代次数 per epoch=批次大小总样本数
3、perm用法
在本文的数据缓存中使用perm进行打乱
# 批内随机打乱支持集和查询集
perm = np.random.permutation(n_way * k_spt)
# 生成随机索引(perm):np.random.permutation(n_way * k_spt) 生成一个从 0 到 n_way * k_spt-1 的随机序列,
# 这里 n_way 是类别数,k_spt 是每个类别在支持集中的样本数。这个随机序列用于重新排列支持集中的样本。
x_spt = np.array(x_spt).reshape(n_way * k_spt, 1, resize, resize)[perm]
y_spt = np.array(y_spt).reshape(n_way * k_spt)[perm]
perm = np.random.permutation(n_way * k_query)
x_qry = np.array(x_qry).reshape(n_way * k_query, 1, resize, resize)[perm]
y_qry = np.array(y_qry).reshape(n_way * k_query)[perm]
为什么需要使用perm进行打乱,因为在之前append是按照类型依次进行追加
# 构建支持集和查询集
x_spt.append(dataset[cur_class][selected_img[:k_spt]]) # 支持集图片
x_qry.append(dataset[cur_class][selected_img[k_spt:]]) # 查询集图片
# 从当前类别cur_class中选择前k_spt个图像作为支持集的图像,支持集和查询集的类型是一致的,
# 这里选择前k_spt作为spt,剩下的作为query。
y_spt.append([j for _ in range(k_spt)]) # 支持集标签
y_qry.append([j for _ in range(k_query)]) # 查询集标签
# 列表推导式(List Comprehension):[j for _ in range(k_spt)] 生成一个长度为 k_spt 的列表,其中每个元素都是
4、为什么需要加载10个batchsize
for sample in range(10):
x_spts, y_spts, x_qrys, y_qrys = [], [], [], []
for i in range(batch_size): # 每一个批次都包含多个Task
这里面并不是说,10batchsize个代表一个epoch,而是为了方便加载,从后续的迭代器中可以发现
# 创建一个字典,存储训练集和测试集的数据缓存
datasets_cache = {"train": load_data_cache(x_train), # 加载并缓存训练数据
"test": load_data_cache(x_test)} # 加载并缓存测试数据
def next(mode='train'):
"""
从数据集中获取下一个批次的数据。
:param mode: 数据集的分割名称("train"、"val" 或 "test" 其中之一)
:return: 返回下一个数据批次
"""
# 如果当前索引大于或等于数据缓存的长度,重置索引并重新加载数据到缓存
if indexes[mode] >= len(datasets_cache[mode]):
indexes[mode] = 0 # 重置索引
datasets_cache[mode] = load_data_cache(datasets[mode]) # 重新加载数据到缓存
# 从缓存中获取下一批数据
next_batch = datasets_cache[mode][indexes[mode]]
indexes[mode] += 1 # 更新索引以指向下一个批次
x_spts, y_spts, x_qrys, y_qrys = next_batch
return next_batch # 返回获取的批次数据
indexes = {"train": 0, "test": 0}
# `indexes` 字典存储了用于训练集和测试集的当前索引,初始化为0。这些索引可以用来控制从数据集中获取批次数据的位置。后续通过indexes[mode]来获取当前模式的索引。
datasets = {"train": x_train, "test": x_test}
# `datasets` 字典将字符串键 "train" 和 "test" 映射到相应的数据集。x_train 是训练数据集,x_test 是测试数据集。
# 这样设置允许代码以统一的方式通过键访问这些数据集,便于在训练和测试过程中加载数据。
print("DB: train", x_train.shape, "test", x_test.shape)
# 这行代码输出训练数据集和测试数据集的形状。数据集的形状通常包括样本数和每个样本的特征数(对于图像数据,可能是三维形状:高度、宽度、颜色通道)。
# 打印这些信息有助于验证数据加载正确,且形状符合模型输入的要求。
这里面的indexes[mode]开始定义成0,datasets_cache[mode]定义成的批次长度是10,从datasets_cache[mode]中加载第一个批次,并让索引加1
next_batch = datasets_cache[mode][indexes[mode]]
indexes[mode] += 1 # 更新索引以指向下一个批次
如果索引大于或等于数据缓存的长度, datasets_cache[mode] = load_data_cache(datasets[mode]) 重新加载数据到缓存
# 如果当前索引大于或等于数据缓存的长度,重置索引并重新加载数据到缓存
if indexes[mode] >= len(datasets_cache[mode]):
indexes[mode] = 0 # 重置索引
datasets_cache[mode] = load_data_cache(datasets[mode]) # 重新加载数据到缓存
这种方法避免了每次调用时都重新加载数据,从而提高了访问效率。
5、迭代器每次取多少数据?
# 创建一个字典,存储训练集和测试集的数据缓存
datasets_cache = {"train": load_data_cache(x_train), # 加载并缓存训练数据
"test": load_data_cache(x_test)} # 加载并缓存测试数据
def next(mode='train'):
"""
从数据集中获取下一个批次的数据。
:param mode: 数据集的分割名称("train"、"val" 或 "test" 其中之一)
:return: 返回下一个数据批次
"""
# 如果当前索引大于或等于数据缓存的长度,重置索引并重新加载数据到缓存
if indexes[mode] >= len(datasets_cache[mode]):
indexes[mode] = 0 # 重置索引
datasets_cache[mode] = load_data_cache(datasets[mode]) # 重新加载数据到缓存
# 从缓存中获取下一批数据
next_batch = datasets_cache[mode][indexes[mode]]
indexes[mode] += 1 # 更新索引以指向下一个批次
x_spts, y_spts, x_qrys, y_qrys = next_batch
return next_batch # 返回获取的批次数据
在这个 next 函数中,next_batch 返回的是单个批次的数据,而不是多个批次。这个批次数据包括一组支持集(x_spts, y_spts)和查询集(x_qrys, y_qrys)的数据,这些数据用于训练和测试元学习模型。
每次当函数 next 被调用时,它会:
- 检查当前索引是否已经达到缓存数据的长度。如果是,它将重置索引并重新加载数据集到缓存,以便再次从头开始提供数据。
- 从缓存中提取当前索引对应的数据批次,然后将索引增加1,准备下次调用时获取下一个数据批次。
因此,next_batch 变量中包含的是当前索引指向的那个特定的数据批次,由以下元素组成:
x_spts:支持集的输入特征。y_spts:支持集的标签。x_qrys:查询集的输入特征。y_qrys:查询集的标签。
每个批次通常包括为多个任务准备的数据,每个任务包含了 n_way 类别和每类 k_spt 个支持样本及 k_query 个查询样本,但这整个组合被视为单一批次的一部分,适用于一次训练或测试迭代。
import time
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 实例化MetaLearner模型并移至设备
meta = MetaLearner().to(device)
epochs = 60000 # 设置迭代次数
for step in range(epochs):
start = time.time() # 记录开始时间
x_spt, y_spt, x_qry, y_qry = next('train') # 获取训练数据
# 将数据转换为torch tensor并移动到指定设备
x_spt, y_spt, x_qry, y_qry = torch.from_numpy(x_spt).to(device), torch.from_numpy(y_spt).long().to(
device), torch.from_numpy(x_qry).to(device), torch.from_numpy(y_qry).long().to(device)
# 打印形状
accs, loss = meta(x_spt, y_spt, x_qry, y_qry) # 执行前向传播并获取准确率和损失
end = time.time() # 记录结束时间
if step % 10 == 0: # 每10步打印一次结果
print(f"Epoch: {step}-----------------------------------")
print(f"Epoch: {step}, Time: {end - start:.2f}s")
print(f"Training Accuracies: {accs}")
print(f"Training Loss: {loss}")
if step % 100 == 0: # 每100步进行一次更细致的测试
accs = []
for _ in range(100 // task_num): # 按任务数量进行测试迭代
x_spt, y_spt, x_qry, y_qry = next('test') # 获取测试数据
x_spt, y_spt, x_qry, y_qry = torch.from_numpy(x_spt).to(device), torch.from_numpy(y_spt).long().to(
device), torch.from_numpy(x_qry).to(device), torch.from_numpy(y_qry).long().to(device)
for x_spt_one, y_spt_one, x_qry_one, y_qry_one in zip(x_spt, y_spt, x_qry, y_qry): # 对每一个任务的样本进行微调测试
test_acc = meta.finetunning(x_spt_one, y_spt_one, x_qry_one, y_qry_one)
accs.append(test_acc)
print(f'Accuracies array shape before mean: {np.array(accs).shape}') # 打印累计的准确率数组形状
accs = np.array(accs).mean(axis=0).astype(np.float16) # 计算所有测试准确率的平均值
print(f'Test Accuracies: {accs}') # 打印平均测试准确率
6、params=None/fast_weights/new_net.parameters
这里面包含局部变量和全局变量
包含训练集和测试集的两部分内容
- 全局变量
y_hat = self.net(x_spt[i], params=None, bn_training=True) # 第0步更新
self.vars = nn.ParameterList() # 存储所有可训练参数的列表
self.vars_bn = nn.ParameterList() # 存储批处理归一化层的运行时参数
# 第1个conv2d
# in_channels = 1, out_channels = 64, kernel_size = (3,3), padding = 2, stride = 2
weight = nn.Parameter(torch.ones(64, 1, 3, 3))
nn.init.kaiming_normal_(weight)
bias = nn.Parameter(torch.zeros(64))
self.vars.extend([weight, bias])
当params=None时,模型使用其原始参数或当前训练状态的参数进行前向传播,这通常用在每个任务的第一步,即不进行更新的结果,最后在query上计算loss和acc,其中 self.net.parameters()和 params=None实际上指向同一组参数,即模型的全局参数。
# 在query集上计算损失和准确率
with torch.no_grad():
y_hat = self.net(x_qry[i], self.net.parameters(), bn_training=True)
loss_qry = F.cross_entropy(y_hat, y_qry[i])
loss_list_qry[0] += loss_qry
pred_qry = F.softmax(y_hat, dim=1).argmax(dim=1)
correct = torch.eq(pred_qry, y_qry[i]).sum().item()
correct_list[0] += correct
- 局部变量
for k in range(1, self.update_step): # 进行更多的更新步骤
y_hat = self.net(x_spt[i], params=fast_weights, bn_training=True)
loss = F.cross_entropy(y_hat, y_spt[i])
grad = torch.autograd.grad(loss, fast_weights)
tuples = zip(grad, fast_weights)
fast_weights = list(map(lambda p: p[1] - self.base_lr * p[0], tuples))
y_hat = self.net(x_qry[i], params=fast_weights, bn_training=True)
loss_qry = F.cross_entropy(y_hat, y_qry[i])
loss_list_qry[k + 1] += loss_qry
with torch.no_grad():
pred_qry = F.softmax(y_hat, dim=1).argmax(dim=1)
correct = torch.eq(pred_qry, y_qry[i]).sum().item()
correct_list[k + 1] += correct
这里面通过指定params=fast_weights仅仅在内循环中临时计算,不是永久存储在网络的任何属性中。它们是基于当前任务的支持集数据计算出来的,通常存储在局部变量fast_weights中,这些权重是在每个任务的内循环中使用当前任务的梯度动态计算的。
计算查询集上的损失,累加到loss_list_qry中,用于监控学习过程。
计算模型的预测准确率,更新correct_list,这个列表跟踪了每一步更新后模型在查询集上的准确率。
- 全局变量
# 计算整体损失和准确率,然后进行梯度下降
loss_qry = loss_list_qry[-1] / task_num
self.meta_optim.zero_grad()
loss_qry.backward()
self.meta_optim.step()
最后计算平均损失,反向传播,更新模型。这里的关键是元优化器不直接作用于fast_weights,而是更新模型的初始(全局)参数,从而使模型在多个任务上具有更好的泛化能力。
如果从训练集和测试集的角度来看
- 训练集
accs, loss = meta(x_spt, y_spt, x_qry, y_qry) # 执行前向传播并获取准确率和损失
def forward(self, x_spt, y_spt, x_qry, y_qry):
# 初始化
task_num, ways, shots, h, w = x_spt.size() # 解析支持集的维度
query_size = x_qry.size(1) # 查询集的大小
loss_list_qry = [0 for _ in range(self.update_step + 1)]
correct_list = [0 for _ in range(self.update_step + 1)]
for i in range(task_num): # 遍历每个任务
y_hat = self.net(x_spt[i], params=None, bn_training=True) # 第0步更新
loss = F.cross_entropy(y_hat, y_spt[i]) # 计算交叉熵损失
grad = torch.autograd.grad(loss, self.net.parameters()) # 计算梯度
tuples = zip(grad, self.net.parameters()) # 梯度和参数配对
fast_weights = list(map(lambda p: p[1] - self.base_lr * p[0], tuples)) # 应用梯度更新
# 在query集上计算损失和准确率
with torch.no_grad():
y_hat = self.net(x_qry[i], self.net.parameters(), bn_training=True)
loss_qry = F.cross_entropy(y_hat, y_qry[i])
loss_list_qry[0] += loss_qry
pred_qry = F.softmax(y_hat, dim=1).argmax(dim=1)
correct = torch.eq(pred_qry, y_qry[i]).sum().item()
correct_list[0] += correct
for k in range(1, self.update_step): # 进行更多的更新步骤
y_hat = self.net(x_spt[i], params=fast_weights, bn_training=True)
loss = F.cross_entropy(y_hat, y_spt[i])
grad = torch.autograd.grad(loss, fast_weights)
tuples = zip(grad, fast_weights)
fast_weights = list(map(lambda p: p[1] - self.base_lr * p[0], tuples))
y_hat = self.net(x_qry[i], params=fast_weights, bn_training=True)
loss_qry = F.cross_entropy(y_hat, y_qry[i])
loss_list_qry[k + 1] += loss_qry
with torch.no_grad():
pred_qry = F.softmax(y_hat, dim=1).argmax(dim=1)
correct = torch.eq(pred_qry, y_qry[i]).sum().item()
correct_list[k + 1] += correct
# 计算整体损失和准确率,然后进行梯度下降
loss_qry = loss_list_qry[-1] / task_num
self.meta_optim.zero_grad()
loss_qry.backward()
self.meta_optim.step()
accs = np.array(correct_list) / (query_size * task_num) # 计算平均准确率
loss = np.array(loss_list_qry) / (task_num) # 计算平均损失
return accs, loss
内循环(任务级别的快速适应)
- 初始化: 对每个任务(
task_num个),模型从支持集(x_spt)接收输入,并预测输出(y_hat)。这些任务通常涉及到几个类别(ways),每类几个样本(shots),用于训练和评估模型的快速学习能力。 - 第0步更新:
- 首先,使用模型当前的全局参数(
params=None,即没有进行任何任务特定更新的参数)对支持集进行前向传播,得到预测结果。 - 计算预测结果与真实标签(
y_spt)之间的交叉熵损失。 - 对损失函数求导,获取参数的梯度。
- 首先,使用模型当前的全局参数(
- 应用梯度更新:
- 根据计算出的梯度和学习率(
self.base_lr),更新参数,得到新的任务特定参数集合(fast_weights)。
- 根据计算出的梯度和学习率(
- 多次迭代更新:
- 对于每个任务,模型进行多次(由
self.update_step指定)的快速适应步骤。 - 在每一步中,使用更新后的参数(
fast_weights)对支持集进行再次前向传播和损失计算。 - 再次计算梯度并更新
fast_weights,用于下一步的训练或最终的查询集测试。
- 对于每个任务,模型进行多次(由
- 在查询集上评估:
- 使用最新的
fast_weights在查询集上进行前向传播,得到损失和预测结果。 - 计算查询集上的损失,累加到
loss_list_qry中,用于监控学习过程。 - 计算模型的预测准确率,更新
correct_list,这个列表跟踪了每一步更新后模型在查询集上的准确率。
- 使用最新的
外循环(全局更新)
- 聚合损失并反向传播
- 任务完成后,取最后一次迭代(或特定步骤)的查询集损失,计算平均损失。
- 使用元优化器(
self.meta_optim)将损失反向传播,更新模型的全局参数。 - 这里的关键是元优化器不直接作用于
fast_weights,而是更新模型的初始(全局)参数,从而使模型在多个任务上具有更好的泛化能力。
- 测试集
test_acc = meta.finetunning(x_spt_one, y_spt_one, x_qry_one, y_qry_one)
def finetunning(self, x_spt, y_spt, x_qry, y_qry):
assert len(x_spt.shape) == 4
query_size = x_qry.size(0)
correct_list = [0 for _ in range(self.update_step_test + 1)]
new_net = deepcopy(self.net) # 深拷贝网络进行微调
y_hat = new_net(x_spt)
loss = F.cross_entropy(y_hat, y_spt)
grad = torch.autograd.grad(loss, new_net.parameters())
fast_weights = list(map(lambda p: p[1] - self.base_lr * p[0], zip(grad, new_net.parameters())))
with torch.no_grad():
y_hat = new_net(x_qry, params=new_net.parameters(), bn_training=True)
pred_qry = F.softmax(y_hat, dim=1).argmax(dim=1)
correct = torch.eq(pred_qry, y_qry).sum().item()
correct_list[0] += correct
for k in range(1, self.update_step_test):
y_hat = new_net(x_spt, params=fast_weights, bn_training=True)
loss = F.cross_entropy(y_hat, y_spt)
grad = torch.autograd.grad(loss, fast_weights)
fast_weights = list(map(lambda p: p[1] - self.base_lr * p[0], zip(grad, fast_weights)))
y_hat = new_net(x_qry, fast_weights, bn_training=True)
with torch.no_grad():
pred_qry = F.softmax(y_hat, dim=1).argmax(dim=1)
correct = torch.eq(pred_qry, y_qry).sum().item()
correct_list[k + 1] += correct
del new_net
accs = np.array(correct_list) / query_size
return accs
初始化和断言:
- 确保输入的支持集
x_spt的维度为4,这是因为期望的输入是一个四维的张量(例如,批量大小、通道、高度、宽度)。
设置和拷贝模型:
- 计算查询集
x_qry的大小,这通常用于最终计算模型性能的标准化。 - 通过
deepcopy对原始模型self.net进行深拷贝,创建一个新的网络new_net,这保证了原始模型的参数在微调过程中不会被更改。
第一次迭代:
- 使用拷贝的模型
new_net在支持集上进行前向传播,计算输出y_hat。 - 计算
y_hat和真实标签y_spt之间的交叉熵损失。 - 计算损失相对于模型参数的梯度。
- 根据梯度更新参数,创建
fast_weights,这是微调后的参数列表。
查询集上的评估:
- 在查询集上使用未更新的
new_net进行前向传播,并计算预测准确率,将结果累加到correct_list中。
多步迭代更新:
- 对于
self.update_step_test指定的每个迭代步骤,重复执行以下步骤:- 使用更新后的参数
fast_weights在支持集上重新进行前向传播和损失计算。 - 再次计算梯度并更新
fast_weights。 - 使用更新后的
fast_weights在查询集上进行前向传播,计算预测准确率并更新correct_list。
- 使用更新后的参数
清理和返回:
- 删除微调用的网络
new_net以释放内存。 - 计算每个迭代步骤后查询集上的平均准确率,并返回这些准确率。
7、轮次的增加会更新哪些参数?
内循环更新:在每个训练步骤中,meta(x_spt, y_spt, x_qry, y_qry) 函数调用涉及到内循环的执行,这里使用训练集的支持集 (x_spt 和 y_spt) 来进行模型参数的局部更新。在内循环中,根据支持集计算的梯度用于更新“快速权重”(fast_weights),这些权重是对原始模型参数的临时、局部调整。
查询集上的评估:使用更新后的快速权重,模型在相同任务的查询集 (x_qry 和 y_qry) 上进行评估,以计算准确率和损失。这个步骤是为了测试模型在学到新知识后的表现。
外循环更新:外循环负责更新模型的全局参数。这是通过整合多个任务的查询集损失来进行的。全局参数更新有助于模型学习如何更好地从新任务中快速学习。
测试阶段:定期(每100步)进行的测试阶段涉及到更细致的评估。在这里,模型的当前全局参数被深拷贝,然后使用测试集的支持集进行进一步的微调(finetuning)。这个微调过程使用的是新的局部参数(fast_weights),这些参数基于微调后的模型在测试集的查询集上评估。
8、出现多次with torch.no_grad()
防止梯度计算:在使用 self.net(x_qry[i], self.net.parameters(), bn_training=True) 和后续步骤中评估查询集时,不需要计算梯度。这样做主要是为了效率考虑,因为梯度计算会占用额外的计算资源和内存,而在评估模式下我们只关心前向传播的结果,不需要对模型进行优化。
防止梯度累积:在深度学习模型训练过程中,如果不使用 .zero_grad() 来清除之前的梯度,梯度会持续累积。在评估时,使用 torch.no_grad() 确保了即使忘记调用 .zero_grad(),也不会导致意外的梯度累积。
9、self.update_step/update_step_test 分别用于更新什么内容?
- self.update_step
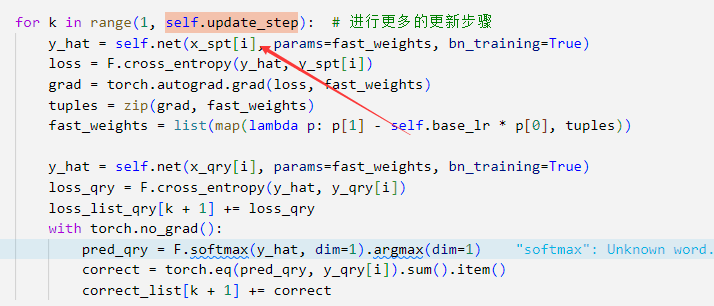
self.update_step 用于在训练集的支持集中更新
- update_step_test
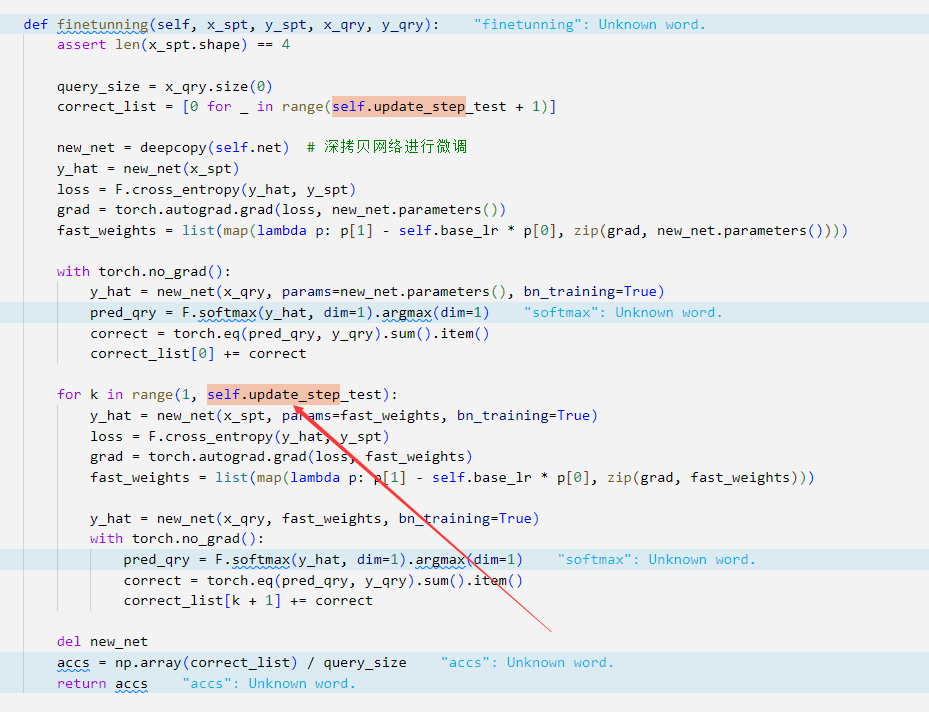
类似的这里update_step_test 用于在测试集上的支持集的更新,并且二者更新的都是临时/局部/内部的。
10、为什么不对查询集进行多次梯度下降?
避免过拟合:如果在查询集上进行多次梯度更新,模型可能会过度拟合到查询集上,从而失去泛化到新任务的能力。查询集的目的是提供一个公正的评估方式来模拟真实世界中遇到全新任务的场景。
学习目标:元学习的目标是让模型学会如何快速学习新任务,而不是在一个特定任务上表现得尽可能好。因此,关键是要让模型通过少量的更新就能在支持集上表现良好,并且这种表现能泛化到查询集上。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









