






 本文介绍了Java的基础概念,包括类与对象的区别、元数据的定义与层次结构,以及Java数据结构的逻辑与物理结构。重点讲解了集合框架、迭代器、Map接口(如Set、List和Map的特性)、以及ArrayList和fail-fast机制。
本文介绍了Java的基础概念,包括类与对象的区别、元数据的定义与层次结构,以及Java数据结构的逻辑与物理结构。重点讲解了集合框架、迭代器、Map接口(如Set、List和Map的特性)、以及ArrayList和fail-fast机制。
java基础
1.class 不存在于内存中,是理论上的对象,它为对象提供蓝图,但在内存中并不存在。从这个蓝图可以创建任何数量的对象。类变量包含了被类所有实例共享的信息。比如,假设所有的自行车有相同的档位数
2.Object 注意属性和方法,方法是对属性的封装
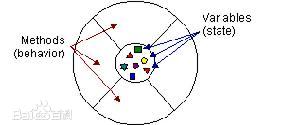
3.元数据(Metadata) 描述数据的数据,
总体结构定义方式 一个Metadata格式由多层次的结构予以定义:
(1)内容结构(Content Structure),对该Metadata的构成元素及其定义标准进行描述。
(2)句法结构(Syntax Structure),定义Metadata结构以及如何描述这种结构。
(3)语义结构(Semantic Structure),定义Metadata元素的具体描述方法。
4.域(field )
- What is a field in java?
- A field is an attribute. A field may be a class’s variable, an object’s variable, an object’s method’s variable, or a parameter of a function.
- {}之中的东西
java数据结构
1.逻辑结构
- 与存储位置无关
- 数据元素之间的前后间关系
a.集合
b.线性结构 1对1
c.树形结构 一对多
d.图形结构 多对多
2. 物理结构
- 计算机存储空间的存放形式
- 数据元素本身存放
- 关系存放
a.顺序存放(通过相对位置,如数组)
b.非顺序存放(通过引用,如链表)
java的集合
总体
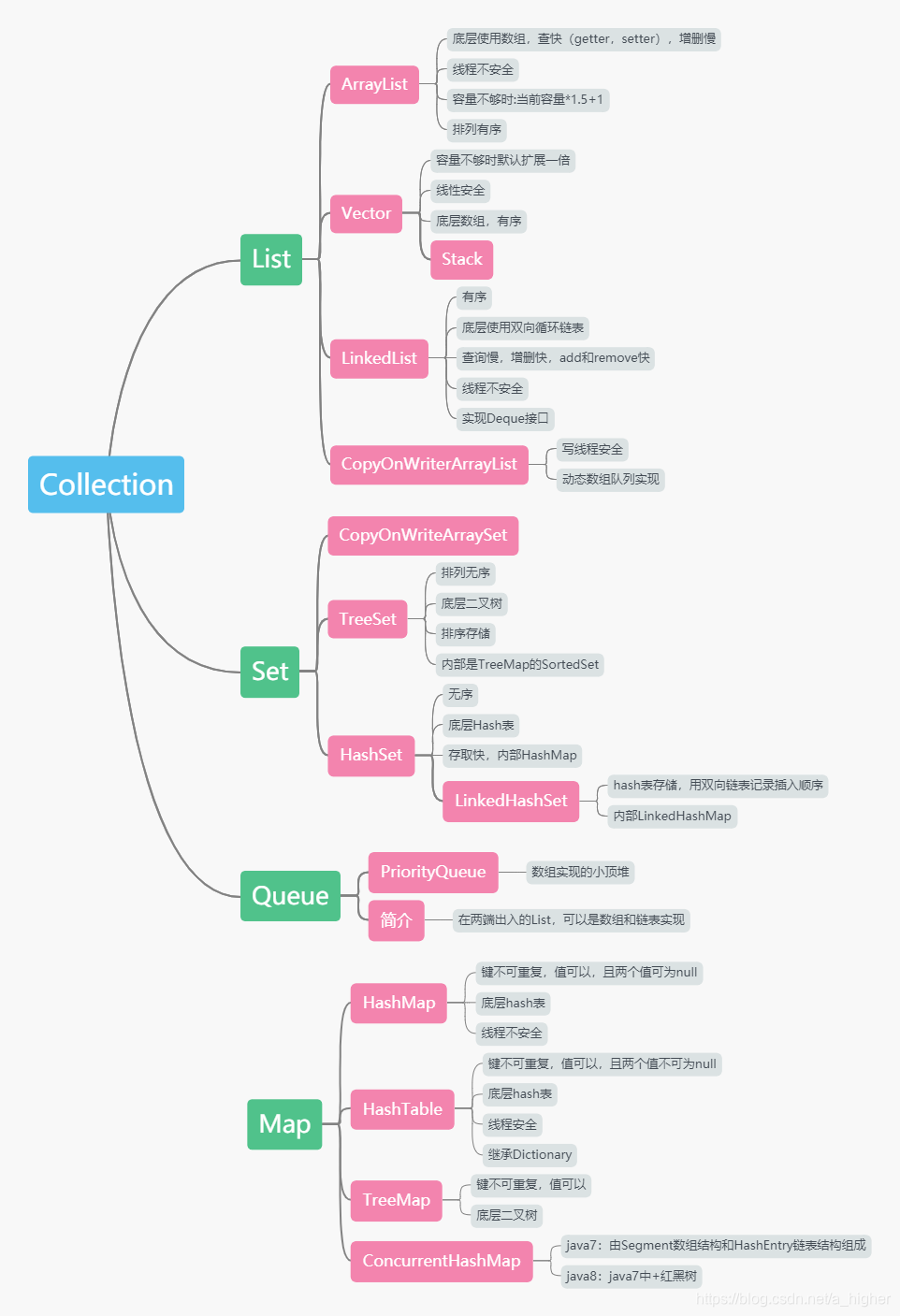
Iterable接口
Implementing this interface allows an object to be the target of the "for-each loop" statement
map接口
- 是一个key映射values,每个key只有一个对应的value,作为Dictionary替代。
- 有三种集合:keys的set,values的collection,key-values的mapping,其中这个map的顺序由迭代器定义,像TreeMap是Map的实现,保证了顺序。如果Map的Values是可变的,会影响Map的Key的equals的比较,有个特例,Map本身不可以作为key,但可以作为value,这么做的话,hashcode和equals就需要注意了,可能不适用了
- 所有通用的map实现类应该有2个构造方法,无参的去创建简单map,有相同key-value 映射关系(mapping)的参数的构造方法创建一个新的map,这个map可以我们想要得到的类的map。这个建议无法强制执行,因为它是一个接口,但jdk中是这么做的
- The "destructive" methods contained in this interface, that is, the methods that modify the map on which they operate(我的理解是修改map里的东西的方法),如果不支持会抛出UnsupportedOperationException,如;在不可以修改的map中调用putAll(Map),如果叠加的mapping是空的就不会报错
- 一些map实现对它们可能包含的键和值有限制,如:不能为空,或者查询不存在的数,会报错或者返回false
- 集合框架接口中的许多方法都是根据{@link Object#equals(Object)equals}方法定义的,各种集合框架接口的实现可以自由地利用底层{@link Object}方法的指定行为
- 一些递归操作可能会失败,如clone(),equals(),hashCode()andoString() methods.
- map中有个entry接口。A map entry (key-value pair).。Map.entrySet方法返回map的collection-view,其元素属于此类。这是唯一的方式从collection-view的iterator中得到map entry的引用。这些Map.Entry对象仅在迭代期间有效;更正式地说,如果在迭代器返回entry后又修改了map,则map entry的行为是未定义的,除非通过对map entry执行setValue操作。
* <p>Many methods in Collections Framework interfaces are defined
* in terms of the {@link Object#equals(Object) equals} method. For
* example, the specification for the {@link #containsKey(Object)
* containsKey(Object key)} method says: "returns <tt>true</tt> if and
* only if this map contains a mapping for a key <tt>k</tt> such that
* <tt>(key==null ? k==null : key.equals(k))</tt>." This specification should
* <i>not</i> be construed to imply that invoking <tt>Map.containsKey</tt>
* with a non-null argument <tt>key</tt> will cause <tt>key.equals(k)</tt> to
* be invoked for any key <tt>k</tt>. Implementations are free to
* implement optimizations whereby the <tt>equals</tt> invocation is avoided,
* for example, by first comparing the hash codes of the two keys. (The
* {@link Object#hashCode()} specification guarantees that two objects with
* unequal hash codes cannot be equal.) More generally, implementations of
* the various Collections Framework interfaces are free to take advantage of
* the specified behavior of underlying {@link Object} methods wherever the
* implementor deems it appropriate.
*
* <p>Some map operations which perform recursive traversal of the map may fail
* with an exception for self-referential instances where the map directly or
* indirectly contains itself. This includes the {@code clone()},
* {@code equals()}, {@code hashCode()} and {@code toString()} methods.
* Implementations may optionally handle the self-referential scenario, however
* most current implementations do not do so.
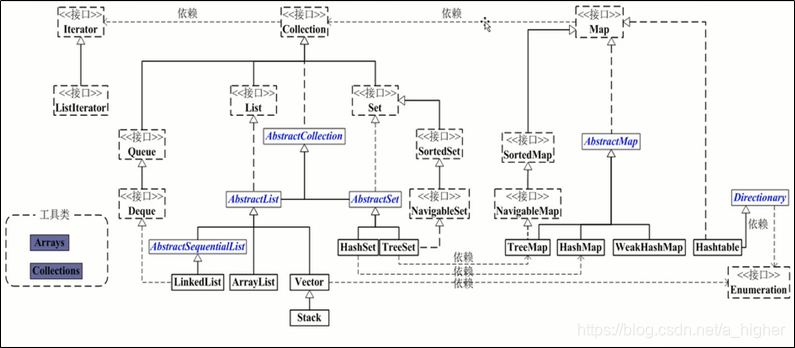
Collection接口
- 由每个集合决定自己的同步策略。在实现没有更有力的保证的情况下,未定义的行为可能是由于调用正在被另一个线程更改的集合上的任何方法引起的;这包括直接调用、将集合传递给可能执行调用的方法,以及使用现有的迭代器检查集合。(我的理解是fail-fast(快速失败)机制)
map也有的
- 所有通用的map实现类应该有2个构造方法,无参的去创建简单map,有相同key-value 映射关系(mapping)的参数的构造方法创建一个新的map,这个map可以我们想要得到的类的map。这个建议无法强制执行,因为它是一个接口,但jdk中是这么做的
- The "destructive" methods contained in this interface, that is, the methods that modify the map on which they operate(我的理解是修改map里的东西的方法),如果不支持会抛出UnsupportedOperationException,如;在不可以修改的map中调用putAll(Map),如果叠加的mapping是空的就不会报错
- 一些map实现对它们可能包含的键和值有限制,如:不能为空,或者查询不存在的数,会报错或者返回false
- 集合框架接口中的许多方法都是根据{@link Object#equals(Object)equals}方法定义的,各种集合框架接口的实现可以自由地利用底层{@link Object}方法的指定行为
- 一些递归操作可能会失败,如clone(),equals(),hashCode()and toString() methods.
List
- 一个有序的collection,这个接口可以精准控制list中的每一个元素的插入和查找
- 允许元素重复,元素如果没有规定可以为null
- 增加了iterator, add, remove, equals, and hashCode方法
- List接口为列表元素的位置(索引)访问提供了四种方法
- 提供了特殊的iterator,允许元素插入和替换,以及双向访问,还提供了一个方法来获取从列表中指定位置开始的ListIterator
- 提供了两种搜索指定对象的方法。从性能的角度来看,应该谨慎使用这些方法。在许多实现中,它们将执行代价高昂的线性搜索。
- 提供了两种方法来有效地在列表中的任意点插入和删除多个元素
- 虽然允许列表将其自身作为元素包含,但建议您格外小心:equals和hashCode方法在这样的列表中不再定义得很好。
- 有些list实现对它们可能包含的元素有限制。例如,有些实现禁止空元素,有些实现对其元素的类型有限制。尝试添加不合格的元素会引发未经检查的异常,通常是<tt>NullPointerException</tt>或<tt>ClassCastException</tt>。尝试查询不合格元素的存在可能会引发异常,也可能只是返回false;有些实现将显示前一种行为,有些实现将显示后一种行为。更一般地说,尝试对一个不合格的元素执行操作,而该元素的完成不会导致将不合格元素插入列表中,则可能会引发异常,也可能会成功,具体取决于实现。本规范中的“例外”标记为“可选”
AbstractList
- 这个类提供了linklist接口的框架实现,以最小化实现由“随机访问”数据存储(如数组)支持的接口所需的工作量。对于顺序存取资料(例如链表),AbstractSequentialList应该优先使用这个类别
- 为了实现一个不可修改的列表,程序员只需要扩展这个类,并提供get(int)和list#size()size()方法的实现
- 为了实现可修改的列表,程序员必须另外重写#set(int,Object)set(int,E)方法(否则会抛出 UnsupportedOperationException)。如果列表大小可变,程序员必须另外重写#add(int,Object)add(int,E)和#remove(int)方法。
- 根据collection接口规范中的建议,程序员通常应该提供一个void(无参数)和collection构造函数
- Unlike the other abstract collection implementations, the programmer does <i>not</i> have to provide an iterator implementation; the iterator and list iterator are implemented by this class, on top of the "random access" methods: {@link #get(int)},{@link #set(int, Object) set(int, E)},{@link #add(int, Object) add(int, E)} and {@link #remove(int)}(与其他抽象集合实现不同,程序员不需要提供迭代器实现;迭代器和列表迭代器由这个类在“随机访问”方法之上实现)
- 这个类中每个非抽象方法的文档详细描述了它的实现。如果正在实现的集合有更有效的实现,则可以重写这些方法中的每一个.
- 内部有
private class Itr implements Iterator<E>
private class ListItr extends Itr implements ListIterator<E>
class SubList<E> extends AbstractList<E>
class RandomAccessSubList<E> extends SubList<E> implements RandomAccess
Set
- 没有重复元素的集合
- 除了从Collection接口继承的那些之外,Set接口在所有构造函数的契约上以及add、equals和hashCode方法上放置额外的规定。为了方便起见,这里还包括了其他继承方法的声明。
- 如果set中使用可变对象作为set的元素,而其对象的值的改变如果影响equals方法的比较,就不具体指定set的行为
- 一些set实现对它们可能包含的元素有限制。例如,有些实现禁止空元素,有些实现对其元素的类型有限制。尝试添加不合格的元素会引发未经检查的异常,通常是<tt>NullPointerException</tt>或<tt>ClassCastException</tt>。尝试查询不合格元素的存在可能会引发异常,也可能只是返回false;有些实现将显示前一种行为,有些实现将显示后一种行为。更一般地说,尝试对一个不合格的元素执行操作,而该元素的完成不会导致将不合格元素插入到集合中,则可能会引发异常,也可能会成功,具体取决于实现。此类异常在该接口的规范中标记为“可选”
AbstractList
- 这个类提供了{@linklist}接口的框架实现,以最小化实现由“随机访问”数据存储(如数组)支持的接口所需的工作量。对于顺序存取资料(例如链表),{@link AbstractSequentialList}应该优先使用这个类别。
- 为了实现一个不可修改的列表,程序员只需要扩展这个类,并提供get(int)和list#size()size()方法的实现
- 为了实现可修改的列表,程序员必须另外重写#set(int,Object)set(int,E)方法(否则会抛出 UnsupportedOperationException)。如果列表大小可变,程序员必须另外重写#add(int,Object)add(int,E)和#remove(int)方法。
- 根据collection接口规范中的建议,程序员通常应该提供一个void(无参数)和collection构造函数
- Unlike the other abstract collection implementations, the programmer does <i>not</i> have to provide an iterator implementation; the iterator and list iterator are implemented by this class, on top of the "random access" methods: {@link #get(int)},{@link #set(int, Object) set(int, E)},{@link #add(int, Object) add(int, E)} and {@link #remove(int)}(与其他抽象集合实现不同,程序员不需要提供迭代器实现;迭代器和列表迭代器由这个类在“随机访问”方法之上实现)
- 这个类中每个非抽象方法的文档详细描述了它的实现。如果正在实现的集合有更有效的实现,则可以重写这些方法中的每一个.
- 内部有
private class Itr implements Iterator<E>
private class ListItr extends Itr implements ListIterator<E>
class SubList<E> extends AbstractList<E>
class RandomAccessSubList<E> extends SubList<E> implements RandomAccess
AbstractSet
- 这个类提供了Set接口的框架实现,以最小化实现该接口所需的工作量。
- 通过扩展此类实现Set的过程与通过扩展AbstractCollection实现集合的过程相同,只是此类的子类中的所有方法和构造函数都必须遵守Set接口施加的附加约束(例如,add方法不能允许添加一个对象集合的多个实例)。
- 这个类不重写AbstractCollection类中的任何实现。它只是添加了equals和hashCode的实现
SortedMap
- 一个Map,它进一步提供了一个order的总钥匙。那个map是根据Comparable natural ordering来排序的,或者通常在排序的map创建时提供的comparator来排序。当迭代已排序映射的集合视图(由{@code entrySet}、{@code keySet}和{@code values}方法返回)时,会调用这个排序。还提供了几个方法去排序。(此接口是{@link SortedSet}的map模拟。)
- 插入排序映射中的所有键都必须实现{@codecomparable}接口(或由指定的比较器)。此外,所有这样的键必须可以相互比较:{@code k1.compareTo(k2)}(或{@code comparator.compare(k1, k2)})不能为排序映射中的任何键{@code k1}和{@code k2}抛出{@code ClassCastException}。尝试违反此限制将导致有问题的方法或构造函数调用抛出{@code ClassCastException}。
- map的排序顺序与equals一致,参照Comparable或 Comparator接口,map根据equals定义操作,排序使用compareTo 或 compare方法执行所有key的比较,因此,equals认为两个key相等,tree map是已经定义好的,即使它的顺序与equals不一致,它只是未能遵守map接口的通用约定
- 所有通用的已排序map实现类都应该提供四个“标准”构造函数。尽管接口不能强制执行此建议,但它不能被构造函数指定。所有已排序映射实现的预期“标准”构造函数是:一个void(无参数)构造函数,它创建一个空的按键的自然顺序排序的已排序map。一个具有{@code Comparator}类型的参数的构造函数,它创建一个根据指定的比较Comparator排序的空的排序map。一种具有{@code Map}类型的单参数的构造函数,该构造函数创建一个新的map,该map的键值映射与其参数相同(creates a new map with the same key-value mappings as its argument),并根据key的自然顺序排序;一种具有{@code SortedMap}类型的单参数的构造函数,它创建一个新的排序map(creates a new sorted map with the same key-value mappings and the same ordering as the input sorted map.)
- 有几种方法返回具有限制key范围的submaps。这些范围是半开的,也就是说,它们包括它们的低端点,而不是它们的高端点(如果适用)。如果您需要一个<em>闭合范围</em>(包括两个端点),并且key类型允许计算给定key的后继项,那么只需请求{@code lowEndpoint}到{@code-successor(highEndpoint)}之间的子范围。----通俗就是区间,说的是subMap方法等。如:
m.subMap(low, high+"\0") //闭区间m.subMap(low+"\0", high) //开区间
sortedSet
/**
* A {@link Set} that further provides a <i>total ordering</i> on its elements.
* The elements are ordered using their {@linkplain Comparable natural
* ordering}, or by a {@link Comparator} typically provided at sorted
* set creation time. The set's iterator will traverse the set in
* ascending element order. Several additional operations are provided
* to take advantage of the ordering. (This interface is the set
* analogue of {@link SortedMap}.)
*
* <p>All elements inserted into a sorted set must implement the <tt>Comparable</tt>
* interface (or be accepted by the specified comparator). Furthermore, all
* such elements must be <i>mutually comparable</i>: <tt>e1.compareTo(e2)</tt>
* (or <tt>comparator.compare(e1, e2)</tt>) must not throw a
* <tt>ClassCastException</tt> for any elements <tt>e1</tt> and <tt>e2</tt> in
* the sorted set. Attempts to violate this restriction will cause the
* offending method or constructor invocation to throw a
* <tt>ClassCastException</tt>.
*
* <p>Note that the ordering maintained by a sorted set (whether or not an
* explicit comparator is provided) must be <i>consistent with equals</i> if
* the sorted set is to correctly implement the <tt>Set</tt> interface. (See
* the <tt>Comparable</tt> interface or <tt>Comparator</tt> interface for a
* precise definition of <i>consistent with equals</i>.) This is so because
* the <tt>Set</tt> interface is defined in terms of the <tt>equals</tt>
* operation, but a sorted set performs all element comparisons using its
* <tt>compareTo</tt> (or <tt>compare</tt>) method, so two elements that are
* deemed equal by this method are, from the standpoint of the sorted set,
* equal. The behavior of a sorted set <i>is</i> well-defined even if its
* ordering is inconsistent with equals; it just fails to obey the general
* contract of the <tt>Set</tt> interface.
*
* <p>All general-purpose sorted set implementation classes should
* provide four "standard" constructors: 1) A void (no arguments)
* constructor, which creates an empty sorted set sorted according to
* the natural ordering of its elements. 2) A constructor with a
* single argument of type <tt>Comparator</tt>, which creates an empty
* sorted set sorted according to the specified comparator. 3) A
* constructor with a single argument of type <tt>Collection</tt>,
* which creates a new sorted set with the same elements as its
* argument, sorted according to the natural ordering of the elements.
* 4) A constructor with a single argument of type <tt>SortedSet</tt>,
* which creates a new sorted set with the same elements and the same
* ordering as the input sorted set. There is no way to enforce this
* recommendation, as interfaces cannot contain constructors.
*
* <p>Note: several methods return subsets with restricted ranges.
* Such ranges are <i>half-open</i>, that is, they include their low
* endpoint but not their high endpoint (where applicable).
* If you need a <i>closed range</i> (which includes both endpoints), and
* the element type allows for calculation of the successor of a given
* value, merely request the subrange from <tt>lowEndpoint</tt> to
* <tt>successor(highEndpoint)</tt>. For example, suppose that <tt>s</tt>
* is a sorted set of strings. The following idiom obtains a view
* containing all of the strings in <tt>s</tt> from <tt>low</tt> to
* <tt>high</tt>, inclusive:<pre>
* SortedSet<String> sub = s.subSet(low, high+"\0");</pre>
*
* A similar technique can be used to generate an <i>open range</i> (which
* contains neither endpoint). The following idiom obtains a view
* containing all of the Strings in <tt>s</tt> from <tt>low</tt> to
* <tt>high</tt>, exclusive:<pre>
* SortedSet<String> sub = s.subSet(low+"\0", high);</pre>
*
* <p>This interface is a member of the
* <a href="{@docRoot}/../technotes/guides/collections/index.html">
* Java Collections Framework</a>.
*
* @param <E> the type of elements maintained by this set
*
* @author Josh Bloch
* @see Set
* @see TreeSet
* @see SortedMap
* @see Collection
* @see Comparable
* @see Comparator
* @see ClassCastException
* @since 1.2
*/NavigableMap
- 用Navigation方法扩展的{@link SortedMap},返回给定搜索目标的最接近匹配项。方法{@code lowerEntry}、{@code floorEntry}、{@code ceilingEntry}和{@code higherEntry}返回{@code Map.Entry}对象分别与小于、小于或等于、大于或等于和大于给定的key关联,如果没有这样的key,则返回{@code null}。类似地,方法{@code lowerKey}、{@code floorKey}、{@code ceilingKey}和{@code higherKey}只返回关联的key。所有这些方法都是为定位而不是遍历entries而设计的
- {@code NavigableMap}可以按升序或降序key访问和遍历。{@code desceptingmap}方法 returns a view of the map with the senses of all relational and directional methods inverted。升序的性能比降序更快。方法{@code subMap}、{@code headMap}和{@code tailMap}和{@code SortedMap}方法的不同在接受额外的参数,这些参数描述下界和上界是包含的还是互斥的。任何{@code NavigableMap}的subMaps必须实现{@code NavigableMap}接口。
- 此接口还定义了方法{@code firstEntry}、{@code pollFirstEntry}、{@code lastEntry}和{@code pollLastEntry},这些方法return and/or remove the least and greatest mappings(如果存在),否则返回{@code null}
- entry-returning的方法实现预期return MapEntry,代表在生成mapping的快照,因此,通常不支持可选的Entry.setValue方法,但可以使用put方法改变关联map中的mappings
- 方法{@link#subMap(Object,Object)subMap(K,K)}、{@link#headMap(Object)headMap(K)}和{@link}tailMap(Object)tailMap(K)}返回{@code SortedMap},使得{@code SortedMap}的实现可以进行兼容改造去 implement NavigableMap,但是此接口的扩展和实现是鼓励重写这些方法以返回{@code NavigableMap}。类似地,{@link#keySet()}可以被重写以返回{@code NavigableSet}。
转载了这三篇文章还不错:ArrayList动态扩容,java中的fail-fast(快速失败)机制和红黑树
其中红黑树了解其性质
- 性质1:每个节点要么是黑色,要么是红色。
- 性质2:根节点是黑色。
- 性质3:每个叶子节点(NIL)是黑色。
- 性质4:每个红色结点的两个子结点一定都是黑色。
- 性质5:任意一结点到每个叶子结点的路径都包含数量相同的黑结点。
从性质5又可以推出:
- 性质5.1:如果一个结点存在黑子结点,那么该结点肯定有两个子结点
注意:了解红黑书的增删改查,左右旋
NavigableMap接口,一系列的导航方法。比如返回有序的key集合。
Cloneable接口,克隆。
Serializable接口,序列化。
ArrayList
--- 线程不安全数组
---扩容
- 没有设置时默认是10
- 超过容量,进行1.5倍扩容
- 如还是不够,则用需要容量进行扩容
- 超过数组最大容量,Integer的最大值扩容
Vector
--- 线程安全,方法用了synchronized
---扩容 2倍扩容
LinkedList
---链表
---提供了 List 接口中没有定义的方法,专门用于操作表头和表尾元素,可以当作堆 栈、队列和双向队列使用
Set底层用Map实现
hash表专用词:
- 容量(capacity):hash表中桶的数量
- 初始化容量(initial capacity):创建hash表时桶的数量,HashMap允许在构造器中指定初始化容量
- 尺寸(size):当前hash表中记录的数量
- 负载因子(load factor):负载因子等于“size/capacity”。负载因子为0,表示空的hash表,0.5表示半满的散列表,依此类推。轻负载的散列表具有冲突少、适宜插入与查询的特点(但是使用Iterator迭代元素时比较慢)
- 负载极限:默认值(0.75),负载极限”是一个0~1的数值,“负载极限”决定了hash表的最大填满程度。当hash表中的负载因子达到指定的“负载极限”时,hash表会自动成倍地增加容量(桶的数量),并将原有的对象重新分配,放入新的桶内,这称为rehashing。
- Entry 就是链表节点,Entry 包含四个属性:key, value, hash 值和用于单向链表的 next
HashMap (适用于在Map中插入、删除和定位元素。)
---线程不安全,key还是value都可以为null
---哈希表(数组加链表),初始size = 16,扩容 new = oldsize*2
---计算index:index = hash & (tab.length – 1)
---实现Map接口(是Dictionary替代)
--- 扩容的阈值 threshold 的计算公式是:capacity * loadFactor,一旦达到阈值就会扩容
初始化小技巧
public HashSet(Collection<? extends E> c) {
// 对 HashMap 的容量重新进行了计算
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
用 (int)(c.size()/.75f) + 1 来表示初始化的值,这样使我们期望的大小值正好比扩容的阈值还大 1,就不会扩容,符合 HashMap 扩容的公式。
道理:要很好的组合 api 接口,并没有那么简单,我们可能需要去了解一下被组合的 api 底层的实现,这样才能用好 api。
如何给 HashMap 初始化大小?
Max(期望的值 / 0.75 + 1, 默认值 16)
HashTable
---线程安全,key还是value都不可以为null
---哈希表(数组加链表),初始size = 11,扩容 new = oldsize*2+1
---计算index:index = (hash & 0x7FFFFFFF) % tab.length
---实现Dictionary(像查字典一样,根据key找value)
ConcurrentHashMap
- 底层采用分段(Segment)的数组+链表+红黑树实现,线程安全
- 可以理解为是HashTable的升级版,但是由HashMap基础上升级的,效率更快,因为锁的是Segment
- 默认并发数16
TreeMap(适用于按自然顺序或自定义顺序遍历键(key)。)
- LinkedHashMap 是基于元素进入集合的顺序或者被访问的先后顺序排序,TreeMap 则是基于元素的固有顺序 (由 Comparator 或者 Comparable 确定)。
- 底层红黑树实现
- 线程不安全
Set最重要就是元素唯一性
HashSet
- HashSet的唯一性则是通过重写hashCode()方法和equal()方法实现的。HashSet 存储元素的顺序并不是按照存入时的顺序(和 List 显然不同) 而是按照哈希值来存的所以取数据也是按照哈希值取得。元素的哈希值是通过元素的hashcode 方法来获取的, HashSet 首先判断两个元素的哈希值,如果哈希值一样,接着会比较equals 方法 如果 equls 结果为 true ,HashSet 就视为同一个元素。如果 equals 为 false 就不是同一个元素。例如:HashSet的add方法的putVal方法,前半部分是当添加一个元素(key)时,计算key的hash值,首先第一个if判断哈希表是否为空,为空则初始化哈希表;如果不为空,则判断该哈希值在哈希表中对应数组位置是否为空,为空的话直接插入;如果不为空,则判断key值是否相同,相同的替换掉旧节点,不同则判断是否树化,树化就按树的方式进行存储,没有树化就按链表的方式进行存储
- JDK8之后,哈希表是由于“数组+链表+红黑树”实现的
TreeSet
- TreeSet()根据其元素的自然排序进行排序,需要实现Comparable接口,并覆盖其compareTo方法。
- TreeSet(Comparator comparator):根据指定的比较器进行排序,则需要实现Comparator接口,并重写其compare方法。
- 如:Integer,String已经实现实现Comparable接口,添加是可以直接添加
- TreeSet 的 add 方法,直接是TreeMap的put,TreeSet的迭代,是用TreeMap中的KeySet类去迭代,即TreeSet 定义了自己想要的 api,自己定义接口规范,让 TreeMap 去实现。参考这篇
LinkHashSet
- 继承与 HashSet,又基于 LinkedHashMap 来实现的
- LinkedHashSet 底层使用 LinkedHashMap 来保存所有元素,它继承与 HashSet,其所有的方法 操作上又与 HashSet 相同,因此 LinkedHashSet 的实现上非常简单,只提供了四个构造方法,并 通过传递一个标识参数,调用父类的构造器,底层构造一个 LinkedHashMap 来实现,在相关操 作上与父类 HashSet 的操作相同,直接调用父类 HashSet 的方法即可
泛型(指定参数化类型)
1.安全性
提前检测隐藏不能强转和赋值(set时)不安全行为
2.可擦除性
泛型信息可以在运行时被擦除,泛型在编译期有效,在运行期被删除,也就是说所有泛型参数类型在编译后都会被清除掉。归根结底不管泛型被参数具体化成什么类型,其class都是RawType.class,比如List.class,而不是List<String>.class或List<Integer>.class,即二者List<String>==List<Integer>
通配符介绍
无边界通配符 ?
上界通配符 ? extends xxx
下界通配符 ? super xxx (如: ? super Integer 代表从Interger到Object所有对象都是可以的)
Java泛型中的标记符含义:
E - Element (在集合中使用,因为集合中存放的是元素)
T - Type(Java 类)
K - Key(键)
V - Value(值)
N - Number(数值类型)
? - 表示不确定的java类型
S、U、V - 2nd、3rd、4th types
Object跟这些标记符代表的java类型区别
Object是所有类的根类,任何类的对象都可以设置给该Object引用变量,使用的时候可能需要类型强制转换,但是用使用了泛型T、E等这些标识符后,在实际用之前类型就已经确定了,不需要再进行类型强制转换。
用法:(参考https://www.cnblogs.com/jian0110/p/10690483.html,虽然目前不是很懂,先记下来)
1.递归类型限制(recursive type bound):通过某个包含该类型本身的表达式来限制类型参数,最普遍的就是与Comparable一起使用。比如<T extends Comparable<T>>
public interface Comparable<T> {
public int compareTo(T o);
}类型参数T定义的类型,可以与实现Comparable<T>的类型进行比较,实际上,几乎所有类型都只能与它们自身类型的元素相比较,比如String实现Comparable<String>,Integer实现Comparable<Integer>
类型安全的异构容器
泛型一般用于集合,如Set和Map等,这些容器都是被参数化了(类型已经被具体化了,参数个数已被固定)的容器,只能限制每个容器只能固定数目的类型参数,比如Set只能一个类型参数,表示它的元素类型,Map有两个参数,表示它的键与值。
但是有时候你会需要更多的灵活性,比如关系数据库中可以有任意多的列,如果以类型的方式所有列就好了。有一种方法可以实现,那就是使用将键进行参数化而不是容器参数化,然后将参数化的键提交给容器,来插入或获取值,用泛型来确保值的类型与它的键相符。
我们实现一个Favorite类,可以通过Class类型来获取相应的value值,键可以是不同的Class类型(键Class<?>参数化,而不是Map<?>容器参数化)。利用Class.cast方法将键与键值的类型对应起来,不会出现 favorites.putFavorite(Integer.class, "Java") 这样的情况。
/**
* @author jian
* @date 2019/4/1
* @description 类型安全的异构容器
*/
public class Favorites {
private Map<Class<?>, Object> favorites = new HashMap<>();
public <T> void putFavorite(Class<T> type, T instance){
if (type == null) {
throw new NullPointerException("Type is null");
}
favorites.put(type, type.cast(instance));
}
public <T> T getFavorite(Class<T> type){
return type.cast(favorites.get(type));
}
}
Favorites实例是类型安全(typesafe)的,你请求String时,不会返回给你Integer,同时也是异构(heterogeneous)的,不像普通map,它的键都可以是不同类型的。因此,我们将Favorites称之为类型安全的异构容器(typesafe heterogeneous container)。
public static void main(String[] args) {
Favorites favorites = new Favorites();
favorites.putFavorite(String.class, "Java");
favorites.putFavorite(Integer.class, 64);
favorites.putFavorite(Class.class, Favorites.class);
String favoriteString = favorites.getFavorite(String.class);
Integer favoriteInteger = favorites.getFavorite(Integer.class);
Class<?> favoriteClass = favorites.getFavorite(Class.class);
// 输出 Java 40 Favorites
System.out.printf("%s %x %s%n", favoriteString, favoriteInteger, favoriteClass.getSimpleName());
}Favorites类局限性在于它不能用于在不可具体化的类型中,换句话说你可以保存String,String[],但是你不能保存List<String>,因为你无法为List<String>获取一个Class对象:List<String>.class是错误的,不管是List<String>还是List<Integer>都会公用一个List.class对象。
List<String> list = Arrays.asList("1","2");
List<Integer> list2 = Arrays.asList(3,4);
// 只能选一种,不能有List<String>.class或者List<Integer>.class
favorites.putFavorite(List.class, list2);
// favorites.putFavorite(List.class, list)注:方法的泛型有两种:
实体方法
实体方法可以使用在类中定义的泛型或者方法中定义的泛型.
静态方法
不可以使用在类中定义的泛型,只能使用在静态方法上定义的泛型.


















 1402
1402



 到【灌水乐园】发言
到【灌水乐园】发言







