




 本文深入探讨了编码概念,包括ASCII、Unicode、UTF-8、GBK等,讲解了URL编码与HTML实体的作用,以及Python中u、b、r、f前缀的含义。同时,详细介绍了encode和decode函数的使用方法。
本文深入探讨了编码概念,包括ASCII、Unicode、UTF-8、GBK等,讲解了URL编码与HTML实体的作用,以及Python中u、b、r、f前缀的含义。同时,详细介绍了encode和decode函数的使用方法。
文章目录
写在前面
本文截图中使用的编程语言:python
1、编码
1.1、ASCII
“美标”编码。里面包含了数字、字母、符号等。

中国人利用连续2个扩展ASCII码的扩展区域(0xA0以后)来表示一个汉字,该方法的标准叫GB-2312。后来,日文、韩文、阿拉伯文、台湾繁体(BIG-5)…都使用类似的方法扩展了本地字符集的定义,现在统一称为 MBCS 字符集(多字节字符集)。这个方法是有缺陷的,因为各个国家地区定义的字符集有交集,因此使用GB-2312的软件,就不能在BIG-5的环境下运行(显示乱码),反之亦然。
1.2、Unicode
Unicode (统一码)它为每种语言中的每个字符设定了统一并且唯一的二进制编码。
我们经常看到的 \u 后面接字符的就是 Unicode 编码
程序中出现字符串的地方加前缀u,表示为unicode类型
1.3、UTF-8
UTF-8是互联网上使用最广的一种Unicode的实现方式, 原理很简单,简单来说就是加了符号位,通过符号位的数字判断是几个字节,这样就不浪费空间了。(记住它只是unicode一种实现方式)
我们经常看到的 \x 后面接字符的就是 UTF-8 编码

实际表示ASCII字符的UNICODE字符,将会编码成1个字节,并且UTF-8表示与ASCII字符表示是一样的。所有其他的UNICODE字符转化成UTF-8将需要至少2个字节。
1.4、GBK
GBK全称《汉字内码扩展规范》即“国标”。完全兼容ASCII字符编码、Unicode 编码。
1.5、URL编码
参考文章:https://blog.youkuaiyun.com/p312011150/article/details/78928003
Url编码通常也被称为百分号编码,
它的编码方式非常简单,使用%百分号加上两位的字符——0123456789ABCDEF——代表一个字节的 十六进制形式。
Url编码默认使用的字符集是US-ASCII。例如a在US-ASCII码中对应的字节是0x61,那么Url编码之后得到的就 是%61。
URL编码的方式是把需要编码的字符转化为 %xx 的形式。通常 URL 编码是基于 UTF-8 的(当然这和浏览器平台有关)。
例子:
比如『我』,unicode 为 0x6211, UTF-8 编码为 0xE6 0x88 0x91,URL 编码就是
%E6%88%91
在 JavaScript 中,提供了 encodeURI 和 encodeURIComponent 两种方法对 URL 进行编码;
Python 的 urllib 库中提供了 quote 和 quote_plus 两种方法。
python3里url编码:urllib.parse.quote(“中文”)进行编码
python3里url解码:urllib.parse.unquote(’%e4%b8%ad%e6%96%87’)
1.6、HTML实体
参考源:https://blog.youkuaiyun.com/phpdadao/article/details/22871559
在html文档中以&#开头的就是HTML实体
汉字的HTML实体由三部分组成,”&#+ASCII+;“
例如,把“最新” 转换成“最新”
浏览器可以直接把html实体转成中文显示,js:
$text = mb_convert_encoding($text, "GBK", "HTML-ENTITIES");
python:

2、python字符前面的u、b、r、f
2.1、u
解释字符前面的u前先明白 Python中字符串类型分为byte string 和 unicode string两种。
引用文章:https://blog.youkuaiyun.com/use_my_heart/article/details/51303317
| string | 解释 |
|---|---|
| byte string | 已编码字符,python里所有已定义字符默认是byte string ,例如:mystr=“你好” |
| unicode string | 未编码字符,由函数产生的字符被认为是unicode string,例如:request.get(“argu”) |
- 如果在python文件中指定(#coding=utf-8),那么所有带中文的字符串都会被认为是utf-8编码的byte string(例如:mystr=“你好”),由函数产生的被认为是unicode string。
- unicode string 和 byte string 是不可以混合使用,一旦混合使用了,就会产生这样的错误。例如: self.response.out.write(“你好”+self.request.get(“argu”))
其中,“你好"被认为是byte string,而self.request.get(“argu”)的返回值被认为是unicode string。由于预设的解码器是ascii,所以就不能识别中文byte string。然后就报错了。
以下有两个解决方法:
1.将字符串全都转成byte string。
self.response.out.write(“你好”+self.request.get(“argu”).encode(“utf-8”))
2.将字符串全都转成unicode string。
self.response.out.write(u"你好”+self.request.get(“argu”))
byte string转换成unicode string可以这样转unicode(unicodestring, “utf-8”)
unicode string:
以unicode作为编码表(信源编码),仅仅代表一个字符,未存储,因此未被编码。从函数中返回的字符都是unicode string,因为未存储,所以未被编码。
byte string(即python中的str类型):
以unicode作为编码表(信源编码),以utf8作为信道编码,一个中文字符对应三个字节。从文件读取的字符,因为已经存在磁盘中,因此都是byte string。python文件中初始化的字符串,也是byte string,因为.py文件本身就是存在硬盘中的。
在python里,字符前面带u表示unicode string,在通常情况下,字符串前面带u和不带u效果一样

2.2、b
Python3的字符串的编码语言用的是unicode编码,由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干字节,如果要在网络上传输,或保存在磁盘上就需要把str变成以字节为单位的bytes

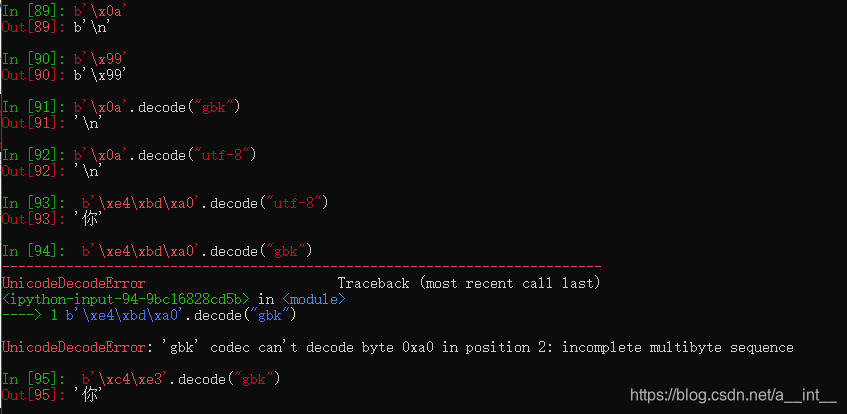
带有b开头的字符默认只能只能包含ASCII字符,在打印bytes字符串时,某些正常字符和一些转义字符可以打印出来,比如:字母数字和‘\n’换行符。别的可以通过decode转化。
2.3、r
‘r’是防止字符转义的 如果路径中出现’\t’的话 不加r的话\t就会被转义。
以r开头的字符,常用于正则表达式,对应着re模块。
2.4、f
f/format():格式化操作。

参考教程:https://www.runoob.com/python/att-string-format.html
>>>"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序
'hello world'
>>> "{0} {1}".format("hello", "world") # 设置指定位置
'hello world'
>>> "{1} {0} {1}".format("hello", "world") # 设置指定位置
'world hello world'
>>> print("{:.2f}".format(3.1415926));
3.14
3、encode、decode
encode:编码,是将unicode编码转换成其他编码的字符串,如str.encode('gb2312'),表示将unicode编码的字符串str转换成gb2312编码。
decode:解码,是将其他编码的字符串转换成unicode编码,如str.decode('gb2312'),表示将gb2312编码的字符串str转换成unicode编码。
字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
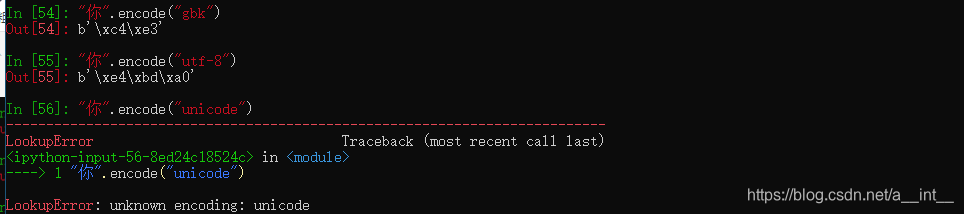
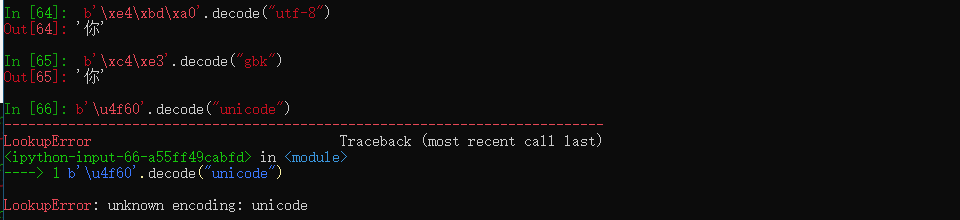
这里我们可以看到unicode在python里并不是一种编码方法,所有unicode编码都是通过utf-8来具体实现的
bytes转字符串方式一
b=b’\xe9\x80\x86\xe7\x81\xab’
string=str(b,‘utf-8’)
bytes转字符串方式二
b=b’\xe9\x80\x86\xe7\x81\xab’
string=b.decode() # 第一参数默认utf8,第二参数默认strict
bytes转字符串方式三
b=b’\xe9\x80\x86\xe7\x81haha\xab’
string=b.decode(‘utf-8’,‘ignore’) # 忽略非法字符,用strict会抛出异常
bytes转字符串方式四
b=b’\xe9\x80\x86\xe7\x81haha\xab’
string=b.decode(‘utf-8’,‘replace’) # 用?取代非法字符
字符串转bytes方式一
str=‘逆火’
b=bytes(str1, encoding=‘utf-8’)
字符串转bytes方式二
str=‘逆火’
b=str.encode(‘utf-8’)

















 206
206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









