






思路:
是数字,不太好用计数数组。用unordered_set去重。用范围for
std::set和std::multiset底层实现都是红黑树,std::unordered_set的底层实现是哈希表, 使用unordered_set 读写效率是最高的,并不需要对数据进行排序,而且还不要让数据重复,所以选择unordered_set。
那有同学可能问了,遇到哈希问题我直接都用set不就得了,用什么数组啊。
直接使用set 不仅占用空间比数组大,而且速度要比数组慢,set把数值映射到key上都要做hash计算的。
不要小瞧 这个耗时,在数据量大的情况,差距是很明显的。
所以要考虑unordered_set
三种数据结构的底层:
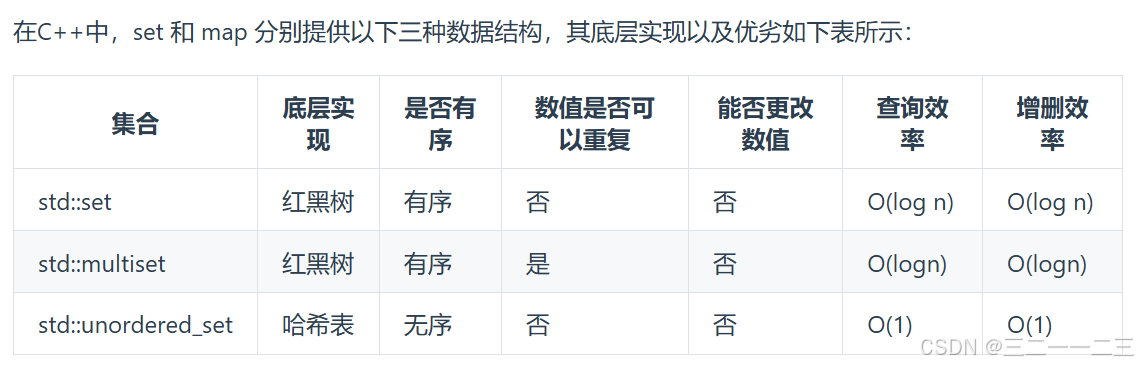
std::unordered_set底层实现为哈希表,std::set 和std::multiset 的底层实现是红黑树.
红黑树是一种平衡二叉搜索树,所以key值是有序的。
但key不可以修改,改动key值会导致整棵树的错乱,所以只能删除和增加。
unordered_map,map,multimap也是类似的底层。
储备:
问题重点:
1、
注意容器的应用。范围for,迭代器初始化,临时容器,等等。
最后:
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> res;
unordered_set<int> nums(nums1.begin(),nums1.end());//用迭代器,换个容器存储
//用范围for遍历容器
for (int i:nums2) {
if (nums.find(i)!=nums.end()) {//找得到的话
res.insert(i);
}
}
return vector<int>(res.begin(),res.end());//临时容器。
}
};
















 483
483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









