






 本文探讨大数据测试的范围,借鉴ISO9126软件质量模型,关注大数据的功能性(数据全面性、完整性、合理性、准确性、安全性)、易用性(数据获取的便捷性、指标理解)以及可靠性与效率(数据恢复性、容错性、资源管理)。在大数据处理中,测试人员需验证数据的完整性和准确性,同时确保数据的安全,以及平台在面对异常时的恢复能力和资源利用效率。
本文探讨大数据测试的范围,借鉴ISO9126软件质量模型,关注大数据的功能性(数据全面性、完整性、合理性、准确性、安全性)、易用性(数据获取的便捷性、指标理解)以及可靠性与效率(数据恢复性、容错性、资源管理)。在大数据处理中,测试人员需验证数据的完整性和准确性,同时确保数据的安全,以及平台在面对异常时的恢复能力和资源利用效率。
小伙伴们对传统测试已经非常熟悉了,从测试手段来区分:功能测试、性能测试、自动化测试、安全测试、接口测试就有多种。
那么大数据测试到底测啥以及如何测,非常遗憾的告诉伙伴们,目前业界没有通用的方法定义大数据测试,本篇借鉴传统测试的思想跟大伙一起探讨下大数据测试的范围。
目录如下
1、传统测试范围的定义
2、大数据的功能性与易用性
3、大数据的可靠性与效率
1 传统测试范畴的定义
ISO9126软件质量模型标准定义了软件评估的6大特性分别是:功能性、易用性、可靠性、效率性、可维护性、可移植性,也就意味着软件测试基本上围绕着这6个特性展开,详情见:
ISO9126软件质量模型的六大特性
2 大数据的功能性与易用性
我们借鉴ISO9126软件质量模型,看看大数据的功能性、易用性需考虑方面
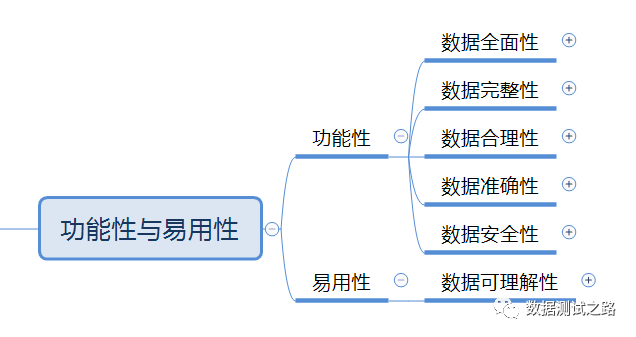
2.1 功能性
说明:ISO9126 里面指满足需求文档和相关标准能力,分别从适合性、准确性、互操作性、保密安全性、功能的依从性去定义,好比测试一台手机:确保它功能完整(能打电话、发短信、运行app、拍照..),满足用户日常的需求,并且符合互操作性(确保打电话的时能运行手机上的app),发出去的短信传输过程是通过加密、安全的,并且该手机的功能在国际上具备一定的规范一致性
对比:这里我们将其进行迁移到数据测试上,例:公司通过爬虫获取到友商的一些数据,作为测试人员可以尝试考虑这些方面:
2.2 数据全面性
质疑下拿到的爬虫数据对应的友商是否全面,
除了友商A的数据应该获取,友商B、C、D的数据是否有考虑
每个友商选取的对标门店是否具有代表性,需考虑
通常在需求评审阶段提出
2.3 数据完整性
质疑拿到的数据是否完整,这里完整指:
数据确保指定时间范围内每天有数据,排除被风控了的情况
数据是否重复,例:同1条URL对应2条结果数据
数据预期与结果总条数一致
通常在etl测试阶段考虑
2.4 数据合理性
质疑拿到的数据是否符合数据库规定类型、以及是否出现出现异常值
字段类型check,如对重要字段类型check,例:int型下出现其他字符类型情况
字段异常值check,例:null、空、或者另外一些约定异常值
字段默认值一致性验证check,例: 从A表同步到B表后,某字段枚举值含义相同
在etl测试阶段 或者 数据应用层测试考虑
2.5 数据准确性
质疑拿到数据的结果表与数据源头表是否一致,可能源表经过A -> B -> C处理后得到结果表,所以需要验证整个过程数据是否失真,确保数据的准确与一致
基于总数的验证,即 A -> B -> C后总数一致,可能到C后有聚合的数据,视情况而定,即在A时有10万条数据,到C阶段理论也有10万。
基于总数额的验证,即 A -> B -> C后总额一致,这里的总额可能是:金额、销量等。
在etl测试阶段 或者 数据应用层测试考虑
2.6 安全性验证

对于某些敏感的数据往往需要考虑其安全性,可以是从获取数据的方式,也可以是数据本身安全性上。
账号的隔离,测评是否有必要采用账号隔离访问数据
基于对某些数据字段,测评是否有必要对某些字段进行加密考虑,例:身份证、家庭住址、金钱等方面的加密
在需求评审阶段考虑
2.7 易用性验证
确保数据获取的过程顺畅,如果数据需要通过很多命令执行并且连接多个环境才能获取到,这样的数据易用性则不强,以及每个指定的一定能被人所理解。
数据获取的交互是否过于复杂
数据对应的指标能被人所理解,例:MAU-月活人数、DAU-日活人数
在需求评审阶段 或 研发设计阶段考虑
3 大数据的可靠性与效率
同样的当处理大数据的平台出现不可预知的错误时,或者数据处理变慢时,我们得有一些处理方案让其能短时间内恢复,或者即便恢复不了也有一些应急的方案,让其不影响到整个链路的上下游,这里其实就是对处理大数据的平台可靠性与效率性的保证。
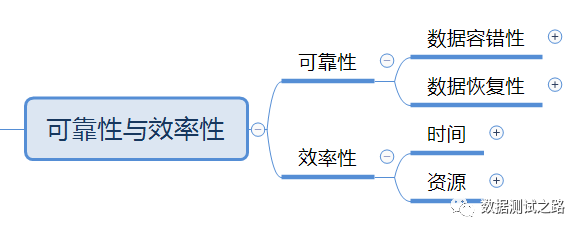
数据恢复性,当平台出现异常时,可以有一些重试机制进行重试,确保系统短时间内能恢复。
数据容错性,即便通过重试机制不能恢复时,需保证上游数据不能影响到下游的数据,可以有一些默认数据的预置,确保下游总能获取到数据。
时间与资源,当平台运算资源紧张任务繁重的时候,可能会出现长时间的等待,这时候除了需要跟研发一起优化SQL线程,还需要设计一些交互展示一些页面给用户,减少等待带来的用户体检差的问题
4 大数据的可维护性与可移植性
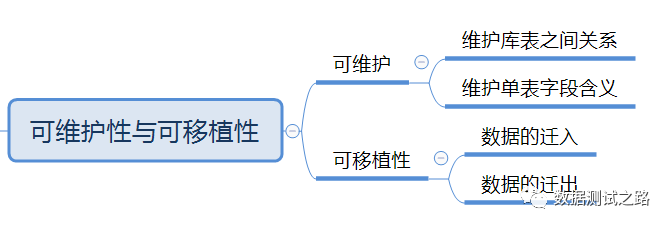
可维护性指:数据可用且及时被维护,可移植性指:无论数据的迁入与迁出都不会影响到数据的使用
维护库表之间关系,由于通常大数据随着时间的推移数据库表会越来越多,需要确保有地方能维护数据库表之间的关系。
维护单表字段含义,例:某天业务上新定义销售类型,那么需要在对应的表内注解出及时维护。
数据的迁入/迁出:确保数据迁入/迁出字段不丢失以及数据完整性(参考2.3 数据完整性)
--end--
扫描下方二维码
添加好友,备注【交流群】
拉你到学习路线和资源丰富的交流群


















 820
820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









