






 本文详细介绍了SQL语句的分类及用途,包括DDL、DML、DQL、TPL和DCL等,重点讲解了DDL语句中的create、alter和drop操作,并通过实例说明了如何创建、编辑和删除数据库对象。
本文详细介绍了SQL语句的分类及用途,包括DDL、DML、DQL、TPL和DCL等,重点讲解了DDL语句中的create、alter和drop操作,并通过实例说明了如何创建、编辑和删除数据库对象。
SQL 语句分类
DDL:数据定义语句,提供database、table的创建、编辑、删除等功能
- create,创建库、表、储存过程等
- alter,编辑表结构
- drop,删除库、表、储存过程等
DML:数据操作语句,提供数据的插入、删除、编辑等功能
- insert:插入数据
- updata:更新数据
- delete: 删除数据
DQL:数据查询语句,提供数据查询功能
- select:查询数据
TPL:事务控制语句,提交事务的提交、回滚等操作
- commit:提交事务
- rollback:回滚事务
- save point 设置保存点
DCL:数据空值语句,提供权限管理功能
- grant: 授权
DDL 语句
create 语句
创建库
语法:create database [if not exists] name [default charset=字符集 default collate 字符集校对规则]
[if not exists],可选的,如果指定的name存在则不创建
name,库名,尽量使用有意义的英文单词
[default charset=字符集 default collate 字符集校对规则],可选的,用于指定字符集和字符集校对规则。常用的字符集为-utf8,字符集校对规则-utf8_general_ci
例:创建库,并且指定字符集
create database if not exists class_87 default charset="utf8" default collate utf8_general_ci;
创建表
语法:create table [if not exists] name(属性1 数据类型 [约束],......) [engine=存储引擎] [charset=字符集 collate=字符集校对规则];
[if not exists],可选的,如果指定的name存在则不创建
- name,表名名,尽量使用有意义的英文单词
- 属性: 尽量使用有意义的英文单词
- 数据类型
- 数值型,整数、小数
- 字符串
- char(len),定长,效率高
- varchar(len),变长,节约存储空间
- 日期时间:datetime(YYYY-MM-DD H:M:S)、date
-
约束
-
主键约束 :
primary key,不能重复,不能为空- 列级:
属性 数据类型 primary key- 例:
student_no char(8) primary key
- 例:
- 表级:在所有的属性声明完成后使用关键字
constraint声明主键-
例1:
constraint pk_stno primary key(student_no) -
例2:多个属性组合为主键,比如成绩表(使用学号+课程号作为主键)
constraint pk_stno primary key(student_no,course_no)
-
- 列级:
-
外键约束:
foreign key,引用其他表属性的数据- 语法:
constraint name foreign key 表1(属性) references 表2(属性),表示在表1的指定属性上创建外键(名字为name),引用表2的指定属性的值 - 级联删除:
on delete cascade,如果被引用表中的数据被删除,则当前表中相关数据也会同时删除 - 级联修改:
on update cascade,如果被引用表中的数据被修改,则当前表中相关数据也会同时修改 - 如果引用的是主表的非主键属性,需要为该属性设置索引—index(属性)
- 例1:
constraint fk_sc foreign key score(course_no) references course(course_no)
使用级联删除与修改,使score表中的数据保持与course表一致
constraint fk_sc foreign key score(course_no) references course(course_no) on delete cascade on update cascade - 语法:
-
-
例2:
# 商品表
create table product(
pro_no char(4) primary key, -- 商品编号,主键
pro_name varchar(200), -- 商品名称
pro_count int, -- 商品数量
pro_price float(7,2), -- 商品单价
index(pro_name) -- 添加索引
)engine=INNODB;
insert into product values('1001','aaa',100,9.9); --插入一行数据
# 销售表
create table sale(
id int primary key, -- 编号,主键
pro_no char(4), -- 商品编号,外键,引用商品表的pro_no字段
pro_name varchar(200), -- 商品名称,外键,引用商品表的pro_name字段
sale_count int, -- 销售数量
-- 在pro_name上创建外键,引用product表的pro_name属性值,使用级联删除和修改保持数据一致
constraint fk_no foreign key sale(pro_no) references product(pro_no) on delete cascade on update cascade,
constraint fk_name foreign key sale(pro_name) references product(pro_name) on delete cascade on update cascade
)engine=INNODB;
insert into sale values(1,'aaa',10); – 插入数据,不能插入product表中pro_name不存在的数据
– 当product表中的数据发生变动时,sale表中的数据会跟随同时变化
-
非空约束:
not null,限制指定属性不能为空例:
# 商品表
create table product(
pro_no char(4) primary key, -- 商品编号,主键
pro_name varchar(200) not null, -- 商品名称,指定不能为空
pro_count int, -- 商品数量
pro_price float(7,2), -- 商品单价
index(pro_name) -- 添加索引
)engine=INNODB;
insert into product values('1001','aaa',100,9.9); --插入一行数据
-
唯一约束:
unique,限制指定属性的值不能重复例:
# 商品表
create table product(
pro_no char(4) primary key, -- 商品编号,主键
pro_name varchar(200) not null, -- 商品名称,指定不能为空
pro_count int, -- 商品数量
pro_price float(7,2), -- 商品单价
pro_code char(10) unique, -- 商品条码,指定不能重复
index(pro_name) -- 添加索引
)engine=INNODB;
insert into product values('1001','aaa',100,9.9); --插入一行数据
-
自增长:
auto_increment,设定指定属性值自增长(默认从1开始)设置为自增长的属性必须设置为主键,所有一张表中只能为1个属性设置自增长
例:
# 商品表
create table product(
id int primary key auto_increment, -- 序号,主键,设置为自增长
pro_no char(4) not null, -- 商品编号,主键
pro_name varchar(200) not null, -- 商品名称,指定不能为空
pro_count int, -- 商品数量
pro_price float(7,2), -- 商品单价
pro_code char(10) unique, -- 商品条码,指定不能重复
index(pro_name) -- 添加索引
)engine=INNODB;
# 插入数据时id属性会自动填入相关序号
insert into product(pro_no,pro_name,pro_count,pro_price,pro_code)
values('1003','aaa',100,9.9,'a123456789');
- 默认值:
default value, 指定属性的默认值-
默认值:
default value,指定属性的默认值在指定默认值时,必须放在其他约束的后面
-
# 商品表
create table product(
id int primary key auto_increment, -- 序号,主键,设置为自增长
pro_no char(4) not null, -- 商品编号,主键
pro_name varchar(200) not null, -- 商品名称,指定不能为空
pro_count int, -- 商品数量
pro_price float(7,2), -- 商品单价
pro_code char(10) unique default 'abc123', -- 商品条码,指定不能重复,默认值为abc123
index(pro_name) -- 添加索引
)engine=INNODB;
# 插入数据时id属性会自动填入相关序号
# 不为pro_code字段插入数据,此时会使用设定的默认值
insert into product(pro_no,pro_name,pro_count,pro_price)
values('1002','aaa',100,9.9);
-
检查约束:
check(条件),限制属性插入的数据必须符合指定的条件。例:
# 商品表
create table product(
id int primary key auto_increment, -- 序号,主键,设置为自增长
pro_no char(4) not null, -- 商品编号,主键
pro_name varchar(200) not null, -- 商品名称,指定不能为空
pro_count int check(pro_count<=100), -- 商品数量
pro_price float(7,2), -- 商品单价
pro_code char(10) unique default 'abc123', -- 商品条码,指定不能重复,默认值为abc123
index(pro_name) -- 添加索引
)engine=INNODB;
储存引擎
-
MyISAM引擎
这种引擎是mysql最早提供的,这种引擎又可以分为静态MyISAM、动态MyISAM 和压缩MyISAM三种:
(1)静态MyISAM:如果数据表中的各数据列的长度都是预先固定好的,服务器将自动选择这种表类型。因为数据表中每一条记录所占用的空间都是一样的,所以这种表存取和更新的效率非常高。当数据受损时,恢复工作也比较容易做。
(2)动态MyISAM:如果数据表中出现varchar、xxxtext或xxxBLOB字段时,服务器将自动选择这种表类型。相对于静态MyISAM,这种表存储空间比较小,但由于每条记录的长度不一,所以多次修改数据后,数据表中的数据就可能离散的存储在内存中,进而导致执行效率下降。同时,内存中也可能会出现很多碎片。因此,这种类型的表要经常用optimize table 命令或优化工具来进行碎片整理。
(3)压缩MyISAM:以上说到的两种类型的表都可以用myisamchk工具压缩。这种类型的表进一步减小了占用的存储,但是这种表压缩之后不能再被修改。另外,因为是压缩数据,所以这种表在读取的时候要先时行解压缩。
但是,不管是何种MyISAM表,目前它都不支持事务,行级锁和外键约束的功能。
2、MyISAM Merge引擎
这种类型是MyISAM类型的一种变种。合并表是将几个相同的MyISAM表合并为一个虚表。常应用于日志和数据仓库。
3、InnoDB引擎
InnoDB表类型可以看作是对MyISAM的进一步更新产品,它提供了事务、行级锁机制和外键约束的功能。
4、memory(heap)引擎
这种类型的数据表只存在于内存中。它使用散列索引,所以数据的存取速度非常快。因为是存在于内存中,所以这种类型常应用于临时表中。
5、archive引擎
这种类型只支持select 和 insert语句,而且不支持索引。常应用于日志记录和聚合分析方面。
alter语句
-
添加属性
语法:
alter table 表名 add 属性 数据类型 [约束];
create table test(
id int primary key auto_increment
)engine=INNODB;
alter table test add name varchar(20) not null; # 在test表中添加属性name,指定数据类型为varchar,不能为空
-
添加主键
alter table 表名 add primary key(字段列表) -
修改数据类型或者约束
语法:
alter table 表名 modify 属性名 数据类型 [约束];
create table test(
id int primary key auto_increment,
name varchar(20) not null
)engine=INNODB;
alter table test modify name varchar(50) not null default "张三";
-
删除属性
语法:
alter table 表名 drop 属性名 -
添加约束
语法:
alter table 表名 add 约束(属性名)
create table test(
id int primary key auto_increment,
name varchar(20) not null,
passwd char(32)
)engine=INNODB;
alter table test add unique(passwd);
-
删除约束
- 删除主键约束:
alter table 表名 drop primary key - 删除外键约束:
alter table 表名 drop foreign key 外键名
- 删除主键约束:
-
三范式
-
第一范式
原子性,表中的每一个属性都是不可再分的
-
第二范式
每一个非主属性都完全依赖于主属性
例:成绩表,使用学号+课程号作为主键
-
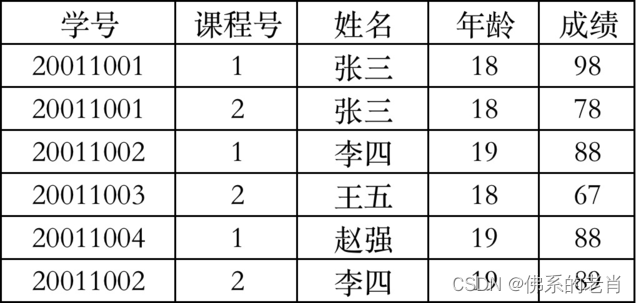
不满足第二范式,姓名、年龄部分依赖于主属性中的学号。这样的表存在数据冗余、更新异常等问题。
修改:分别创建学生表、成绩表
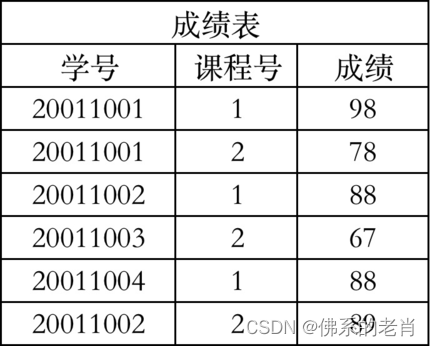
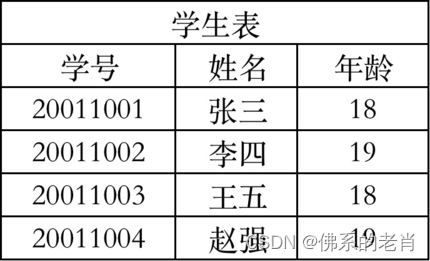
-
第三范式
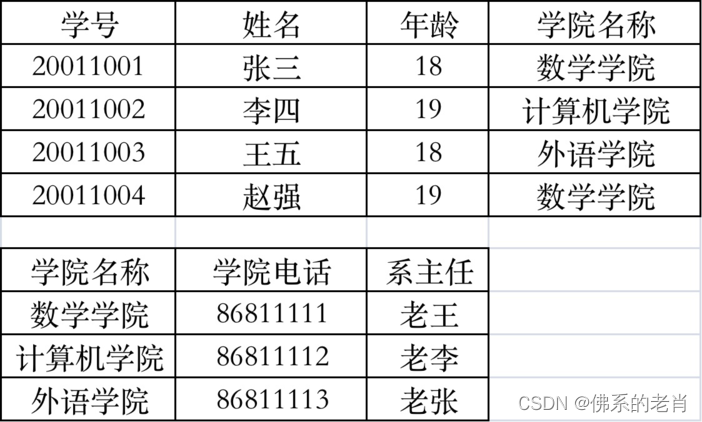
每一个非主属性都不传递依赖于主属性(B依赖于A,C依赖于B,则C传递依赖于A)
例:学生表,包含学号、姓名、学院名称、学院电话、系主任
| 学号 | 姓名 | 年龄 | 学院名称 | 学院电话 | 系主任 |
| 20011001 | 张三 | 18 | 数学学院 | 86811111 | 老王 |
| 20011002 | 李四 | 19 | 计算机学院 | 86811112 | 老李 |
| 20011003 | 王五 | 18 | 外语学院 | 86811113 | 老张 |
| 20011004 | 赵强 | 19 | 数学学院 | 86811111 | 老王 |
该学生表不满足第三范式,学院电话、系主任通过学院名传递依赖于主键学号,此时存在数据冗余、更新异常等问题。
drop语句
删除数据库中的库、表、存储过程、函数等
删除库:drop database 库名;
删除表:drop table 表名;


















 529
529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











