






 本文详细介绍了如何使用Hadoop和Pig脚本在集群上执行数据处理任务,包括本地数据文件的准备、上传至HDFS、编写Pig脚本以及执行脚本的过程。重点突出了数据文件的两次传递过程以及Pig脚本的上传方法。
本文详细介绍了如何使用Hadoop和Pig脚本在集群上执行数据处理任务,包括本地数据文件的准备、上传至HDFS、编写Pig脚本以及执行脚本的过程。重点突出了数据文件的两次传递过程以及Pig脚本的上传方法。
Step1:
我们要在本地创建一个存放数据的txt文件,我们命名为studentdata.txt里面存放的数据如下:
001:林:59
002:唐:100
003:施:61
004:王:78
005:张:76
006:李:52
Step2:
将本地创建的数据传到namenode下面,
先在我们的/mnt/tmp/下面创建一个input_tms目录,用来存放我们上传的文件
先cd 到/mnt/tmp目录下
然后mkdir input_tms
最后查看ls /mnt/tmp

然后cd到创建的目录下
cd /mnt/tmp/input_tms/

然后执行rz,上传我们的数据文档studentdata.txt
在弹出来的选择框中选择我们的文档studentdata.txt
点击打开,上传成功显示如下,点击关闭:
接下来将本地传入的在/mnt/tmp/input_tms下面的studentdat.txt传到HDFS中
先在hdfs下创建一个input_tms目录,这个目录和上面的那个不同,这里只是名字相同了便于管理,他用来接收我们传入的studentdata.txt。相当于本地的数据传了两次,一次到namenode下面,然后到hdfs系统里面
先cd回来
cd /

然后新建一个目录:input_tms
hadoop fs –mkdir /input_tms,这里显示已经存在,因为我之前就已经创建了。

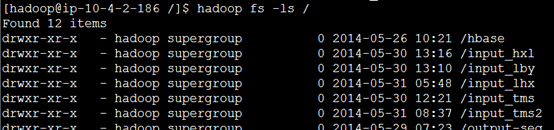
查看是否创建成功,看到我们的input_tms,表明成功
命令:hadoop fs –ls /
然后执行
hadoop fs –put /mnt/tmp/input_tms/studentdata.txt /input_tms ,传到HDFS系统中
第一个input_tms是上上面的,第二个input_tms是上一步创建的,注意!!!

然后查看是否传入成功
hadoop fs –ls /input_tms/ 看到我们的studentdata.txt表明成功

Step3:
本地创建一个Pig脚本,Pig脚本是以.pig结尾的,在这个例子中命名为tmspig.pig采用编辑器进行打开然后编辑,在里面写入脚本
A = load '/input_tms/studentdata.txt' using PigStorage(':') as (sno:chararray, sname:chararray, sscore:int);
B = foreach A generate sno, sscore;
dump B;
store B into '/input_tms/result.txt';
Ps:目前还没有具体研究过pig脚本的语法,但是大体的意思我们还是能看懂。他和studentdata.txt联系起来了通过一个URL.然后我们的结果输出是他们的号码sno和sscore
注意后面的类型,和上面我们传入的数据比较,字符串类型的是chararray,整形的就是int
然后将脚本文件传入到/mnt/tmp/input_tms/目录下,这里就不啰嗦了,将他和上面的studentdata.txt放在一起。
Pig脚本是不用传入到HDFS中去的,(开始我就传了,后面就错了!!!)
我们可以查看是否成功的把我们的脚本传入了
cd /mnt/tmp/input_tms/
然后 ls

这个时候看到我们的/mnt/ymp/input_tms/目录下面有两个文件了,一个是studentdata.txt,一个是我们本地的pig脚本tmspig.pig
Step4执行我们的脚本,语言,就一句话
pig /mnt/tmp/input_tms/tmspig.pig

然后就是等了
最后会出来这样的画面,最后面一个单词是success!表明成功了
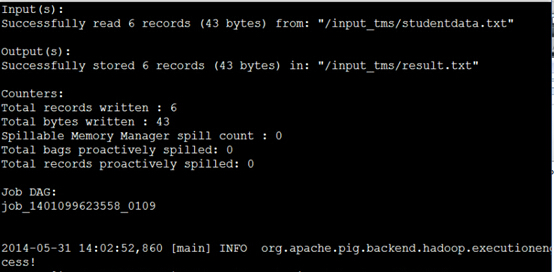
注意上面的两个东西:Input(s):显示了我们的传入到HDFS中数据文件的路径,
Output(s):结果输出在哪里和接收结果的文档名字“results.txt”
这个result.txt在我们脚本语言里面声明了的,还要注意的是我
们每次运行的时候Output下面接收结果的文档的名字还要不同,否则会报错
下面我们可以看看我们的input_tms目录下,这时你会发现多了一个result.txt文件
hadoop fs -ls /input_tms/

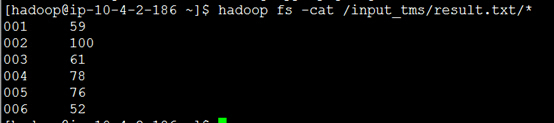
接下来查看我们的结果
hadoop fs -cat /input_tms/result.txt/* 后面的/*不能少,否则看不到结果
总结:
算是在集群上面跑了一个pig脚本的程序了,只是熟悉了一下操作,pig脚本的语法还没有去研究和学习,需要注意的是我们本地的数据文件要经过两次传递,第二次是传入到HDFS中去,而pig脚本只需要经过一次上传就可以了。

















 1646
1646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









