




 本文探讨了xv6操作系统内核中中断和锁机制的交互作用,特别是spinlock的使用及其与中断的关系。文章分析了在特定代码片段下内核panic的原因,对比了ide_lock和file_table_lock在中断开启状态下的不同行为,并详细解释了release函数中清除锁信息的必要性。
本文探讨了xv6操作系统内核中中断和锁机制的交互作用,特别是spinlock的使用及其与中断的关系。文章分析了在特定代码片段下内核panic的原因,对比了ide_lock和file_table_lock在中断开启状态下的不同行为,并详细解释了release函数中清除锁信息的必要性。
在本作业中,您将探索 interrupts 和locking之间的一些交互
Don’t do this
确保您理解如果xv6内核执行以下代码片段会发生什么:
struct spinlock lk;
initlock(&lk, "test lock");
acquire(&lk);
acquire(&lk);
(请随意使用QEMU查找. acquire 处于spinlock.c.)
用一句话解释发生了什么事。
首先看一下acqurie()函数的注释Acquire the lock. Loops (spins) until the lock is acquired.所以没申请到那个lock的话会一直循环等待。
然后在acqurie()函数开头有一行代码if(holding(lk)) panic("acquire");所以,连续两次申请同一个spinlock会导致panic
Interrupts in ide.c
An acquire确保使用cli指令在本地处理器上关闭中断(通过pushcli()),并且中断保持关闭状态,直到该处理器释放所持有的最后一个锁(此时使用sti启用了中断)。
让我们看看如果我们在保持ide锁的同时打开中断会发生什么。In iderw in ide.c,,在acquire()之后添加对sti()的调用,在release()之前添加对cli()的调用。重新构建内核并在QEMU中引导它。很有可能内核在启动后不久就会崩溃;如果没有启动QEMU,尝试启动几次。
用几句话解释一下内核panicked的原因。您可能会发现在内核
kernel.asmlisting中查找堆栈跟踪(由panic打印的%eip值序列)很有用。
单核下改之前:

改之后结果如下:
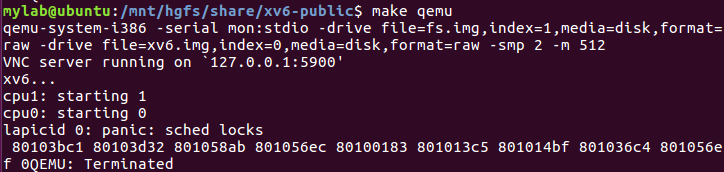
好像如果开双核,是可以启动QEMU成功的,不会出问题。不懂。。。
if(mycpu()->ncli != 1) panic("sched locks");80103bc1: eb 0d jmp 80103bd0 <exit>
release(&ptable.lock); 80103d32: c7 04 24 20 2d 11 80 movl $0x80112d20,(%esp)
yield(); 801058ab: eb a8 jmp 80105855 <trap+0x85>
(call trap的下一条)addl $4, %esp 801056ec: 83 c4 04 add $0x4,%esp
iderw(b); 80100183: 83 c4 10 add $0x10,%esp
bp = bread(dev, 1); 801013c5: 89 c3 mov %eax,%ebx
cprintf("sb: size %d nblocks %d ninodes %d nlog %d logstart %d\ 801014bf: ff 35 d8 09 11 80 pushl 0x801109d8
initlog(ROOTDEV); 801036c4: c7 04 24 01 00 00 00 movl $0x1,(%esp)
801056ef <trapret>:
还是不懂为什么,难道是释放锁之前开了中断,然后这时响应中断导致锁没释放就有新的锁申请,导致panic?
Interrupts in file.c
删除您添加的sti()和cli(),重新构建内核,并确保它再次工作。
现在让我们看看,如果我们在保持file_table_lock的同时打开中断会发生什么。这个lock保护文件描述符表,当应用程序打开或关闭文件时,内核将修改文件描述符表。In filealloc() in file.c,在调用acquire()之后向sti()添加一个调用,在每个release()es之前添加一个cli()。您还需要添加#include "x86.h"在文件的顶部,在其他#include行之后。重新构建内核并在QEMU中引导它。它很可能不会panic。
用几句话解释为什么内核没有panic。为什么file_table_lock和ide_lock在这方面有不同的行为?
要回答这个问题,您不需要了解IDE硬件的任何细节,但是您可能会发现了解哪些函数获得每个锁,以及何时调用这些函数是很有帮助的。
(在qemu上,内核很可能会对filealloc()中的额外sti()感到panic。如果内核出现panic,请确保您从iderw中删除了sti()调用。如果它继续panic,并且惟一额外的sti()是在filealloc()中,那么考虑一下为什么在实际硬件上不太可能出现这种情况。
完成了上述修改,确实没有出现panic,QEMU正常启动。
filealloc(void)、filedup(struct file *f)、fileclose(struct file *f)在函数开始通过acquire()获得
fileread(struct file *f, char *addr, int n)、filewrite(struct file *f, char *addr, int n)在对文件内容进行读写时才通过ilock()获得
ideintr(void)、iderw(struct buf *b)在函数开始通过acquire()获得
还是不太懂,参考Wu Yang ,这是因为在 xv6 中没有中断处理函数会争 ftable.lock 保护的资源。自然也就不会 acquire(&ftable.lock)。
xv6 lock implementation
为什么
release()在清除lk->locked之前先清除lk->pcs[0]和lk->cpu?为什么不等到以后呢?
// Mutual exclusion lock.
struct spinlock {
uint locked; // Is the lock held?
// For debugging:
char *name; // Name of lock.
struct cpu *cpu; // The cpu holding the lock.
uint pcs[10]; // 根据下面的getcallerpcs函数,可知道pcs里存的是acquire()的caller的返回地址
};
// Record the current call stack in pcs[] by following the %ebp chain.
void
getcallerpcs(void *v, uint pcs[])
{
uint *ebp;
int i;
ebp = (uint*)v - 2;
for(i = 0; i < 10; i++){
if(ebp == 0 || ebp < (uint*)KERNBASE || ebp == (uint*)0xffffffff)
break;
pcs[i] = ebp[1]; // saved %eip
ebp = (uint*)ebp[0]; // saved %ebp
}
for(; i < 10; i++)
pcs[i] = 0;
}
通过这上述代码,我们可以知道,lk->pcs存的是acquire(lk)的caller的返回地址,最多10个。lk->cpu 存的就是当前持有lk的cpu,**一个特定的lock一次只能由一个cpu持有。**之所以要在之前清除的原因:
一旦 realse() 执行 asm 语句,可能立即有进程获取锁,掉出 while 循环,接着执行 getcallerpcs(&lk, lk->pcs)。这时 lk->pcs 还未清空,导致 lk->pcs 错误的存入了另一个进程的调用栈。如果此时内核panic,就会打印出错误的调用栈信息。
不过,我试着把这两句放到lk->locked之后,好像也还是可以正常启动QEMU。。。
还是有很多不懂啊,后面再来补充吧。。。

















 9867
9867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









