







 本文深入介绍Hive数据仓库软件,阐述其在处理大型数据集中的作用,特别是在分布式存储环境中。文章详细解释了Hive如何通过SQL读取、编写和管理数据,以及其与HDFS的关系。此外,还探讨了Hive的架构、工作流程和数据类型,为读者提供全面的理解。
本文深入介绍Hive数据仓库软件,阐述其在处理大型数据集中的作用,特别是在分布式存储环境中。文章详细解释了Hive如何通过SQL读取、编写和管理数据,以及其与HDFS的关系。此外,还探讨了Hive的架构、工作流程和数据类型,为读者提供全面的理解。

前言
一转眼进入了2019年的4月份,学习大数据的小伙伴们肯定很辛苦吧,在大数据开发中HIVE在其中占了很大的比重,可以说是整个大数据仓的核心,在本文将详细介绍HIVE这个模块,废话不多说跟随小编一起来学习吧。
正文
一、Hive概述
1.Hive简介
Hive数据仓库软件有助于使用SQL读取、编写和管理驻留在分布式存储中的大型数据集。提供了命令行工具和JDBC驱动程序以将用户连接到Hive。
Hive可以将SQL语句自动转化为Mapreduce程序,节省了手写框架的困难。
2.Hive优缺点
优点:
1)操作接口采用了SQL,避免了首先MR程序,简化开发,降低学习成本;
2)Hive依赖于HDFS做存储,是HDFS上的工具;
3)Hive虽然使用SQL,但是他能处理大规模的数据;
4)Hive支持自定义函数。
缺点:
1)Hive执行延迟较高,大多适用于实时性不高的场景或用于处理历史数据;
2)Hive的SQL表达能力有限,有些复杂场景还需要MR程序;
3)hive效率低,优化较难。
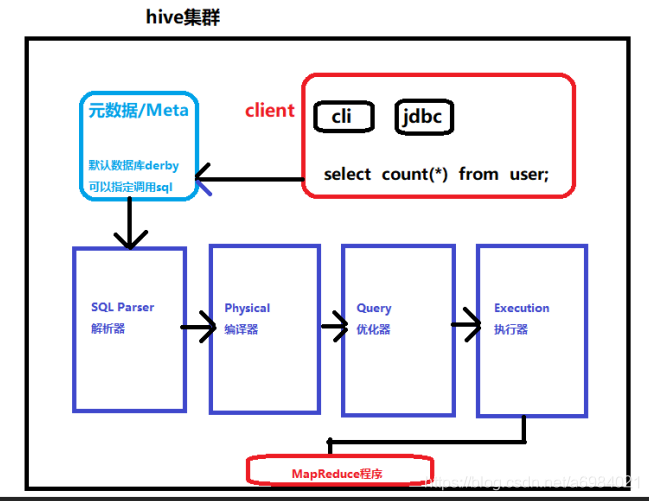
二、Hive架构
Hive提供了一下了接口:hive shell、JDBC/ODBC
Hive的工作流程:
1.客户端可以通过多种接口来使用hvie,比如cli(命令行)、jdbc(java);
2.比如使用命令行select count(*) from user调用SQL
客户端回去Meta元数据中调用MySQL的数据(hive默认数据库是derby,我们可以修改指定为MySQL);
3.从Meta获取数据库数据后,命令行和数据一次传入SQL Parser解析器、Physical编译器、Query优化器、Execution执行器;
4.最后对生成的MR程序进行运算,返回结果。
三、Hive中的数据类型

结尾
通过本文的描述各位小伙伴们对于HIVE是不是有了一个基本的了解?是不是感觉很神奇?那么接下来就要靠你们自己的刻苦联系了。

















 552
552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









