



 本文提出DRCN模型,一种结合DenseNet思想与注意力机制的循环网络结构,用于句子语义匹配。模型通过密集连接的RNN层及自编码器解决特征维度问题,在多个NLP任务中取得优秀结果。
本文提出DRCN模型,一种结合DenseNet思想与注意力机制的循环网络结构,用于句子语义匹配。模型通过密集连接的RNN层及自编码器解决特征维度问题,在多个NLP任务中取得优秀结果。
本文借鉴了DenseNet的思想,提出了一种密集连接的带有注意力机制的循环网络结构(DRCN)。网络中每一层的输入均由当前的特征表示、attention表示、上一层的隐藏层输出表示三部分拼接构成,并引入了自编码结构来解决不断增长的特征维度问题。本文在句子语义匹配相关数据集上进行了实验,结果表明DRCN能够在大部分任务上达到目前最优水平。

论文地址:
https://arxiv.org/abs/1805.11360
引言
句子语义匹配是NLP领域一个基础的技术,在自然语言推理、机器问答等方向都有重要的应用。主要有两类方法:第一种基于句子编码,即两个句子单独编码为固定大小的表示向量,通过这两个句子向量得到句子匹配程度;第二种考虑引入两个句子间的交互信息,如attention机制。本文提出了深层的DenseRNN结构来解决语义匹配问题,并引入了层间的attention机制和控制特征维度的autoencoder结构,在五个常用数据集(SNLI, MultiNLI, QUORA, TrecQA, SelQA)上均取得了优异的结果。
数据集
本文的实验主要分为三个任务:首先是自然语言推理任务,数据集为SNLI和MultiNLI;第二是释义识别任务,数据集为QUORA;最后是问答任务中的答案选择任务,数据集为TrecQA和SelQA。
模型
DRCN模型包括三大基本模块:Word Representation Layer, Attentively Connected RNN, Interaction and Prediction Layer。以下为该模型的基本层级式架构图:
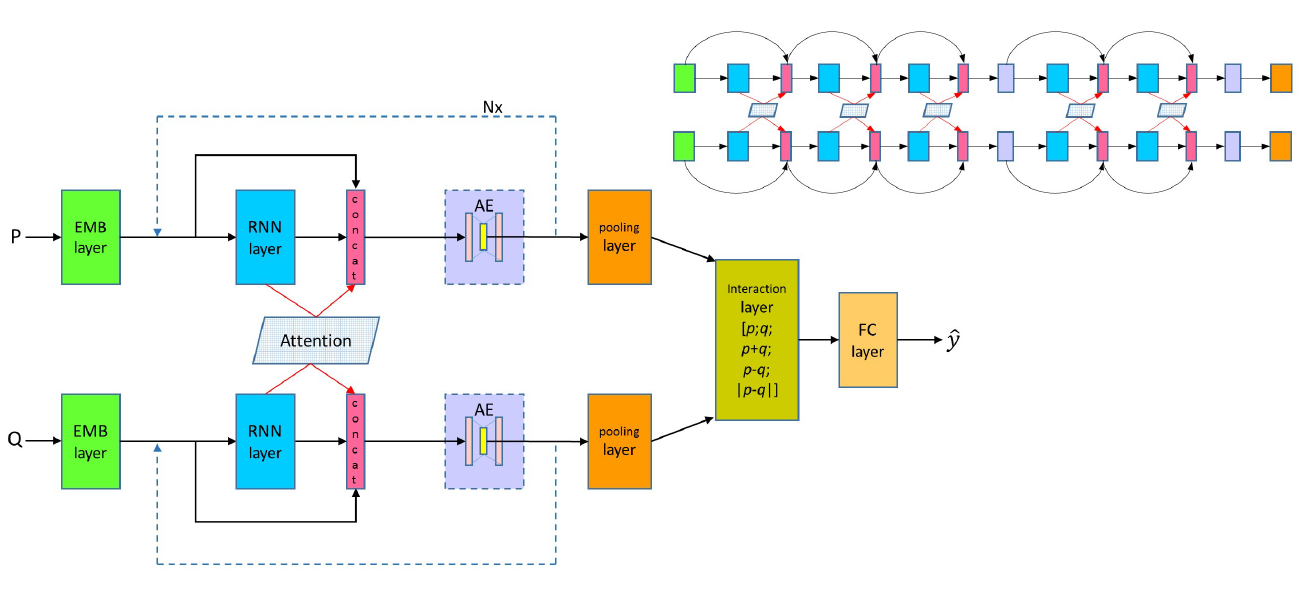
下面对五个模块分别进行叙述。
1. Word Representation Layer
将输入的两个句子表示为P和Q,长度分别为I和J。每个词的word representation feature由三部分构成:word embedding, character representation, the exact matched flag。其中word embedding包含两部分:预训练好的word embedding(如GloVe),表示为
e
p
i
f
i
x
e_{pi}^{fix}
epifix,以及随模型训练的word embedding,表示为
e
p
i
t
r
e_{pi}^{tr}
epitr。character representation为利用character level CNN得到的每个词的representation,表示为
c
p
i
c_{pi}
cpi。the exact matched flag代表词是否在其他句子中出现,表示为
f
p
i
f_{pi}
fpi。最终词
p
i
p_i
pi的word representation表示为
p
i
w
p_i^w
piw,由以上四种representation拼接而成。整个过程描述如下:
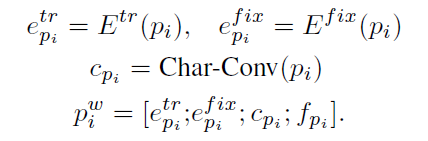
2. Attentively Connected RNN
2.1 Densely-connected Recurrent Networks
传统的多层RNN结构在层数加深的过程中会遭遇梯度消失或梯度爆炸等问题。为了解决此问题,研究者们提出了残差网络ResNet,即在网络前向传播中增加跳跃传播的过程,将信息更有效地传播至更深的层。但残差网络中的相加操作会使原始信息发生变化,因此本文借鉴了DenseNet的思想,在RNN的多层结构间通过拼接操作来保存上一层的隐层信息,表示如下:
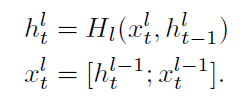
其中
H
l
H_l
Hl为多层RNN的第l层,并采用双向LSTM作为RNN的基本单元。
2.2 Densely-connected Co-attentive Networks
Attention机制可以在两个句子间建立对应关系,本文在多层RNN的每层中计算P和Q的attention信息,通过拼接得到每层RNN的输出。对于P中的词
p
i
p_i
pi,考虑与Q的attention过程后表示为
a
p
i
a_{p_i}
api,计算过程如下:
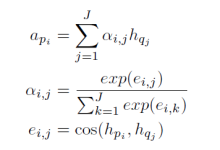
其中
h
p
i
h_{p_i}
hpi、
h
q
j
h_{q_j}
hqj分别为句子P、Q中词
p
i
p_i
pi、
q
j
q_j
qj在RNN对应层中的表示。
将
a
p
i
a_{p_i}
api与RNN对应层的输出进行拼接,总体表示如下:
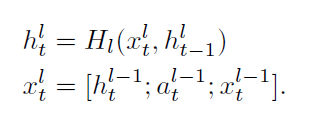
2.3Bottleneck Component
由于在多层RNN中进行了拼接操作,随着层数的加深,需要训练的参数会大量增加,因此引入自编码模块进行特征维数的压缩,实验证明,此操作对测试集起到了正则作用,提高了测试准确率。
3. Interaction and Prediction Layer
由于P、Q的长度不同,本文通过Max Pooling对每个句子分别得到其向量表示p、q,计算得到含有语义匹配信息的向量v,具体如下:
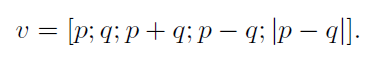
最后将v输入全连接层,并根据具体任务通过softmax进行分类。
本文整体架构是一个端到端的过程,损失函数定义为交叉熵损失与自编码器的重建损失之和,并选用RMSProp算法进行参数优化。
实验
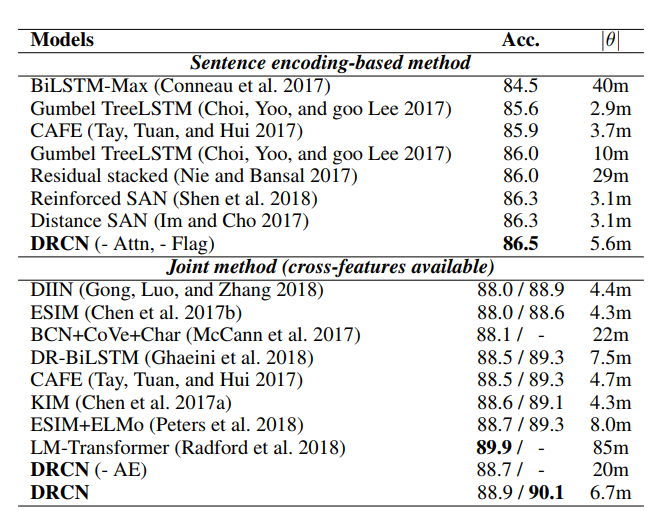
论文中实验较多,在这里着重介绍DRCN在自然语言推理任务上的实验结果,数据集为SNLI。
下图为DRCN模型在SNLI数据集上的实验结果。可以看出,DRCN单模型在没有使用外部知识的情况下(如ESIM+ELMo, LM-Transformer)取得了88.9%的准确率,复合模型取得了90.1%的准确率,为截止目前的最优表现。
文章进一步分析了模型中各个模块的作用大小,如下所示:
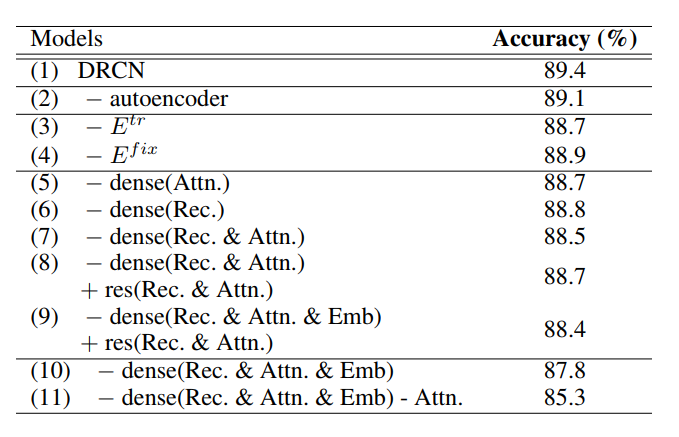
可以看出,随任务训练的word embedding、attention和dense-connect模块对模型的影响比较大。
下图为对比试验中各个模型在不同层的分类准确率曲线,可以看出,层之间有连接信息的模型对于RNN的深度更有鲁棒性,而dense连接比residual连接的性能更优,在模型深度增加时尤为明显。
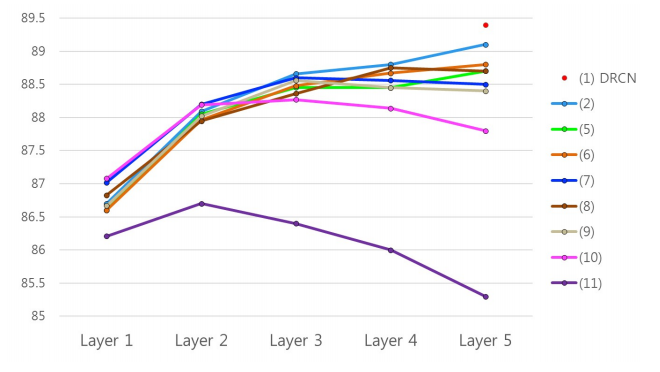
结论
本文提出了一种深层的DenseRNN结构,在语义匹配相关数据集上均取得了优异的表现。文章的主要创新点包括以下三部分:
1、采用固定的word embedding和可训练的word embedding拼接的方式,并提升了模型效果。
2、采用stack层级结构的双向LSTM,加入了DenseNet的思想,将上一层的参数拼接到下一层,一定程度上在长距离的模型中保留了前面的特征信息。
3、由于不断的拼接操作导致参数增多,使用autoencoder进行压缩降维,并起到了正则化效果,提升了模型准确率。

扫码识别关注,获取更多论文解读

















 897
897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









