




 本文通过一个生动的故事介绍了分布式系统中Leader选举的过程及数据复制的基本原理。讲述了如何通过选举产生一个Leader节点来统一管理和协调其他节点的操作,并讨论了数据复制过程中保证数据一致性的关键步骤。
本文通过一个生动的故事介绍了分布式系统中Leader选举的过程及数据复制的基本原理。讲述了如何通过选举产生一个Leader节点来统一管理和协调其他节点的操作,并讨论了数据复制过程中保证数据一致性的关键步骤。
1、分布式系统的难题
张大胖遇到了一个难题。
他们公司的有个服务器,上面保存着宝贵的数据,领导Bill 为了防止它挂掉, 要求张大胖想想办法把数据做备份。
张大胖发挥了抽象的能力,在脑海里浮出了这么一个画面, 这个唯一的机器可以成为一个节点:
为了提高可用性,可以增加几台机器,通过局域网连接起来,形成一个了分布式的系统:
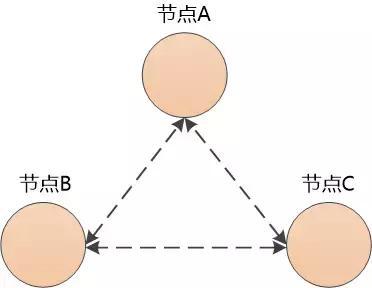
数据在每个节点上都存放一份不就可以高枕无忧了?
可张大胖很快发现这不是一件容易的事情,比如每个节点都保存着一个账户的余额100元,现在有人通过节点A向该账户增加了20元, 还有人通过节点B向该账户减去了30元。
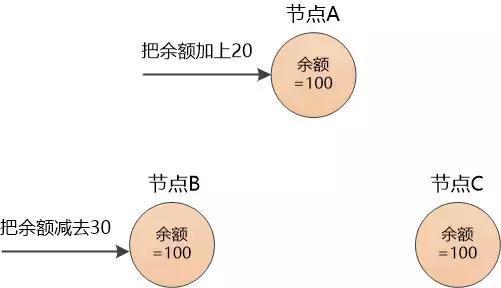
现在余额到底是多少呢?
为了保持一致性, 节点A得把"余额加上20"这样的消息发给B, C , 节点B得把“余额减去30”这样的消息发送到A, C, 如果网络出了问题,消息没有发送到别的节点, 或者某个节点干脆坏掉了,那数据极有可能出现不一致。
如果用户在这个不一致的系统上继续操作,很快就会陷入混乱。
2、谁来当老大?
张大胖想了半天,觉得不能这么无序地操作,得给这三个节点找个“老大”。
所有的操作都通过“老大”来进行,然后让老大把消息发给各个“小弟”。
可是谁来当老大呢? 还有,这个老大如果挂掉了怎么办?
可以手工地调整, 例如节点A挂掉了, 就手工地让节点B当“老大” , 让节点C当“小弟”。
但是这就有点麻烦了,能不能自动化地来实现?
这个问题很有意思, 张大胖入了迷,继续深入思考: 建立一个竞选的机制, 就让他们竞争上岗吧。
初始情况下,每个节点都是候选人, 都可以向其他节点发起投票邀请,让大家投自己,如果获得的投票数过半,就可以当“老大”了。
为了避免大家同时发起投票邀请,可以给每个节点都分配一个随机的“选举超时时间”(election timeout),通俗来讲就是一个等待时间,在这段时间内,一个节点必须耐心等待,过了这段时间,才可以竞争上岗,争当老大。
每个节点都有一个计时器,从0开始计时,谁的等待时间到了, 就率先发起竞选,给其他节点打电话,要求他们投票让自己成为老大。
比如节点A等待170ms , 节点B等待200ms , 节点C等待250ms 。
由于节点A的等待时间最短, 会捷足先登, 它先增加自己的任期(Term),这是一个整数,初始值为0 , 然后给自己投了一票,然后打电话给节点B和节点C,要求他们都投它。
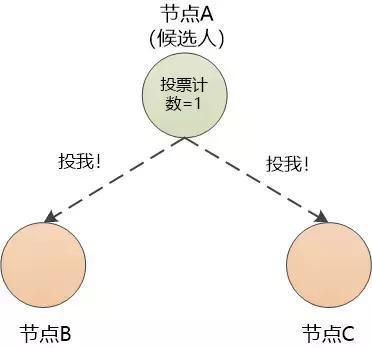
节点B和节点C收到了投票要求,如果自己还没有发起竞选投票(等待时间未到),那只好同意节点A当老大,与此同时要重置自己的计时器,重新从0开始计时,也就是说重新开始新一轮的等待。
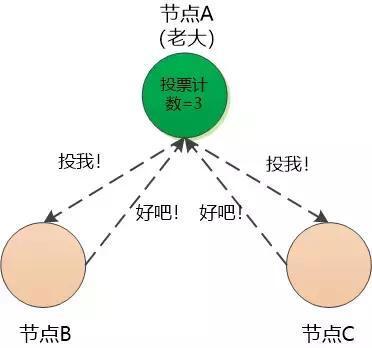
节点A得知其他两个节点同意了,投票计数变为3,已经过了半数, 就明白自己可以当老大了。
节点A成为老大后,开始向节点B和节点C定时发送消息,B,C收到消息后也要回应,维持心跳。
B和C每次收到心跳消息,都得重置自己的计时器, 重新从0开始计数。
此时节点B和节点C就成了“小弟”。
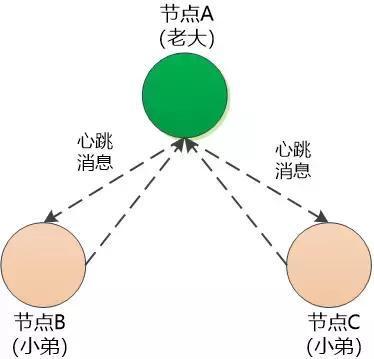
如果节点A 不幸挂掉,节点B和节点C在自己的等待时间内收不到心跳消息,他们两个就会重新竞争上岗。
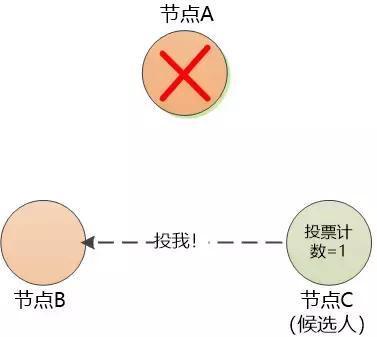
上图中节点C占据了先机,率先发起竞选投票。
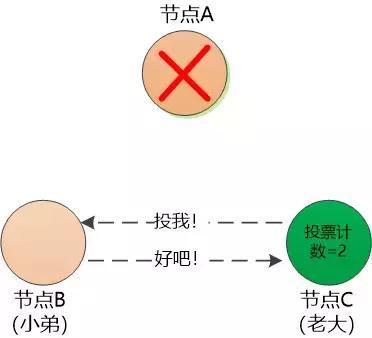
节点B慢了一步, 无奈中同意支持节点C , 节点C获得了超过半数的支持,成为“老大” , 节点B成为“小弟”。
(可能有人会想到:节点B和节点C 同时发起竞选投票,每个节点的投票计数都是1 ,都过不了半数, 该怎么处理呢? 很简单,再次发起一轮竞选投票即可,当然为了防止B和C一直同时发起竞选投票,从而陷入无限循环,要重置一个随机的等待时间。)
投票过半数很重要,张大胖想,只有这样才能保证“老大”节点的唯一性。
对于每个节点,处理流程其实非常简单:

3、数据的复制
张大胖费了半天劲,终于把分布式系统中怎么自动地选取“老大”节点给确定了。
接下来就是要把发给“老大”的数据,想办法复制到“小弟”的节点上。 该怎么处理?
由于是分布式的,只有大多数节点都成功地保存了数据,才算保存成功。
所以那个“老大”节点必须得承担起协调的职责。
张大胖想了一个复制日志的办法: 每个节点都有一个日志的队列。
在真正把数据提交之前,先把数据追加到日志队列中,然后向个“小弟”复制。
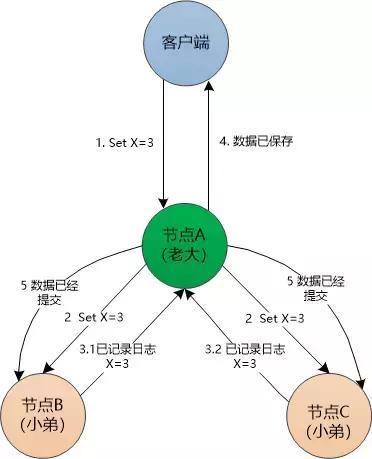
1. 客户端发送数据给节点A (“老大”)。
节点A 先把数据记录到日志中,即此时处于“未提交状态”
2. 在下一次的心跳消息中, 数据被发送给各个“小弟”。
3. 各个“小弟” 也把数据记录到日志中(也处于未提交状态),然后向“老大”报告自己已经记录了日志。
4. 如果节点A收到响应超过了半数, 节点A就提交数据,通知客户端数据保存成功。
5. 节点A在下一次心跳消息中,通知各个“小弟”该数据已经提交。各个“小弟”也提交自己的数据。
如果某个“小弟”不幸挂掉,那“老大”会不断地尝试联系它, 一旦它重新开始工作,就需要从“老大”那里去复制数据,和“老大”保持一致。
4、RAFT
张大胖对这个初步的设计还比较满意,他把这个方案交给领导Bill去审查。
Bill 看了以后,笑道: “你现在其实就是在折腾一个一致性算法, 说白了就是允许一组机器像一个整体一样工作,即使其中一些机器出现故障也能够继续工作下去。”
“没错没错,领导总结得真是精准。” 张大胖拍马屁。
“不过,”Bill 话锋一转, “ 你设计的日志的复制还有很多漏洞,我看你的设计中一共有5步, 如果在这5步中,那个“老大”节点A挂掉了怎么办?数据是不是就不一致了?”
“这个...... ” 张大胖确实没有仔细考虑。他暗自后悔,只顾低头拉车,忘了抬头看路,忽略了分布式环境下的复杂问题。
“不过你已经做得很不错了,” 领导马上鼓励道, “你设计的这一套体系其实和RAFT算法非常类似。”
“RAFT? ”
“对,RAFT是个分布式的一致性算法,相比复杂难懂的Paxos, RAFT在可理解,可实现性上做了很大的改进。 你这里的‘老大’,RAFT算法叫做Leader, ‘小弟’叫做Follower,不过人家对日志的复制,以及如何确保数据的一致性有着非常详细的规定。 ”
张大胖一听说有现成的算法,立刻高兴起来: “太好了,分布式的难题已经被别人解决,我去把它实现了。”
后记: 虽然RAFT比Paxos更容易理解, 但是一旦进入各个边界条件,仍然是非常复杂,所以本文只是介绍了Leader的选举,和日志复制的概要流程,
原文地址:https://baijiahao.baidu.com/s?id=1597294744568311877&wfr=spider&for=pc


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









