



文章目录
作为一个开发人员 总会遇到各种难题 本文列举博主 遇见/想到 的例子 ,也希望同学们可以在评论区举例交流 共同进步,文章博主一直在补充更新,阅读量和收藏量都不少, 非常欢迎各位能在评论区提出一些疑难场景,毕竟博主一个人的能力是有限的。另外,博主原创idea轻量级插件已上架idea的插件marketplace 欢迎搜索下载: Equals Inspection
> tips: 本文由csdn博主 孟秋与你 编写,如果您在其它地方看到此文章 那可能是被别的博主爬虫/复制搬运,博主的文章会持续更新 为确保您看到的文章是最新的 强烈建议您前往csdn查看原文
逻辑删除如何建立唯一索引
场景描述:
比如我们有project项目表
字段project_name 是唯一的,
且有逻辑删除字段is_delete 0表示未删除 1表示已删除
很显然 不能直接将project_name设置为唯一索引,
例如A用户建立的project_name为 java工程,又把这个工程(逻辑)删除了, 这时B用户是允许建立 java工程的。
那将is_delete project_name 共同设置为唯一索引是否可行呢? 答案也是否定的,在B用户删除时,就会出现问题了。
解决方案:
is_delete 不用0和1表示,可改为数字递增,或者时间戳(尽量小 例如纳秒级别), 这时将is_delete project_name 共同设置为唯一索引 可以解决该问题。
唯一索引失效问题
场景描述:
人员姓名和电话 组成唯一索引 。
出现问题:
有两个小孩 名字都叫小朋友 且他们都没有手机号 此时数据重复 唯一索引失效。 我们换个场景,在高并发的电商活动中,用户姓名和vip标识码 组成唯一索引,此时有两位用户 都不是vip用户,vip标识码都为空,那可能出现的问题就比较严峻了


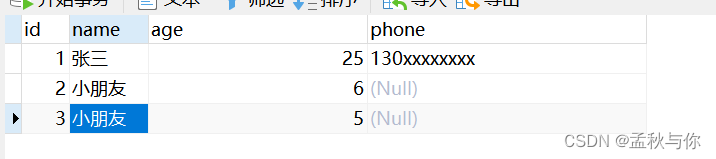
解决方案: 唯一索引的字段设置为非空,因为空是允许重复的
( 不管单独将某一个字段设置为唯一索引 还是多个字段组合成唯一索引 都一样的)
加密字段模糊查询问题
场景描述: 用户敏感信息,例如手机号 身份证 户籍所在地 入库时,我们通常会加密, 这时需要模糊查询
解决方案:
数据量少时,例如只是一个公司内部系统的人员表,可以全表查询 并解密,在java代码中过滤 (如果遇到要分页,那得好好考虑怎么处理分页问题了)
数据量少时,例如只是一个公司内部系统的人员表,可以全表查询 并解密,在java代码中过滤 (如果遇到要分页,那得好好考虑怎么处理分页问题了)
与业务/产品沟通,看搜索的字数是否相对固定的,例如某用户的户籍所在地是广东省广州市 那么我们可以将广东省、广州市拆分加密。 假设广东省加密后字符串为 pwd_gds 广州市加密后字符串为pwd_gzs, 此时我们前端传入广州市,后端加密后再进行模糊查询 sql语句变成 like %pwd_gzs%
与业务/产品沟通,看搜索的字数是否相对固定的,例如某用户的户籍所在地是广东省广州市 那么我们可以将广东省、广州市拆分加密。
假设广东省加密后字符串为 pwd_gds 广州市加密后字符串为pwd_gzs,
此时我们前端传入广州市,后端加密后再进行模糊查询 sql语句变成 like %pwd_gzs%
当然 前面两种方式只是取巧,通常在中型规模的项目就已经不适用了,既然提到拆分,那我们可以联想到分词,所以我们可以使用es,将各词都拆分加密 存入es中 (题外话 es也好 其它存储也罢 一定要设置密码 )
当然 前面两种方式只是取巧,通常在中型规模的项目就已经不适用了,既然提到拆分,那我们可以联想到分词,所以我们可以使用es,将各词都拆分加密 存入es中 (题外话 es也好 其它存储也罢 一定要设置密码 )
maven依赖冲突问题(jar包版本冲突问题)
场景描述: classNotFound , 这是在项目中,引入版本不正确最经常遇到的问题了。 我们跟进报错类,找到顶部import导包处,假设我们红色涂抹部分报红,我们可以找到前一级目录(红色划线处) ,按住ctrl 键 再鼠标左键点击,找到所在jar包
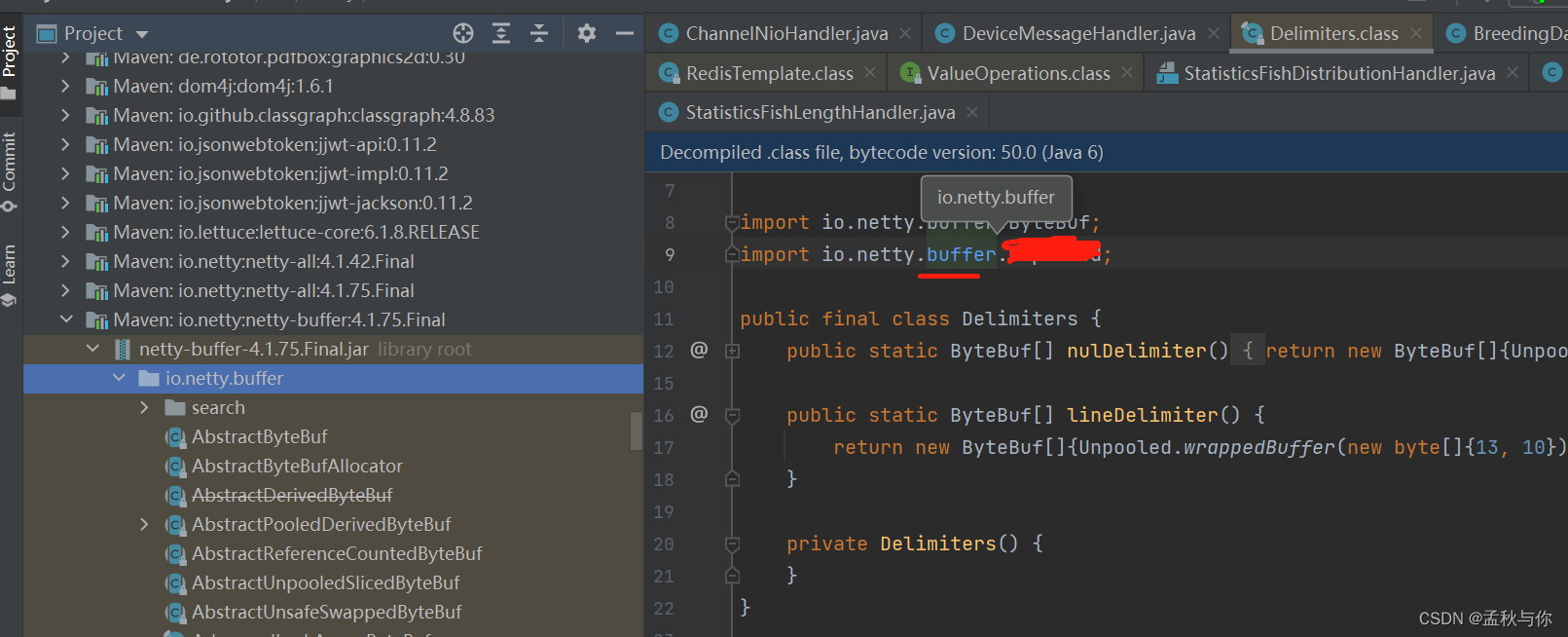
解决方案: 将jar包升级(或降级)。
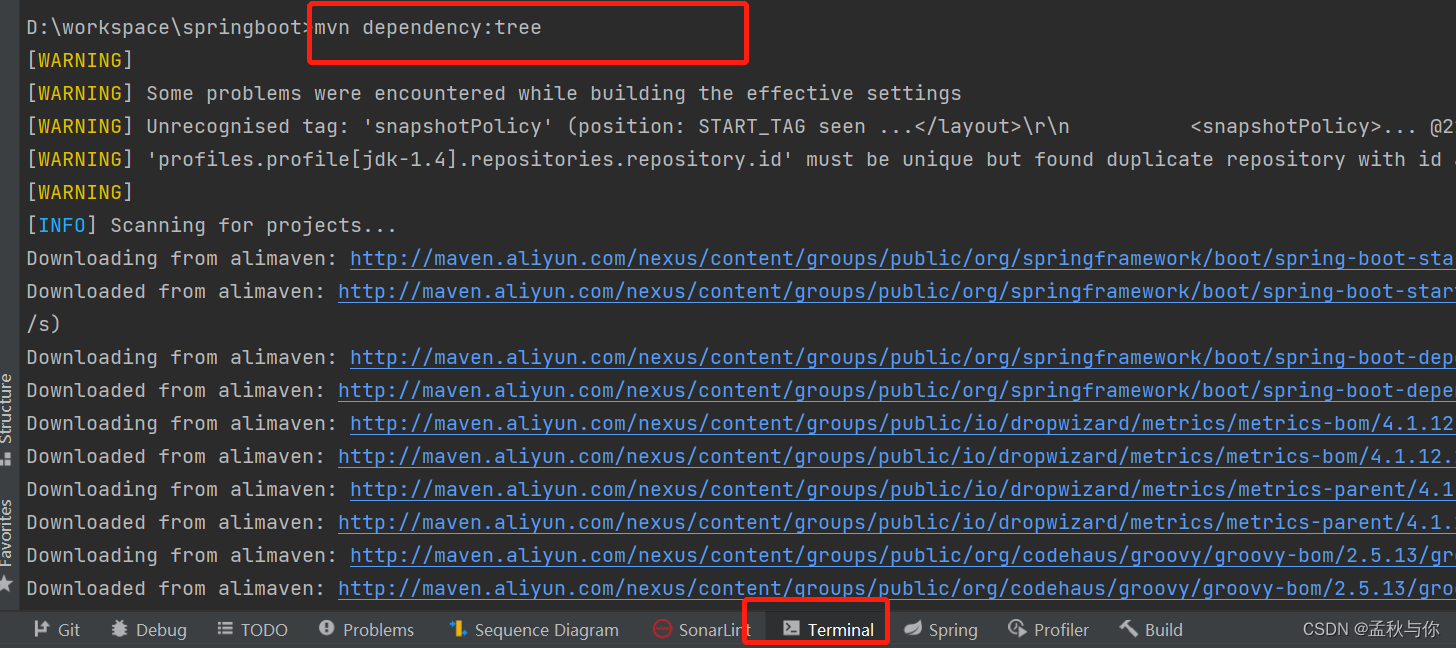
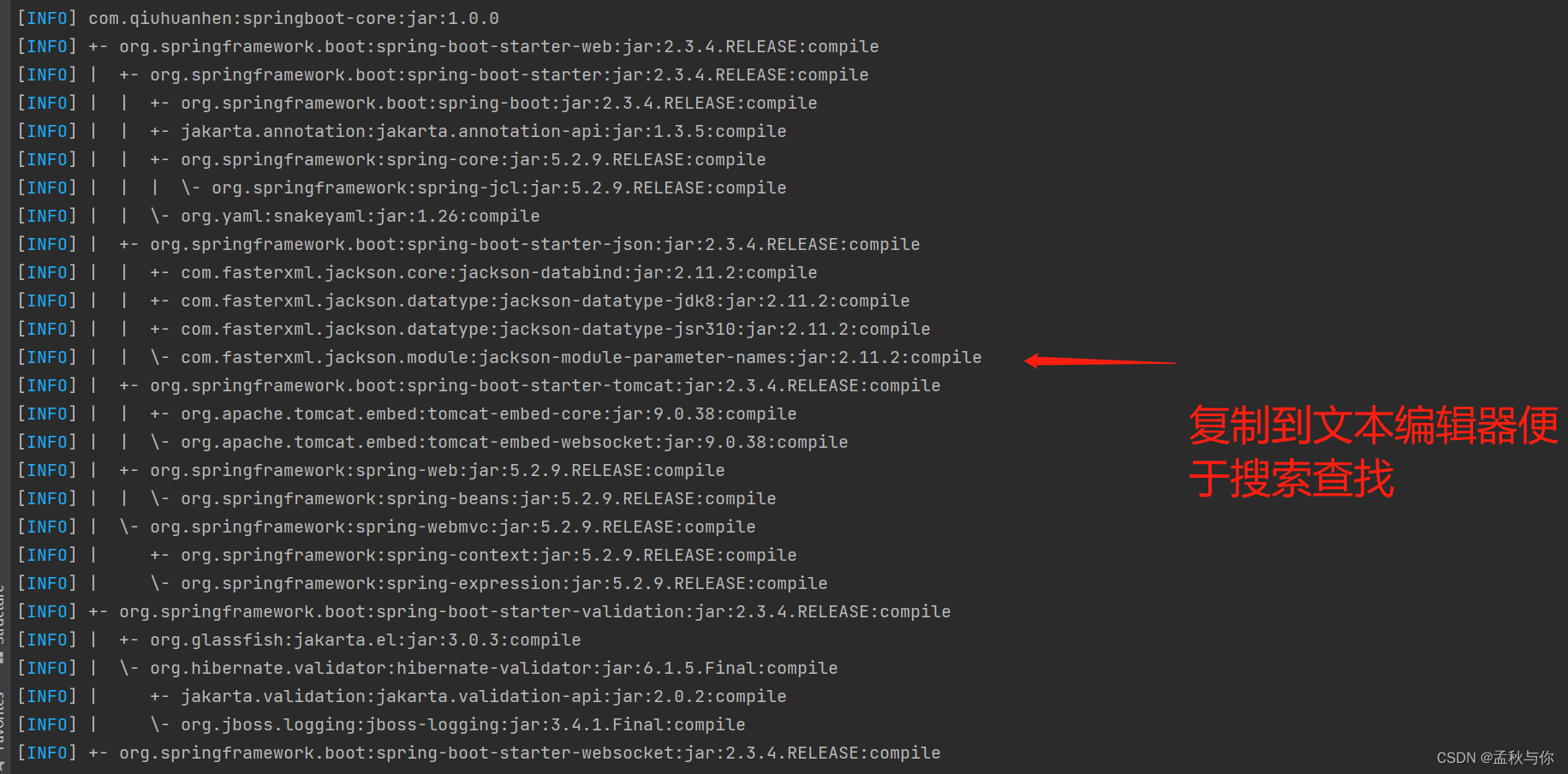
但很多时候,该jar包并不是我们直接通过maven依赖引入的,可能是通过其它组件内部引用的,这个时候我们就可以通过mvn dependency:tree 命令,将控制台打印信息复制到文本编辑器,在文本编辑器搜索 即可知道是哪个父包引入的
sql in条件查询时 将结果按照传入顺序排序
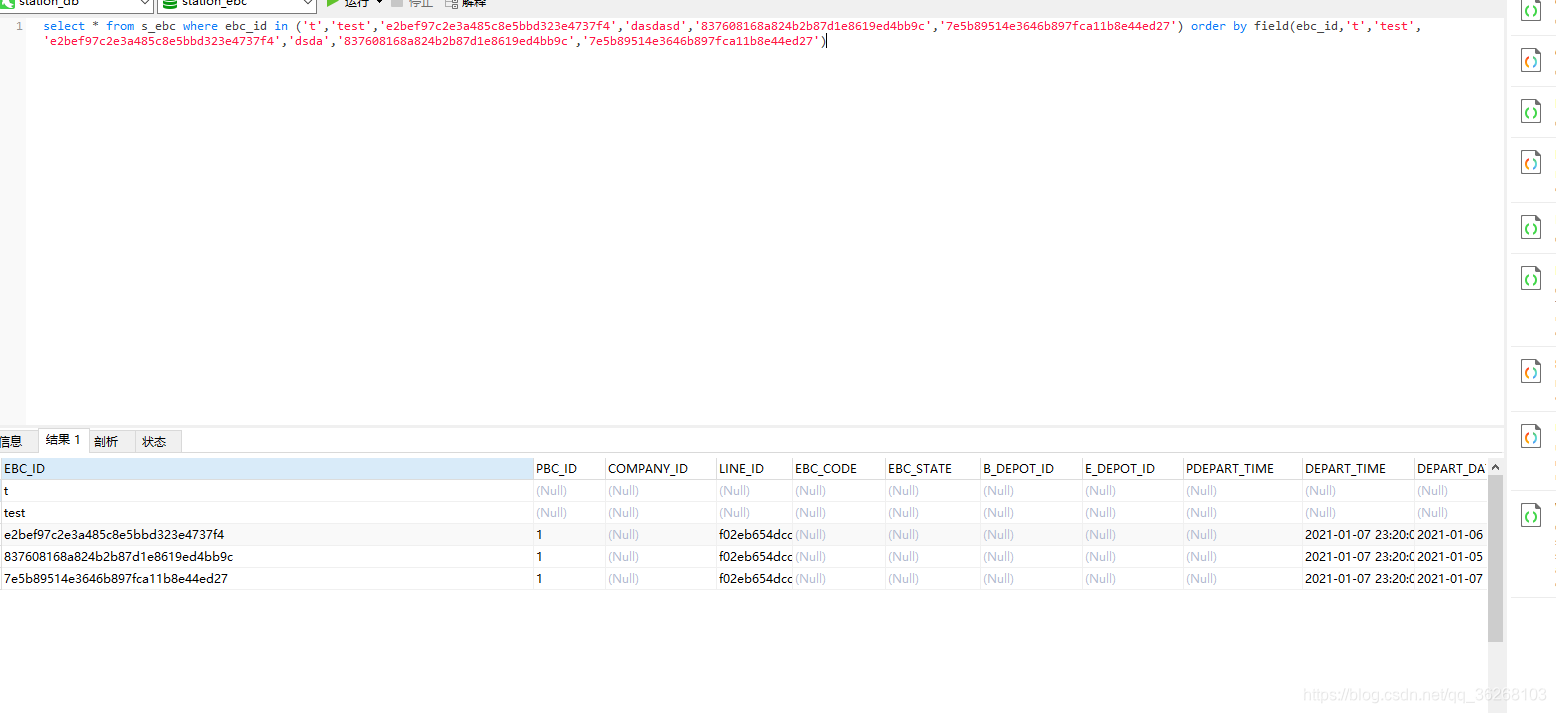
场景描述: 例如我们调用外部接口获取id, 再通过id去数据库查询,如果获取一条id 查一次库,是可以保证结果顺序和id传入顺序一致的;那此时我们希望优化一下下,等获取一批id时,再通过in条件查询的形式 :
select xx,xxx,xxxx from t where id in(5,1,4,2,3)
此时如何保证返回结果顺序与id传入顺序一致呢? 如上伪代码 id=5 时,希望返回记录在第一条
sql层面处理
orcale : order by decode

mysql : order by field
- 如果条件允许 不是直接sql开发,那么推荐是在java代码中去二次处理数据的,循环idList 根据id对比去重新组装结果即可。
数据库主从复制 主从不同步问题
场景描述: 由于网络延迟、负载、、自增主键不一致等等各种原因 导致主从数据不一致
解决方法: 线上真出现了问题,都到了需要集群数据库级别的项目 博主觉得吧 大部分还是手动修复数据吧 出现问题 谁都担不起…
言归正传:
锁主库 锁为只读状态
数据导出
停止从库
数据导入
重新开始同步
但是锁主库 停从库 这时候如果有数据来源 非常难处理,这时候最好的方式就是 业务对外公布维护了。
数据库读写分离 读写不一致
场景描述: 读写分离时,读从库时 数据和主库不一致
解决方法: 还是数据同步问题,看业务是否能容忍错误,能就不处理 不能容忍就手动修数据/重新同步。
临时解决方案为:强制路由(强制读取主库) 但博主还是认为,只要不是大面积出现问题,手动修数据都是比较稳妥的方案。
双写不一致问题 并发下数据库和缓存不一致
场景描述 : 在博主的 《从高并发场景下超卖问题到redis分布式锁》博客中 有提到过具体案例
解决方法:
延迟双删 优点: 博主个人认为优点不明显 缺点:博主认为在写多读少的场景下 没有一点用 写多读少场景下,在写入时删除缓存,读时更新缓存,此时延迟双删 不能解决任何问题 反而降低性能
延迟双删
优点: 博主个人认为优点不明显
缺点:博主认为在写多读少的场景下 没有一点用
写多读少场景下,在写入时删除缓存,读时更新缓存,此时延迟双删 不能解决任何问题 反而降低性能
使用队列 串行化 优点:避免不一致问题 缺点:效率低
使用队列 串行化
优点:避免不一致问题
缺点:效率低
分布式锁 串行化 如redislock 提供了读写锁 优缺点与第2点一致
分布式锁 串行化 如redislock 提供了读写锁
优缺点与第2点一致
使用canal中间件 博主未接触过 只是知道该中间件可以解决
使用canal中间件
博主未接触过 只是知道该中间件可以解决
java服务如何作为websocket客户端
场景描述: 有的时候 我们对接供应商/甲方接口,可能会遇到对方给的websocket接口,我们避免在前后端传输之间出现数据丢失问题 可能想在后端自己搭建websocket客户端。 注意是客户端,网上搜java websocket客户端,千篇一律都是搜出作为服务端的教程。
解决方法: 可以使用netty实现,博主目前在写自动重连和发送心跳时 遇到了问题 找了大佬写的比较好的代码 并经过测试 是可用的 具体的代码会单独发博客教程
spring事务
同一个事务中如何读取到未提交的数据
(非脏读!不要混淆概念! 同一个事务读未提交的数据是必要的!不同事务间才是脏读)
因为框架帮我们做的事情太多,导致很多细节都不必在意,不知道大家有没有思考过一个问题 :
@Transactional(rollbackFor = Exception.class)
public void test(Long id){
// 更新状态
updateStatusById(id);
// 查询最新状态
int status = getById(id).getStauts();
}
@Transactional(rollbackFor = Exception.class)
public void test(Long id){
// 更新状态
updateStatusById(id);
// 查询最新状态
int status = getById(id).getStauts();
}
更新状态时,事务其实并没有提交,那么为什么可以查询到最新的状态呢?任何数据库默认的隔离级别都不会是读未提交,所以我们不要往隔离级别方面去想。
正确答案是:ORM框架都有会话缓存机制,比如MyBatis使用会话(SqlSession)作为一个数据访问的上下文,它具有一级缓存。在同一个SqlSession中执行的所有操作都共享这个缓存。执行update后,接下来的select会在这个会话内访问缓存,从而能够读取到更新后的数据。
事务特性
spring的事务是根据线程来绑定的
所以如果在test方法中,再开启异步线程,则可能导致意想不到的问题。
由于每个线程在执行事务时是独立的,所以在同一时间,多个线程可以并行执行不同的事务,这本身并不会导致事务并发问题。每个线程的事务上下文互不干扰。
上面两点矛盾吗?
不矛盾,第一点是指在test方法内部开启异步,
第二点是指把一整个test方法放到异步里面执行 ,比如线程池执行: ()->test()
spring事务失效问题
场景描述: 事务失效 出现异常不回滚
首先 @Transactional需要加上(rollbackFor = Exception.class),博主之前有单独文章介绍过为什么阿里规范要求加上,排除是非RuntimeException导致的事务回滚失效
解决方法:
博主私认为 所有失效问题都是因为
对spring代理对象机制理解不深导致的,失效只是自己没用对,没通过代理对象去执行,自然会失效,欢迎在博主博客搜索事务 查看相应文章
跨线程了,事务是基于线程绑定的,如果在事务内再开启异步线程,异步里面的执行是不能共享事务上下文的
分布式事务失效问题(seata回滚失败)
场景描述:微服务中 seata事务未回滚
解决方法:
移步博主主页博客搜索:seata失效
数据库死锁问题
场景描述: 数据库死锁 导致系统卡爆
解决方法: 博主曾切身体会过,在老旧项目中,使用的是oracle 存储过程开发,由于大量的sql代码,且使用for update悲观锁,各处sql实在太多了,且未及时commit,引发了死锁,出现死锁我们需要在 v$session 中找到死锁进程 并杀死进程,解决核心是赶紧优化sql,简化或拆分逻辑。
在mysql中,使用replace into语句 也会引发死锁,建议使用select + insert方式替代,(据说mysql8.0已修复该bug 博主未亲测)
辅助分析mysql死锁方法:
SHOW ENGINE INNODB STATUS;
将status的内容复制出来,看LATEST DETECTED DEADLOCK模块
分库分表、分区
分库分表
分库分表可以使用shardingJDBC ,原理就是根据表达式来获取拆分后的库表 动态切换数据源来查询数据
(注意: 数据量不到亿级真没必要水平拆分,毕竟动态切换数据库需要时间,到亿级后自行测试具体效率,这么大数据量肯定是需要走索引的 而索引在千万级别是足够应对的;如果表字段又臭又多 那或许可以考虑垂直拆分)
不同分表策略带来的问题:
取模分表: 随着数据量增长 不同数据可能落入不同表 涉及数据迁移问题
固定范围分表(比如按月份):可能会有热点数据问题
例如某游戏做活动 某个月份的注册人数暴增,大量数据打在同一张表,
范围分表就无法很好起到分摊压力的作用
分区
(仅讨论分区语法 博主个人感觉分区有点鸡肋 可能只符合特定业务 感兴趣可以自行造亿级以上数据测试 这是只是提供一种思路)
常用分区策略:
range分区: 比如按照年份分区
list分区:按照枚举值分区 比如根据省份
hash分区:按哈希值分区,适用于数据比较均匀的场景
key分区:类似HASH分区,但使用MySQL的内部哈希函数
mysql5.1之后就可以分区了 语法为
-- 移除分区
-- ALTER TABLE test_part REMOVE PARTITIONING;
-- 修改表分区 (如果是创建 则在建表语句后面跟上PARTITION )
ALTER TABLE test_part
PARTITION BY RANGE (code) (
PARTITION p1 VALUES LESS THAN (100000000),
PARTITION p2 VALUES LESS THAN (200000000),
PARTITION p3 VALUES LESS THAN (300000000),
PARTITION p4 VALUES LESS THAN MAXVALUE
);
-- 移除分区
-- ALTER TABLE test_part REMOVE PARTITIONING;
-- 修改表分区 (如果是创建 则在建表语句后面跟上PARTITION )
ALTER TABLE test_part
PARTITION BY RANGE (code) (
PARTITION p1 VALUES LESS THAN (100000000),
PARTITION p2 VALUES LESS THAN (200000000),
PARTITION p3 VALUES LESS THAN (300000000),
PARTITION p4 VALUES LESS THAN MAXVALUE
);
建表分区示例
-- 根据年份分区
CREATE TABLE orders (
order_id INT NOT NULL,
customer_id INT NOT NULL,
order_date DATE NOT NULL,
total DECIMAL(10, 2),
PRIMARY KEY (order_id, order_date)
)
PARTITION BY RANGE (YEAR(order_date)) (
PARTITION p2019 VALUES LESS THAN (2020),
PARTITION p2020 VALUES LESS THAN (2021),
PARTITION p2021 VALUES LESS THAN (2022),
PARTITION pmax VALUES LESS THAN MAXVALUE
);
-- 根据年份分区
CREATE TABLE orders (
order_id INT NOT NULL,
customer_id INT NOT NULL,
order_date DATE NOT NULL,
total DECIMAL(10, 2),
PRIMARY KEY (order_id, order_date)
)
PARTITION BY RANGE (YEAR(order_date)) (
PARTITION p2019 VALUES LESS THAN (2020),
PARTITION p2020 VALUES LESS THAN (2021),
PARTITION p2021 VALUES LESS THAN (2022),
PARTITION pmax VALUES LESS THAN MAXVALUE
);
分区可以避免跨表分页的问题,虽然数据物理隔离了 但是终归是在同一张表;但是必须注意的一点:分区字段必须是主键字段之一
比如我们根据code字段分区,那么主键就为id+code (或者code为主键),
博主认为这个设计不太合适,如果允许唯一索引分区字段分区岂不是更好?
如下图 分区后反而降低了效率,主键本来就是聚促索引 弄成联合主键效率反而可能降低,在博主亲测的几千万级别数据 是完全没有必要分区(也没必要分表) , 不分区 建索引反而会快些
跨库分页问题
场景描述:
数据源来自不同的库,甚至不同类型的数据库(例如一部分来自mysql,部分来自于时序数据库)
大多数时候,只需要单独查不同的库就能满足业务,各司其职;但有一个页面 需要查看这两个库的数据 并实现分页功能。
解决方法:
首先能不跨库分页就不跨库分页,看业务是否真的不能妥协,数据源是否真的不能合并。
如果都不能,那只能考虑分页方案,下面是博主想到的方法:
将两个库的数据,同步至同一张大表中,记录好每次同步的最新那条数据的时间戳,下次同步时,同步这个时间戳以后的数据即可,大表只负责分页查询。
这时大表数据量虽然大些,但有分页在,效率不会过低。
(如果数据量过大 根据实际情况,考虑同步至es 、clickhouse等)
博主看到有人提过 canal可以同步mysql数据到es,还是要提醒:生产环境中不是我们demo写着玩,使用这种中间件 必须熟悉原理 否则重要数据丢失或出现问题 得不偿失!
此外 如果我们使用的sharding jdbc进行分库分表,那sharding jdbc自己就帮我们处理了分页问题,具体怎么处理的可以搜博主的sharding jdbc的文章。
分布式事务问题
场景描述:在分布式中 需要事务回滚
解决方法:可以引入seata中间件,seata中间件本身就是个事务调度器,基于mysql的undo日志;
如果不引入seata,也可以手动回滚,但这得严格要求代码及时调用,且不适用高并发场景,
仅适用于中小型项目, 伪代码如下:
/** * @author: csdn:孟秋与你 **/
// service A
public GoodsDO delete(Long id){
GoodsDO gs = database.getOne(id);
database.deleteById(id);
return gs;
}
public void insert(GoodsDO gs){
database.insert(gs);
}
// service B
@Autowired
private ServiceA serviceA;
public void handle(Long id){
try{
GoodsDO gs = serviceA.deleteById(id);
// do other things serviceB.xx();
}
catch(E e){
// 这里可以换成aop方式,也可以通过mq实现异步
serviceA.insert(gs);
}
}
/** * @author: csdn:孟秋与你 **/
// service A
public GoodsDO delete(Long id){
GoodsDO gs = database.getOne(id);
database.deleteById(id);
return gs;
}
public void insert(GoodsDO gs){
database.insert(gs);
}
// service B
@Autowired
private ServiceA serviceA;
public void handle(Long id){
try{
GoodsDO gs = serviceA.deleteById(id);
// do other things serviceB.xx();
}
catch(E e){
// 这里可以换成aop方式,也可以通过mq实现异步
serviceA.insert(gs);
}
}
如何避免多人同时修改问题
场景描述:例如管理系统中,管理人员可以修改员工的基本信息,员工自己也可以修改。员工在修改过程中,如果管理员已经修改并提交,员工随后提交,这就会将管理人员修改的内容覆盖。
解决方法:详情接口 加上乐观锁版本号,在点击编辑按钮时,调用一次详情接口,获取到当前的乐观锁版本号,例如员工点编辑时 version = 1,接下来管理员也点击了编辑,管理员得到的版本号也为1 (此时员工还没保存),接着管理员点击保存,前端将版本号传回后端,保存接口中去判断前端传入的版本号和当前数据库版本号是否一致(这个时候是一致的 都是1),管理员保存成功 修改乐观锁版本号。员工点击保存时,传入的版本号也为1,但此时数据库获取的版本号,已经变成2了,提示前端信息已被他人修改 刷新页面再进入。
netty中 发送多条指令 如何与回复内容进行对应
场景描述:netty中,向服务端发送多条指令,接收到回复时,如何确定哪条内容对应是哪条指令发送的
解决方法:可以在发送时,在数据头部添加一个请求ID字段,或者在尾部添加一个ack应答机制, 但这前提都是需要服务端进行配合。
参考代码如下:
// 客户端代码
public class ClientHandler extends ChannelInboundHandlerAdapter {
// 记录每个请求的请求ID
private final Map<Integer, String> requestMap = new ConcurrentHashMap<>();
// 记录每个请求对应的响应结果
private final Map<String, String> responseMap = new ConcurrentHashMap<>();
// 请求ID生成器
private final AtomicInteger requestIdGenerator = new AtomicInteger(0);
public void sendRequest(byte[] data) {
int requestId = requestIdGenerator.incrementAndGet();
ByteBuf buf = Unpooled.buffer(data.length + 4);
buf.writeInt(requestId);
buf.writeBytes(data);
channel.writeAndFlush(buf);
// 将请求ID和请求数据保存到请求映射表
requestMap.put(requestId, Arrays.toString(data));
}
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
if (msg instanceof ByteBuf) {
ByteBuf buf = (ByteBuf) msg;
int requestId = buf.readInt();
byte[] data = new byte[buf.readableBytes()];
buf.getBytes(buf.readerIndex(), data);
String request = requestMap.get(requestId);
if (request != null) {
// 将请求ID和响应数据保存到响应映射表
String response = Arrays.toString(data);
responseMap.put(request, response);
// 从请求映射表中删除请求ID
requestMap.remove(requestId);
}
}
}
}
// 客户端代码
public class ClientHandler extends ChannelInboundHandlerAdapter {
// 记录每个请求的请求ID
private final Map<Integer, String> requestMap = new ConcurrentHashMap<>();
// 记录每个请求对应的响应结果
private final Map<String, String> responseMap = new ConcurrentHashMap<>();
// 请求ID生成器
private final AtomicInteger requestIdGenerator = new AtomicInteger(0);
public void sendRequest(byte[] data) {
int requestId = requestIdGenerator.incrementAndGet();
ByteBuf buf = Unpooled.buffer(data.length + 4);
buf.writeInt(requestId);
buf.writeBytes(data);
channel.writeAndFlush(buf);
// 将请求ID和请求数据保存到请求映射表
requestMap.put(requestId, Arrays.toString(data));
}
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
if (msg instanceof ByteBuf) {
ByteBuf buf = (ByteBuf) msg;
int requestId = buf.readInt();
byte[] data = new byte[buf.readableBytes()];
buf.getBytes(buf.readerIndex(), data);
String request = requestMap.get(requestId);
if (request != null) {
// 将请求ID和响应数据保存到响应映射表
String response = Arrays.toString(data);
responseMap.put(request, response);
// 从请求映射表中删除请求ID
requestMap.remove(requestId);
}
}
}
}
ack:
/** *@author csdn:孟秋与你 **/
public class MyClientHandler extends ChannelInboundHandlerAdapter {
// 记录上一次请求的ACK字段的值
private int lastAck = 1;
public void sendRequest(byte[] data) {
// 在请求数据末尾添加一个预留的ACK字段
byte[] requestData = Arrays.copyOf(data, data.length + 1);
requestData[data.length] = (byte) lastAck;
channel.writeAndFlush(requestData);
}
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
if (msg instanceof ByteBuf) {
ByteBuf buf = (ByteBuf) msg;
byte[] data = new byte[buf.readableBytes()];
buf.readBytes(data);
int ack = data[data.length - 1];
// 修改ACK字段的值为1
data[data.length - 1] = 1;
lastAck = 1;
// 处理服务端的响应
handleResponse(data);
}
}
public void handleResponse(byte[] data) {
// 处理服务端的响应
// ...
}
}
/** *@author csdn:孟秋与你 **/
public class MyClientHandler extends ChannelInboundHandlerAdapter {
// 记录上一次请求的ACK字段的值
private int lastAck = 1;
public void sendRequest(byte[] data) {
// 在请求数据末尾添加一个预留的ACK字段
byte[] requestData = Arrays.copyOf(data, data.length + 1);
requestData[data.length] = (byte) lastAck;
channel.writeAndFlush(requestData);
}
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
if (msg instanceof ByteBuf) {
ByteBuf buf = (ByteBuf) msg;
byte[] data = new byte[buf.readableBytes()];
buf.readBytes(data);
int ack = data[data.length - 1];
// 修改ACK字段的值为1
data[data.length - 1] = 1;
lastAck = 1;
// 处理服务端的响应
handleResponse(data);
}
}
public void handleResponse(byte[] data) {
// 处理服务端的响应
// ...
}
}
那如果服务端拒绝配合呢? 那我们只能在等接收到响应后,再发送下一条指令,思路如下
(但是注意 并发下会出现问题 如果有并发场景,必须得服务端配合做应答机制):
定义一个 指令下标 (我们以要发送10条指令为例) :
public static AtomicInteger index = new AtomicInteger(0);
提供一个修改下标的方法
public static void setOtherIndex() {
// 如果下标到了10 则清0 进行下一次的轮询
if (Objects.equals(cabinIndex.get(), 10)) {
cabinIndex.set(0);
} else {
cabinIndex.getAndAdd(1);
}
}
发送指令
if(index.get() == 0){
new byte[]{0x01}
}else if (index.get() == 1){
new byte[]{0x02}
}
// .....
channelRead 方法中处理数据
// dosomething
// 处理完毕后 下标偏移
setOtherIndex();
MQ消息重复消费问题
场景描述:MQ消息可能会被重复消费
解决方法:
消息幂等性设计: 保证消息的处理是幂等的,即多次处理同一条消息产生的效果和一次处理是一样的。这样,即使消息被重复消费,系统也不会产生错误的结果。
消息幂等性设计: 保证消息的处理是幂等的,即多次处理同一条消息产生的效果和一次处理是一样的。这样,即使消息被重复消费,系统也不会产生错误的结果。
消息发送时,添加一个消息id , 可以用redis等去维护已经消费过的id,消费前去判断是否已经消费过。 (其实和幂等也类似)
消息发送时,添加一个消息id , 可以用redis等去维护已经消费过的id,消费前去判断是否已经消费过。
(其实和幂等也类似)
MQ 消息堆积问题
场景描述:MQ消息大量堆积未被消费的消息
消息队列容量调整: 根据业务的实际需求,调整消息队列的容量。确保消息队列的容量足够,能够应对高峰期的消息产生。
消息队列容量调整: 根据业务的实际需求,调整消息队列的容量。确保消息队列的容量足够,能够应对高峰期的消息产生。
优化消费者端:调整消费者的线程数, 确保消费者的线程数足够,能够满足高并发的需求,增加消费者,增加pullBatchSize
优化消费者端:调整消费者的线程数, 确保消费者的线程数足够,能够满足高并发的需求,增加消费者,增加pullBatchSize
监控和报警: 设置监控和报警机制,及时发现消息堆积的情况并采取措施。通过监控系统,了解消息队列的状态,及时预警和处理问题。(辅助手段)
监控和报警: 设置监控和报警机制,及时发现消息堆积的情况并采取措施。通过监控系统,了解消息队列的状态,及时预警和处理问题。(辅助手段)
如果是RabbitMQ 可以结合业务是否允许 来缩短TTL时间 (time to live) ; 在rocketMQ中目前是不支持的,可能设计初就是只为了At least once (最少一次,消息绝不会丢失,但可能会重复传输), 我们可以看到rocketMQ的MessageConst类中是包含了TTL关键字的,不知道在未来是否会在Message类中提供修改方法。
如果是RabbitMQ 可以结合业务是否允许 来缩短TTL时间 (time to live) ; 在rocketMQ中目前是不支持的,可能设计初就是只为了At least once (最少一次,消息绝不会丢失,但可能会重复传输), 我们可以看到rocketMQ的MessageConst类中是包含了TTL关键字的,不知道在未来是否会在Message类中提供修改方法。
接口重复调用问题(幂等)
场景描述:接口重复提交
前端首先要做禁止重复点击
生成一个UUID,后端处理请求后,将ID和结果存入缓存 ,下次如果有相同的id传入,直接从缓存中取出结果并返回。 (不一定是uuid,根据业务 也可能业务唯一标识即可)
如果是修改接口,也可以用版本号(乐观锁思想),提交时先调用详情接口 获取到version, 传入后端 更新语句带上version
多线程中如何等待线程都执行完毕
传统多线程
我们先看不做处理的代码:
/** * @author: csdn:孟秋与你 **/
public static void main(String[] args) {
// 有name age字段的一个实体类
Ademo ademo = new Ademo();
Thread thread1 = new Thread(new Runnable() {
@Override
public void run() {
try {
// 模拟业务执行了2秒
Thread.sleep(2000);
// 模拟获取age
ademo.setAge(18);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread thread2 = new Thread(new Runnable() {
@Override
public void run() {
try {
// 模拟业务执行了5秒
Thread.sleep(5000);
// 模拟获取name
ademo.setName("优快云:孟秋与你");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
thread1.start();
thread2.start();
// 主业务获取name age 此时都为null 因为异步线程还没执行完
System.out.println("姓名: " + ademo.getName()+" 年龄:"+ademo.getAge());
}
/** * @author: csdn:孟秋与你 **/
public static void main(String[] args) {
// 有name age字段的一个实体类
Ademo ademo = new Ademo();
Thread thread1 = new Thread(new Runnable() {
@Override
public void run() {
try {
// 模拟业务执行了2秒
Thread.sleep(2000);
// 模拟获取age
ademo.setAge(18);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread thread2 = new Thread(new Runnable() {
@Override
public void run() {
try {
// 模拟业务执行了5秒
Thread.sleep(5000);
// 模拟获取name
ademo.setName("优快云:孟秋与你");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
thread1.start();
thread2.start();
// 主业务获取name age 此时都为null 因为异步线程还没执行完
System.out.println("姓名: " + ademo.getName()+" 年龄:"+ademo.getAge());
}
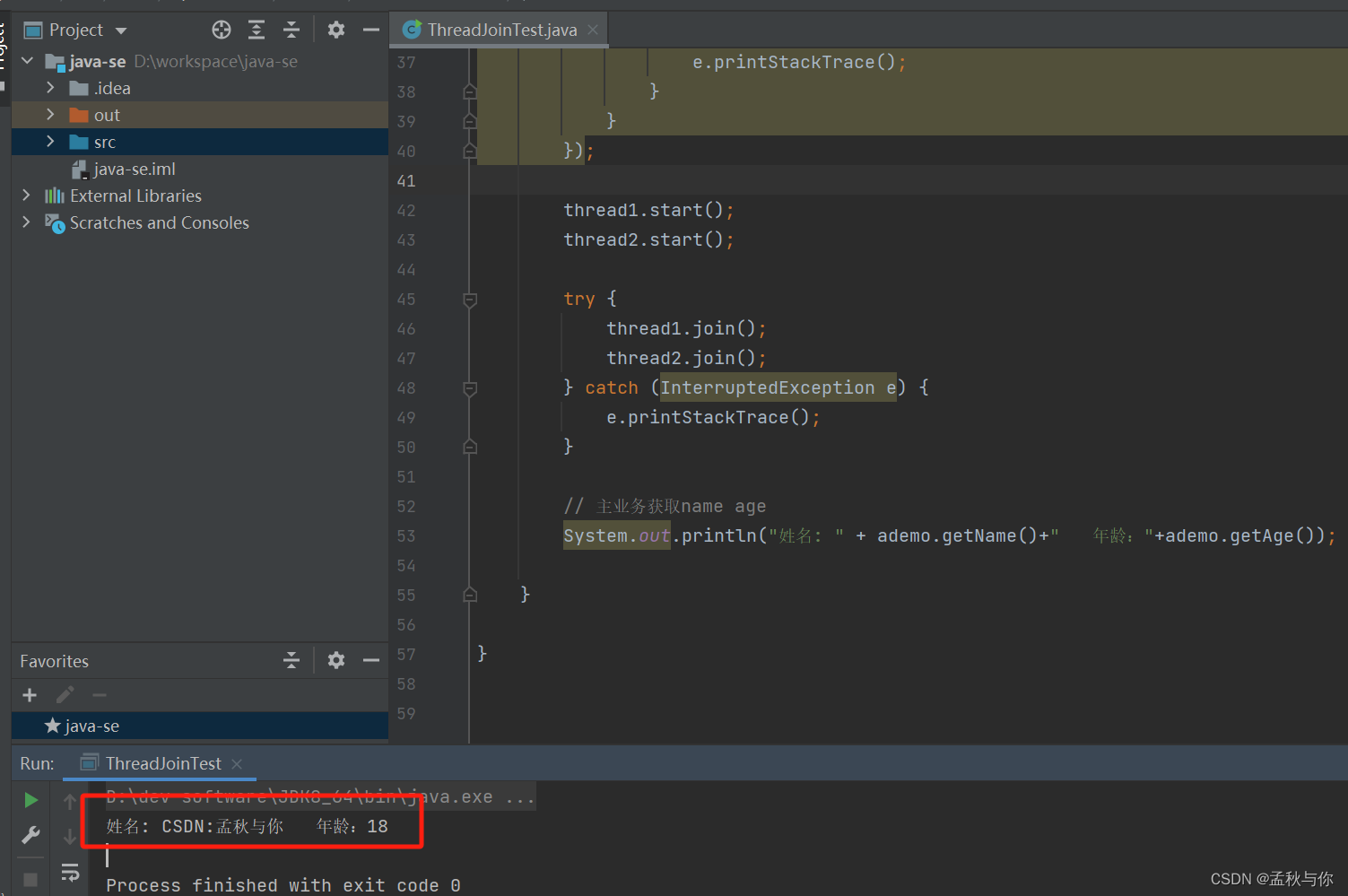
解决方法: thread.join()
原理是join方法会通过while循环去判断线程是否存活,存活则一直等待
thread1.start();
thread2.start();
// 在主业务前 将需要等待执行结果的线程join
try {
thread1.join();
thread2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
// 主业务获取name age
System.out.println("姓名: " + ademo.getName()+" 年龄:"+ademo.getAge());
thread1.start();
thread2.start();
// 在主业务前 将需要等待执行结果的线程join
try {
thread1.join();
thread2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
// 主业务获取name age
System.out.println("姓名: " + ademo.getName()+" 年龄:"+ademo.getAge());
CompletableFuture
jdk8开始引入的特性,同样可以使用join()方法 或get()方法
public static void main(String[] args) {
// 有name age字段的一个实体类
Ademo ademo = new Ademo();
long start = System.currentTimeMillis();
// 默认是由ForkJoinPool实现的 ForkJoinPool就是为了 Fork-Join 模型设计的线程池
// 如果要返回值 使用 supplyAsync方法
CompletableFuture future1 = CompletableFuture.runAsync(new Runnable() {
@Override
public void run() {
try {
// 模拟业务执行了2秒
Thread.sleep(2000);
// 模拟获取age
ademo.setAge(18);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
CompletableFuture future2 = CompletableFuture.runAsync(new Runnable() {
@Override
public void run() {
try {
// 模拟业务执行了5秒
Thread.sleep(5000);
// 模拟获取name
ademo.setName("优快云:孟秋与你");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
// 注意 allOf本身只是做个合并
CompletableFuture<Void> allFuture = CompletableFuture.allOf(future1, future2);
// 如果换成allFuture.get() 则需要手动对 allFuture.get进行try catch
allFuture.join();
/** * 上面两行代码 相当于 * future1.join(); * future2.join(); **/
// 主业务获取name age
System.out.println("姓名: " + ademo.getName() + " 年龄:" + ademo.getAge());
System.out.println(System.currentTimeMillis() - start);
}
public static void main(String[] args) {
// 有name age字段的一个实体类
Ademo ademo = new Ademo();
long start = System.currentTimeMillis();
// 默认是由ForkJoinPool实现的 ForkJoinPool就是为了 Fork-Join 模型设计的线程池
// 如果要返回值 使用 supplyAsync方法
CompletableFuture future1 = CompletableFuture.runAsync(new Runnable() {
@Override
public void run() {
try {
// 模拟业务执行了2秒
Thread.sleep(2000);
// 模拟获取age
ademo.setAge(18);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
CompletableFuture future2 = CompletableFuture.runAsync(new Runnable() {
@Override
public void run() {
try {
// 模拟业务执行了5秒
Thread.sleep(5000);
// 模拟获取name
ademo.setName("优快云:孟秋与你");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
// 注意 allOf本身只是做个合并
CompletableFuture<Void> allFuture = CompletableFuture.allOf(future1, future2);
// 如果换成allFuture.get() 则需要手动对 allFuture.get进行try catch
allFuture.join();
/** * 上面两行代码 相当于 * future1.join(); * future2.join(); **/
// 主业务获取name age
System.out.println("姓名: " + ademo.getName() + " 年龄:" + ademo.getAge());
System.out.println(System.currentTimeMillis() - start);
}
线程池
CountDownLatch
解决方案:CountDownLatch
public static void main(String[] args) {
// 有name age字段的一个实体类
Ademo ademo = new Ademo();
// 实际使用 需要手动创建 防止OOM
ExecutorService executorService = Executors.newFixedThreadPool(2);
// 严格控制构造参数数量 参数大于实际线程数 将会陷入无限等待!
CountDownLatch countDownLatch = new CountDownLatch(2);
long start = System.currentTimeMillis();
executorService.execute(new Runnable() {
@Override
public void run() {
try {
// 模拟业务执行了5秒
Thread.sleep(5000);
// 模拟获取name
ademo.setName("优快云:孟秋与你");
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
// 需要保证countDown正确执行
countDownLatch.countDown();
}
}
});
executorService.execute(() -> {
try {
// 模拟业务执行了2秒
Thread.sleep(2000);
// 模拟获取age
ademo.setAge(18);
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
// 需要保证countDown正确执行
countDownLatch.countDown();
}
});
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
// 主业务获取name age
System.out.println("姓名: " + ademo.getName() + " 年龄:" + ademo.getAge());
System.out.println(System.currentTimeMillis() - start);
}
public static void main(String[] args) {
// 有name age字段的一个实体类
Ademo ademo = new Ademo();
// 实际使用 需要手动创建 防止OOM
ExecutorService executorService = Executors.newFixedThreadPool(2);
// 严格控制构造参数数量 参数大于实际线程数 将会陷入无限等待!
CountDownLatch countDownLatch = new CountDownLatch(2);
long start = System.currentTimeMillis();
executorService.execute(new Runnable() {
@Override
public void run() {
try {
// 模拟业务执行了5秒
Thread.sleep(5000);
// 模拟获取name
ademo.setName("优快云:孟秋与你");
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
// 需要保证countDown正确执行
countDownLatch.countDown();
}
}
});
executorService.execute(() -> {
try {
// 模拟业务执行了2秒
Thread.sleep(2000);
// 模拟获取age
ademo.setAge(18);
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
// 需要保证countDown正确执行
countDownLatch.countDown();
}
});
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
// 主业务获取name age
System.out.println("姓名: " + ademo.getName() + " 年龄:" + ademo.getAge());
System.out.println(System.currentTimeMillis() - start);
}
CyclicBarrier
类似的 解决方案还有 CyclicBarrier
public static void main(String[] args) {
// 有name age字段的一个实体类
Ademo ademo = new Ademo();
// 实际使用 需要手动创建 防止OOM
ExecutorService executorService = Executors.newFixedThreadPool(2);
// 严格控制构造参数数量 参数大于实际线程数 将会陷入无限等待!
CyclicBarrier cyclicBarrier = new CyclicBarrier(2);
long start = System.currentTimeMillis();
executorService.execute(new Runnable() {
@Override
public void run() {
try {
// 模拟业务执行了5秒
Thread.sleep(5000);
// 模拟获取name
ademo.setName("优快云:孟秋与你");
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
System.out.println("姓名: " + ademo.getName() + " 年龄:" + ademo.getAge());
}
});
executorService.execute(() -> {
try {
// 模拟业务执行了2秒
Thread.sleep(2000);
// 模拟获取age
ademo.setAge(18);
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
System.out.println("姓名: " + ademo.getName() + " 年龄:" + ademo.getAge());
});
}
public static void main(String[] args) {
// 有name age字段的一个实体类
Ademo ademo = new Ademo();
// 实际使用 需要手动创建 防止OOM
ExecutorService executorService = Executors.newFixedThreadPool(2);
// 严格控制构造参数数量 参数大于实际线程数 将会陷入无限等待!
CyclicBarrier cyclicBarrier = new CyclicBarrier(2);
long start = System.currentTimeMillis();
executorService.execute(new Runnable() {
@Override
public void run() {
try {
// 模拟业务执行了5秒
Thread.sleep(5000);
// 模拟获取name
ademo.setName("优快云:孟秋与你");
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
System.out.println("姓名: " + ademo.getName() + " 年龄:" + ademo.getAge());
}
});
executorService.execute(() -> {
try {
// 模拟业务执行了2秒
Thread.sleep(2000);
// 模拟获取age
ademo.setAge(18);
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
System.out.println("姓名: " + ademo.getName() + " 年龄:" + ademo.getAge());
});
}
CountDownLatch 和 CyclicBarrier 的区别
如果我们去网上搜索区别 得到一些概念性的东西,并不能帮助我们理解,结合博主上面两个例子,应该就能很好的理解了
除了CyclicBarrier可以重复使用外,它们之间的区别:
CountDownLatch : 会阻塞主线程 倾向于所有线程都执行完成 汇聚到主线程再往下
CyclicBarrier :阻塞子线程 倾向于所有子线程都到了同一进度 再继续各自执行
数据库中有效期和状态字段更新问题
这是一个非常典型的问题,假设我们数据库有valid_start_date ,valid_end_date,status字段,
比如身份证证有效期:2014-01-01至2024-01-01, 我们在2023年12月31号入库这条数据,status状态是有效的,过两天之后 这个状态就应该为失效;
如果按照三大范式,不要status这个字段 每次都通过代码判断 自然不会有什么问题。
但很多时候 我们为了方便各种业务操作,很可能会冗余这个字段 就需要额外维护status这个字段, 通常很常见的方式是每天半夜定时去更新这个字段;
定时更新会有点小问题:实时性不高,比如在0点定时更新了 status为有效状态,证件在某小时某分钟后过期,而定时器再次更新需要等到次日0点; 即使缩短定时器间隔 也会有一样的问题;
(硬要用定时器刷 其实也有个技巧,我们可以在代码中计算出两次定时周期内过期的数据,比如2024-05-14 00:00 执行了一次定时器 下一次是2024-05-15 00:00 才执行,那我们就要取出例如2024-05-14 05:00 过期的数据 ,使用的线程池的延迟线程来更新状态 设置延迟时间为5小时,但是本地线程需要考虑万一宕机 业务上能不能接受状态未更新成功 稳妥一点就是用mq了 这需要根据项目性质、规模自行判断)
此外,我们可以考虑在触发查询的时候再去比较出状态是否有效,并且更新数据库的status字段,这在分页的场景+实时性要求高的场景下 极为合适。
当然,查询时更新也并不一定适合任何场景,比如查询频率非常高,且过期的粒度不高(即没有精确到时、分、秒才过期),可能半夜定时刷会合适些,具体看业务,这里只是提供一种思路。
java中的goto
也许各位会看过这句话:虽然java保留了goto关键字,但是java中没有goto
其实是有的 只是不叫goto 而是用打标签的形式,因为用得太少了 以至于博主也忘记了还有这个特性,最近在翻线程池源码 addWorker方法中,看到了这个用法 突然想到在for for循环嵌套中 还是能够用上的。
(友情提示:慎用,因为goto会降低代码可读性,在公司项目使用挨骂了 别说是博主推荐你们用的,此处只是作为一个学习掌握的例子)
public static void main(String[] args) {
int a = 0;
// 作为一个标记 retry算是一个规范命名(jdk源码里面这么命名的)
// 硬要替换成aaa ,bbb 也是可以跳转的
retry:
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 2; j++) {
if (i == 1) {
a = i;
// 跳到retry标记的地方
break retry;
}
}
// 不会进入
if (i == 2) {
a = i;
System.out.println("------");
}
}
// a = 1
System.out.println(a);
}
public static void main(String[] args) {
int a = 0;
// 作为一个标记 retry算是一个规范命名(jdk源码里面这么命名的)
// 硬要替换成aaa ,bbb 也是可以跳转的
retry:
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 2; j++) {
if (i == 1) {
a = i;
// 跳到retry标记的地方
break retry;
}
}
// 不会进入
if (i == 2) {
a = i;
System.out.println("------");
}
}
// a = 1
System.out.println(a);
}
设计位数较短的唯一id思路
(注:本点涉及的id算法 是博主原创写法 且博主自己需要在项目中使用,所以只是聊思路 不会提供代码; 场景需求并不常见,不感兴趣可以跳过不看 )
如果单纯是唯一id 那么雪花算法已经非常成熟了,通过时间戳、机器id来生成的,需要考虑的就是同一瞬间内(比如同一毫秒/纳秒)的数据如何处理。
但是如果有一天 接到了需求 要求生成的id位数很短(远小于任何雪花算法生成的位数 比如10位11位),那该如何处理呢?
我们首先想到的 可能还是根据时间戳来处理,仿写雪花算法 进行截取
那么就不得不考虑 纳秒占了多少位数?(System.nano() )
一开始博主想到的方式是 通过ZonedDateTime.now()来获取
ZonedDateTime now = ZonedDateTime.now();
int year = now.getYear();
// 当前是今年的第几天
int day = now.getDayOfYear();
int hour = now.getHour();
int minute = now.getMinute();
int second = now.getSecond();
// 后面位数全是0 没有区分意义 所以除以1000000
int nano = now.getNano()/1000000;
ZonedDateTime now = ZonedDateTime.now();
int year = now.getYear();
// 当前是今年的第几天
int day = now.getDayOfYear();
int hour = now.getHour();
int minute = now.getMinute();
int second = now.getSecond();
// 后面位数全是0 没有区分意义 所以除以1000000
int nano = now.getNano()/1000000;
这些数字拼接起来 位数是远远超过了范围的,那么我们首先想到的 是截取,比如年份 截短至2位,但即使如此位数也是超过了范围的
于是博主想到了转32进制 , 这样可以极大的压缩位数
String yearStr = Integer.toString(Integer.parseInt(String.valueOf(year).substring(2,4)), 32).toUpperCase();
String dayStr = Integer.toString(day, 32).toUpperCase();
String hourStr = Integer.toString(hour, 32).toUpperCase();
String minuteStr = Integer.toString(minute, 32).toUpperCase();
String secondStr = Integer.toString(second, 32).toUpperCase();
String nanoStr = Integer.toString(nano, 32).toUpperCase();
String str = yearStr+dayStr+hourStr+minuteStr+secondStr+nanoStr;
String yearStr = Integer.toString(Integer.parseInt(String.valueOf(year).substring(2,4)), 32).toUpperCase();
String dayStr = Integer.toString(day, 32).toUpperCase();
String hourStr = Integer.toString(hour, 32).toUpperCase();
String minuteStr = Integer.toString(minute, 32).toUpperCase();
String secondStr = Integer.toString(second, 32).toUpperCase();
String nanoStr = Integer.toString(nano, 32).toUpperCase();
String str = yearStr+dayStr+hourStr+minuteStr+secondStr+nanoStr;
我们发现转进制是一个非常不错的压缩长度思路,32进制的两位数就可以表示10进制所有三位范围内(999以内)的数;所以原本三位数的dayStr 和 nanoStr 都可以压缩为2位数,而原本最大只能为24的hourStr 可以压缩为1位数。
但是 它只是一个压缩长度的思路(日后有其它需要压缩的场景可以考虑32进制思路),然而作为id显然是不行的,数据量如此巨大 用字符串作为id 效率将会是灾难!
我们暂且先抛开字符串效率问题 还需要考虑的是 数据量单表在亿级的项目 同一纳秒又会有多少重复数据?
我们可能会考虑到 同一纳秒内的数据 去做自增;既然都要自增了,为什么一开始不自增呢?于是转换思路,考虑纯数字的自增方式。
相信大家都清楚redis的自增,也看过不少文章说redis自增不靠谱,不靠谱的原因在在于redis宕机了 数据还没有持久化;
应对方法自然是调整持久化策略,部署redis集群 (在博主博客首页搜索redis哨兵模式可以看到相关教程);
可能有同学会问 如果集群全部都挂了 数据还没有持久化呢 自增不也是不靠谱?没错,但是既然到所有集群都挂了的地步 这是多重大的故障 难道还能逃过老老实实回去加班的命运吗?集群的目的本来就是容灾 所以我们不该本末倒置,这个时候手动运维处理一下自增值 又有什么毛病呢?
自增面临最大的挑战就是数据透明,一眼就能看出编号顺序,所以我们需要进行一下混淆以及算法来打乱顺序。
我们可以设置一个10位数初始值(假设需求是id为10位数)与递增数相加 : 例如100000000 + 递增数 ;这里可以采用多个首位不同的key递增,在lua里面用当前时间取余,取个随机key,起到分散效果。
再加上时间 时间 = (当前时间秒数 - 项目上线时间秒数) / n ,这里总体就是起到加个随机数的作用,这个随机数是个简单的递增函数 来保证不会重复+打散作用
恺撒密码 交换位置顺序 比如第2,3位和第6,7位交换 以此类推
交换后,规律其实还是很明显,这时候我们可以做位运算
redis带的lua脚本版本只有基本的操作 得考虑如何实现运算
做完位运算 再次恺撒密码交换
博主的需求只需要考虑唯一性 不需要考虑递增 考虑递增对算法会更苛刻!
需要考虑redis集群 主从同步延迟的情况 因为数据量大的项目 任何极端情况都可能为常态 所以需要增加一下判断 校验,并且保证本次自增数大于上次自增数 (是不是和时钟回拨有点像?) (这里并不能杜绝,杜绝还是得靠数据库唯一索引,因为保存的上次自增id 在出现故障时 数据也不一定是最新的)
以上所有操作 需要原子性执行,博主是在lua脚本中完成的; 建议自写lua脚本,即使引入框架 如redisson 也是用lua脚本写的
多线程中如何传递spring上下文
我们知道spring的上下文是基于当前线程的,存储在RequestContextHolder中,本质是通过ThreadLocal来存储的
传递上下文,只需要在runable里面,把上下文存到inheritableRequestAttributesHolder里面即可
 > tips:requestAttributesHolder和inheritableRequestAttributesHolder的区别在于,前者作用域:仅限于当前线程,这个变量在当前线程中存储的值不会被子线程继承。
> tips:requestAttributesHolder和inheritableRequestAttributesHolder的区别在于,前者作用域:仅限于当前线程,这个变量在当前线程中存储的值不会被子线程继承。
后者作用域:当前线程及其子线程均可访问,这个变量的值会被子线程继承。
伪代码:
new Runable(){
@Override
public void run(){
try{
// 通常我们还需要把traceId传入 traceId需要自实现
MDC.put("traceId", traceId);
RequestAttributes attributes = RequestContextHolder.getRequestAttributes();
ServletRequestAttributes servletRequestAttributes = (ServletRequestAttributes)attributes;
RequestContextHolder.resetRequestAttributes();
// 存到 inheritableRequestAttributesHolder
RequestContextHolder.setRequestAttributes(sra, true);
}
}catch (Exception ex){}
finally {
RequestContextHolder.resetRequestAttributes();
MDC.remove("traceId");
}
}
new Runable(){
@Override
public void run(){
try{
// 通常我们还需要把traceId传入 traceId需要自实现
MDC.put("traceId", traceId);
RequestAttributes attributes = RequestContextHolder.getRequestAttributes();
ServletRequestAttributes servletRequestAttributes = (ServletRequestAttributes)attributes;
RequestContextHolder.resetRequestAttributes();
// 存到 inheritableRequestAttributesHolder
RequestContextHolder.setRequestAttributes(sra, true);
}
}catch (Exception ex){}
finally {
RequestContextHolder.resetRequestAttributes();
MDC.remove("traceId");
}
}
在servlet相关操作时,应该保持谨慎,
例如:
需要明确清楚 流只能读取一次(request inputstream)
例如:
在runalbe里面开启了AsyncContext asyncContext = request.startAsync();
如果在for循环中使用线程池,就会导致一次request请求 调用了多次startAsync方法,会报错:UT010028: Async processing already started
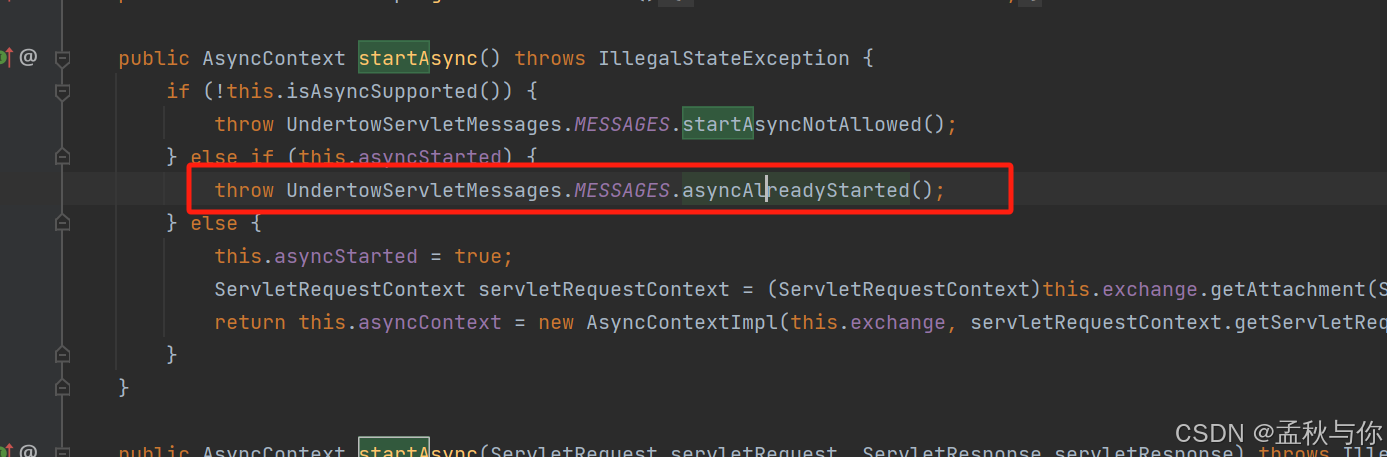
UT010XXX编号的错误都在下面这个类中,这个错误提示语是用字符串写死的
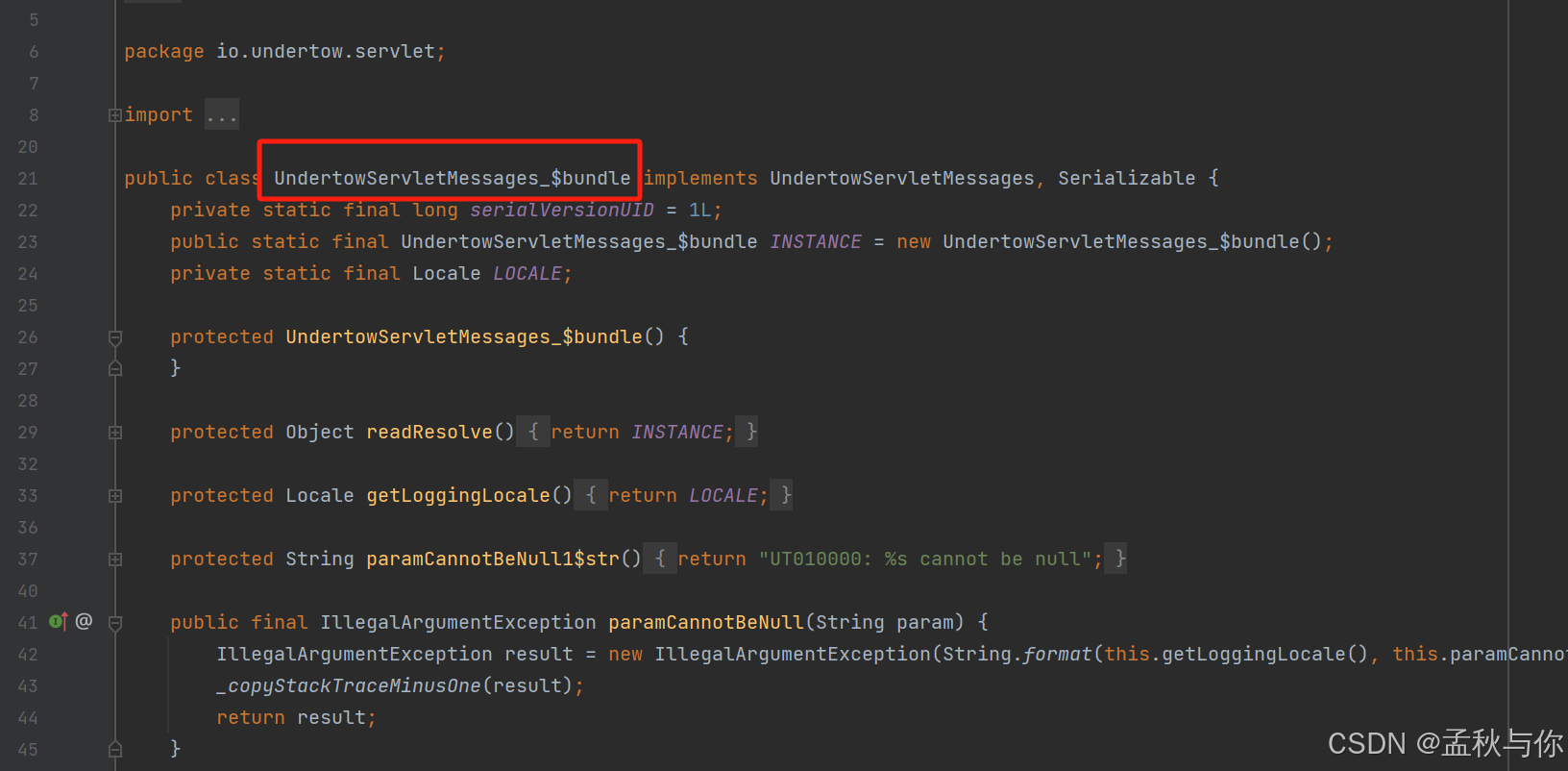
UT0
如何获取项目中所有接口url和请求方式
我们做接口权限,基本都是在库表中配置url和roleId,并根据当前登录的roleId去判断的;
那么在此之前,比较重要的一个想法就是能不能把已有的url都获取出来。
其实有个我们常用的框架 已经做到了这一步: swagger ;
那说明一定是有办法可以做到的;
其实核心是从requestMappingHandlerMapping中获取 直接上代码
import io.swagger.annotations.ApiOperation;
import org.springblade.modules.perm.apibean.UrlPathMethodVO;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.ApplicationContext;
import org.springframework.stereotype.Component;
import org.springframework.web.bind.annotation.DeleteMapping;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.PutMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.method.HandlerMethod;
import org.springframework.web.servlet.mvc.method.RequestMappingInfo;
import org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerMapping;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.Set;
/** * @author: csdn:孟秋与你 **/
@Component
public class ApiEndpointsController {
@Autowired
private ApplicationContext applicationContext;
public List<UrlPathMethodVO> getAllApiEndpoints() {
List<UrlPathMethodVO> apiEndpoints = new ArrayList<>();
RequestMappingHandlerMapping requestMappingHandlerMapping =
(RequestMappingHandlerMapping) applicationContext.getBean("requestMappingHandlerMapping");
Map<RequestMappingInfo, HandlerMethod> handlerMethods = requestMappingHandlerMapping.getHandlerMethods();
for (Map.Entry<RequestMappingInfo, HandlerMethod> entry : handlerMethods.entrySet()) {
RequestMappingInfo mappingInfo = entry.getKey();
HandlerMethod handlerMethod = entry.getValue();
// 检查是否有@ApiOperation注解或4大请求方式注解
// (若项目不是restful 都为@ReqeustMapping注解 则需要自行修改下面判断代码)
if (handlerMethod.hasMethodAnnotation(ApiOperation.class)
|| handlerMethod.hasMethodAnnotation(GetMapping.class)
|| handlerMethod.hasMethodAnnotation(PostMapping.class)
|| handlerMethod.hasMethodAnnotation(PutMapping.class)
|| handlerMethod.hasMethodAnnotation(DeleteMapping.class)
) {
Set<String> patterns = mappingInfo.getPatternsCondition().getPatterns();
Set<RequestMethod> methods = mappingInfo.getMethodsCondition().getMethods();
for (String urlPattern : patterns) {
methods.forEach(
item -> {
String remark = "";
if (handlerMethod.hasMethodAnnotation(ApiOperation.class)) {
ApiOperation methodAnnotation = handlerMethod.getMethodAnnotation(ApiOperation.class);
remark = methodAnnotation.value();
}
apiEndpoints.add(new UrlPathMethodVO(urlPattern, item.name(), remark));
}
);
}
}
}
return apiEndpoints;
}
}
import io.swagger.annotations.ApiOperation;
import org.springblade.modules.perm.apibean.UrlPathMethodVO;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.ApplicationContext;
import org.springframework.stereotype.Component;
import org.springframework.web.bind.annotation.DeleteMapping;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.PutMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.method.HandlerMethod;
import org.springframework.web.servlet.mvc.method.RequestMappingInfo;
import org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerMapping;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.Set;
/** * @author: csdn:孟秋与你 **/
@Component
public class ApiEndpointsController {
@Autowired
private ApplicationContext applicationContext;
public List<UrlPathMethodVO> getAllApiEndpoints() {
List<UrlPathMethodVO> apiEndpoints = new ArrayList<>();
RequestMappingHandlerMapping requestMappingHandlerMapping =
(RequestMappingHandlerMapping) applicationContext.getBean("requestMappingHandlerMapping");
Map<RequestMappingInfo, HandlerMethod> handlerMethods = requestMappingHandlerMapping.getHandlerMethods();
for (Map.Entry<RequestMappingInfo, HandlerMethod> entry : handlerMethods.entrySet()) {
RequestMappingInfo mappingInfo = entry.getKey();
HandlerMethod handlerMethod = entry.getValue();
// 检查是否有@ApiOperation注解或4大请求方式注解
// (若项目不是restful 都为@ReqeustMapping注解 则需要自行修改下面判断代码)
if (handlerMethod.hasMethodAnnotation(ApiOperation.class)
|| handlerMethod.hasMethodAnnotation(GetMapping.class)
|| handlerMethod.hasMethodAnnotation(PostMapping.class)
|| handlerMethod.hasMethodAnnotation(PutMapping.class)
|| handlerMethod.hasMethodAnnotation(DeleteMapping.class)
) {
Set<String> patterns = mappingInfo.getPatternsCondition().getPatterns();
Set<RequestMethod> methods = mappingInfo.getMethodsCondition().getMethods();
for (String urlPattern : patterns) {
methods.forEach(
item -> {
String remark = "";
if (handlerMethod.hasMethodAnnotation(ApiOperation.class)) {
ApiOperation methodAnnotation = handlerMethod.getMethodAnnotation(ApiOperation.class);
remark = methodAnnotation.value();
}
apiEndpoints.add(new UrlPathMethodVO(urlPattern, item.name(), remark));
}
);
}
}
}
return apiEndpoints;
}
}
/** * @author 孟秋与你 */
@ApiModel("所有路径")
@Data
@NoArgsConstructor
@AllArgsConstructor
@EqualsAndHashCode
public class UrlPathMethodVO implements Serializable {
@ApiModelProperty("路径")
private String url;
@ApiModelProperty("请求方法")
private String method;
@ApiModelProperty("描述")
private String remark;
}
/** * @author 孟秋与你 */
@ApiModel("所有路径")
@Data
@NoArgsConstructor
@AllArgsConstructor
@EqualsAndHashCode
public class UrlPathMethodVO implements Serializable {
@ApiModelProperty("路径")
private String url;
@ApiModelProperty("请求方法")
private String method;
@ApiModelProperty("描述")
private String remark;
}
如何在内存中实现分页
接上文,通过requestMappingHandlerMapping获取了项目所有的url ;希望返回给前端页面展示时,做一个内存中的分页(而不是mysql的分页)
避坑:注意不要使用stream流的skip 和 limit来分页,会有bug
反面教材:
// 错误代码
apiEndpoints.stream()
.skip((long) query.getSize() * (query.getCurrent() - 1))
.limit(query.getSize())
.collect(Collectors.toList()));
// 错误代码
apiEndpoints.stream()
.skip((long) query.getSize() * (query.getCurrent() - 1))
.limit(query.getSize())
.collect(Collectors.toList()));
比如有676条数据, current是1 size是700 这个stream流的写法,就把700条数据全部skip了。 但是按照mysql分页的正常逻辑 应该是要返回676条数据的,此外 假设current是4 size是200, 那这个时候应该是要能返回最后的76条数据的 ,它同样全部skip了
正面教材:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<!--自行注意版本 没记错的话guava某些版本和swagger2某些版本会有冲突-->
<version>30.1.1-jre</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<!--自行注意版本 没记错的话guava某些版本和swagger2某些版本会有冲突-->
<version>30.1.1-jre</version>
</dependency>
// 内存实现分页
List<List<UrlPathMethodVO>> partition = Lists.partition(apiEndpoints, query.getSize());
// 如果current超过了总页数,返回空数组
if (query.getCurrent() > partition.size()) {
return R.data(Lists.newArrayList());
}
// 返回对应的分区 (注意current在项目中是否从1开始)
return R.data(partition.get(query.getCurrent() - 1));
// 内存实现分页
List<List<UrlPathMethodVO>> partition = Lists.partition(apiEndpoints, query.getSize());
// 如果current超过了总页数,返回空数组
if (query.getCurrent() > partition.size()) {
return R.data(Lists.newArrayList());
}
// 返回对应的分区 (注意current在项目中是否从1开始)
return R.data(partition.get(query.getCurrent() - 1));
如何实现接口参数全局解密
核心思路:
拦截每次请求
修改request中的参数
把修改后的参数设置回去(难点)
具体做法需要单开一篇博客 ,博主会讲述遇到的坑;
可前往博主主页(csdn:孟秋与你)搜索: springboot接口参数全局解密
spring bean和静态方法、静态变量混用问题
基础的概念就不讲了 直接上段博主封装的一个工具类代码示例 ,
核心是initialize方法, 在初始化时 把bean属性放入了类对象属性里面,
可能有点绕 多看几遍都能看懂
/** * Description: dict 2 str * date: 2024/8/29 10:58 * * @author 孟秋与你 */
@Component
public class DictConvert<T> {
@Autowired
private InnerConvert innerConvert;
private static DictConvert convert;
/** * @param list 原始list * @param column 要转换的列 * @param dictCode 字典dict code * @param <T> * @return */
public static <T> List decodeColumn(List<?> list, SFunction<T, ?> column, String dictCode) {
return convert.innerConvert.decodeColumn(list, column, dictCode);
}
/** * 没有其它合适的重载方法 只能写有限个固定参数 参照 jdk9 Map.of(K,V)写法 */
public static <T> List decodeColumn(List<?> list, SFunction<T, ?> column1, String dictCode1, SFunction<T, ?> column2, String dictCode2) {
return convert.innerConvert.decodeColumn(list, column1, dictCode1, column2, dictCode2);
}
public static <T> List decodeColumn(List<?> list, SFunction<T, ?> column1, String code1, SFunction<T, ?> column2, String code2, SFunction<T, ?> column3, String code3) {
return convert.innerConvert.decodeColumn(list, column1, code1, column2, code2, column3, code3);
}
public static <T> List decodeColumn(List<?> list, SFunction<T, ?> column1, String code1, SFunction<T, ?> column2, String code2, SFunction<T, ?> column3, String code3,
SFunction<T, ?> column4, String code4) {
return convert.innerConvert.decodeColumn(list, column1, code1, column2, code2, column3, code3, column4, code4);
}
@PostConstruct
private void initialize() {
convert = this;
convert.innerConvert = this.innerConvert;
}
}
/** * Description: dict 2 str * date: 2024/8/29 10:58 * * @author 孟秋与你 */
@Component
public class DictConvert<T> {
@Autowired
private InnerConvert innerConvert;
private static DictConvert convert;
/** * @param list 原始list * @param column 要转换的列 * @param dictCode 字典dict code * @param <T> * @return */
public static <T> List decodeColumn(List<?> list, SFunction<T, ?> column, String dictCode) {
return convert.innerConvert.decodeColumn(list, column, dictCode);
}
/** * 没有其它合适的重载方法 只能写有限个固定参数 参照 jdk9 Map.of(K,V)写法 */
public static <T> List decodeColumn(List<?> list, SFunction<T, ?> column1, String dictCode1, SFunction<T, ?> column2, String dictCode2) {
return convert.innerConvert.decodeColumn(list, column1, dictCode1, column2, dictCode2);
}
public static <T> List decodeColumn(List<?> list, SFunction<T, ?> column1, String code1, SFunction<T, ?> column2, String code2, SFunction<T, ?> column3, String code3) {
return convert.innerConvert.decodeColumn(list, column1, code1, column2, code2, column3, code3);
}
public static <T> List decodeColumn(List<?> list, SFunction<T, ?> column1, String code1, SFunction<T, ?> column2, String code2, SFunction<T, ?> column3, String code3,
SFunction<T, ?> column4, String code4) {
return convert.innerConvert.decodeColumn(list, column1, code1, column2, code2, column3, code3, column4, code4);
}
@PostConstruct
private void initialize() {
convert = this;
convert.innerConvert = this.innerConvert;
}
}
spring项目中动态取值方案合集
动态取值意味着不停机不重启就能重新取值,博主才浅学疏,例举出用过的几种方案:
tips: 动态取值往往可能是以牺牲小部分性能为代价,根据项目实际情况斟酌方案。
字典配置化: 即把需要动态取值的数据放到数据库中,比如枚举的配置,这是最常见的做法,但局限性也大,适合简单的取值。
字典配置化:
即把需要动态取值的数据放到数据库中,比如枚举的配置,这是最常见的做法,但局限性也大,适合简单的取值。
properties 文件动态取值:
有的时候我们配置需要写在properties 文件里面,为此特地建表存储在数据库显得格格不入,不愿意建库表的时候该怎么办呢?property同样也能实现动态取值:
String key= "";
Properties prop = new Properties();
try {
// 相对路径+properties名
// org.springframework.core.io.support 包下的PropertiesLoaderUtils
prop = PropertiesLoaderUtils.loadAllProperties("relative/xxx.properties");
// key名
key= prop.getProperty("key");
} catch (IOException e) {
e.printStackTrace();
}
String key= "";
Properties prop = new Properties();
try {
// 相对路径+properties名
// org.springframework.core.io.support 包下的PropertiesLoaderUtils
prop = PropertiesLoaderUtils.loadAllProperties("relative/xxx.properties");
// key名
key= prop.getProperty("key");
} catch (IOException e) {
e.printStackTrace();
}
原理是每次都会创建一个新的WebappClassLoader去加载文件
sql配置化 - 动态sql配置:
典型的报表导出业务,报表导出的需求是极易变更的,这个时候我们可以把整条sql存在数据库里面通过占位符去替换(注意sql注入的问题)
伪代码:
Map<String, String> params = new HashMap();
params.put("orderId",xxx);
// put other
// 查询出规则 sql ,
//例如sql为 select code,name from t_order where id = {orderId}
String sql = configMapper.getConfigRule(templateNo);
// 遍历map , 替换模板规则
//(替换sql里面的占位符,所以map可以预设较多的参数,sql是可以动态改的,但是代码不易变更)
sql = sql.replaceAll("\\{" + (String)entry.getKey() + "}", (String)entry.getValue());
// 执行替换后的规则
configMapper.executeRule(sql)
// xml :
<select id="executeRule" resultType="java.util.Map">
${statement}
</select>
Map<String, String> params = new HashMap();
params.put("orderId",xxx);
// put other
// 查询出规则 sql ,
//例如sql为 select code,name from t_order where id = {orderId}
String sql = configMapper.getConfigRule(templateNo);
// 遍历map , 替换模板规则
//(替换sql里面的占位符,所以map可以预设较多的参数,sql是可以动态改的,但是代码不易变更)
sql = sql.replaceAll("\\{" + (String)entry.getKey() + "}", (String)entry.getValue());
// 执行替换后的规则
configMapper.executeRule(sql)
// xml :
<select id="executeRule" resultType="java.util.Map">
${statement}
</select>
究极方案:脚本语言 - 代码配置化
如果遇到更复杂的场景,又需要动态获取,那么就引入脚本语言,这不再是sql配置化这么简单,而是整个代码片段当成配置
(请务必注意安全,不要将配置脚本做成接口入参对外提供!!)
这里以groovy脚本为例
<dependency>
<groupId>org.codehaus.groovy</groupId>
<artifactId>groovy</artifactId>
</dependency>
<dependency>
<groupId>org.codehaus.groovy</groupId>
<artifactId>groovy</artifactId>
</dependency>
伪代码示例:
GroovyShell shell = new GroovyShell();
// import导入替换成自己的类
Script script = shell.parse("import com.qiuhuanhen.core.tool.utils.SpringUtil\n" +
"import com.qiuhuanhen.modules.web.entity.Order\n" +
"import com.qiuhuanhen.modules.web.model.dto.CustomerDTO\n" +
"import com.qiuhuanhen.modules.web.service.inf.OrderService\n" +
"import com.qiuhuanhen.modules.web.service.inf.CustomerService\n" +
"\n" +
"def orderId = binding.variables.get(\"order_id\") as Long\n" +
"\n" +
"Order order = SpringUtil.getBean(OrderService.class).getById(orderId) \n" +
"\n" +
"if (order == null ){\n" +
"return null\n" +
"}\n" +
"\n" +
"CustomerDTO customer = SpringUtil.getBean(CustomerService.class).getByNo(order.getCustomerNo()).orElse(new CustomerDTO()) \n" +
"if (customer == null){\n" +
"return null \n" +
"}\n" +
"\n" +
"return customer.getRealName()\n");
Binding binding = new Binding();
// 业务参数 入参
Map<String, Object> bizMap = new HashMap<>();
// put...
bizMap.forEach(
// 将业务参数绑定
binding::setVariable
);
// 这里假设有个order_id参数
binding.setVariable("order_id",111);
// 绑定至脚本
script.setBinding(binding);
// 执行脚本
Object run = script.run();
System.out.println(run);
GroovyShell shell = new GroovyShell();
// import导入替换成自己的类
Script script = shell.parse("import com.qiuhuanhen.core.tool.utils.SpringUtil\n" +
"import com.qiuhuanhen.modules.web.entity.Order\n" +
"import com.qiuhuanhen.modules.web.model.dto.CustomerDTO\n" +
"import com.qiuhuanhen.modules.web.service.inf.OrderService\n" +
"import com.qiuhuanhen.modules.web.service.inf.CustomerService\n" +
"\n" +
"def orderId = binding.variables.get(\"order_id\") as Long\n" +
"\n" +
"Order order = SpringUtil.getBean(OrderService.class).getById(orderId) \n" +
"\n" +
"if (order == null ){\n" +
"return null\n" +
"}\n" +
"\n" +
"CustomerDTO customer = SpringUtil.getBean(CustomerService.class).getByNo(order.getCustomerNo()).orElse(new CustomerDTO()) \n" +
"if (customer == null){\n" +
"return null \n" +
"}\n" +
"\n" +
"return customer.getRealName()\n");
Binding binding = new Binding();
// 业务参数 入参
Map<String, Object> bizMap = new HashMap<>();
// put...
bizMap.forEach(
// 将业务参数绑定
binding::setVariable
);
// 这里假设有个order_id参数
binding.setVariable("order_id",111);
// 绑定至脚本
script.setBinding(binding);
// 执行脚本
Object run = script.run();
System.out.println(run);
xml/json 动态取值
xml : 通过xpath动态取值
json: 通过jsonpath动态取值
<!-- json path-->
<dependency>
<groupId>com.jayway.jsonpath</groupId>
<artifactId>json-path</artifactId>
<!-- 需要注意有没有版本更新 一般更新都是因为旧版本发现CVE漏洞 -->
<version>2.9.0</version>
</dependency>
<!-- json path-->
<dependency>
<groupId>com.jayway.jsonpath</groupId>
<artifactId>json-path</artifactId>
<!-- 需要注意有没有版本更新 一般更新都是因为旧版本发现CVE漏洞 -->
<version>2.9.0</version>
</dependency>
spring的@RequestParam到底有什么用
很多时候是不是感觉写不写都一样?那它到底有什么用途呢?
给参数取别名 (或者说get请求版的@JsonProperty 会不会更好理解?) 一般自己项目是不需要去特地取个别名的 , 但如果对接第三方项目, 第三方用的python或其它习惯下划线命名变量的语言,java又习惯用驼峰,当你不愿意写个下划线变量时,这个注解就有用了
给参数取别名
(或者说get请求版的@JsonProperty 会不会更好理解?)
一般自己项目是不需要去特地取个别名的 , 但如果对接第三方项目,
第三方用的python或其它习惯下划线命名变量的语言,java又习惯用驼峰,当你不愿意写个下划线变量时,这个注解就有用了
@GetMapping
public void test(@RequestParam("order_name") String orderName) {
// do something
}
@GetMapping
public void test(@RequestParam("order_name") String orderName) {
// do something
}
参数声明为非必传 默认orderName是必传的
如果我们希望该接口的参数是非必传的 注解声明required = false即可
@GetMapping
public void test(@RequestParam("order_name",required = false) String orderName) {
// do something
}
@GetMapping
public void test(@RequestParam("order_name",required = false) String orderName) {
// do something
}
Map传参
url格式为: /xxxxx/test?name=孟秋与你
@GetMapping("/test")
public void test(@RequestParam Map<String,String> map) {
// key: name value : 孟秋与你
}
@GetMapping("/test")
public void test(@RequestParam Map<String,String> map) {
// key: name value : 孟秋与你
}
内存缓存应用场景
在java中,有许多内存缓存框架(如guava的cache、Caffeine); 但我们知道内存不靠谱,一旦宕机 数据将会丢失,所以往往都是用redis作为缓存,那么到底什么场景内存缓存可以使用上呢?
大家第一反应可能是:不重要的数据可以放本地内存,但这回答就有点像我上清华和不上清华一样 太泛了。
博主举个遇到可用本地缓存的真实场景:
接口权限、接口级限流
这两者本质都差不多:
1.先从数据库加载配置 存入本地缓存,
提供一个定时器刷新本地缓存内容(或运维接口手动触发刷新),
2.拦截器中通过匹对reqeust和本地缓存的内容决定是否放行
我们简单聊一聊本地缓存优势:
因为拦截器是全局的,所有接口都会进入拦截器,如果在拦截器里面直接访问数据库是绝对不理智的,在并发高的项目中,会有大量的IO消耗; 如果放在redis中,也会有大量的网络消耗,我们项目去请求redis,会消耗redis的连接数;况且redis快是指它本身快,但远端服务去请求redis,影响因素一定是带宽;而本地缓存则不会有上述问题。
那用本地缓存 万一丢失会有什么问题吗?
本地缓存丢失 其实就是宕机了,服务都挂了 要接口拦截、限流的配置数据干嘛呢?
等到项目重启时,重新加载回去本地缓存即可。


















 2559
2559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











