



一、概述
1.编译型和解释型语言
编译型:程序之前前需要一个专门的编译过程,把程序编译成机器语言文件,运行时不需要重新编译。程序运行效率高,跨平台性差
解释型:程序不进行预先的编译,程序执行时逐行解释;运行效率较低但具有跨平台性
2.Python的设计目标
简单直观的语言;开源,供任何人共同开发;易于理解;使用短期开发项目
3.Python特点
完全面向对象;拥有一个强大的标准库;提供大量的第三方模块
二、第一个Python程序
1.Python源程序格式
Python源程序是一个特殊格式的文本文件,可以使用任意文本编辑器;文件可扩展名.py
与大多数UNIX系统和服务不同,Windows系统没有预安装Python。为了方便直接使用Linux操作系统
print("hello python")
print("hello hello world")
Python中代码必须整齐,不要有缩进;否则报错;初期不要加缩进

python2.x 版本不支持中文;pythonn3.x默认支持;下面使用python3运行程序

Python中的注释采用 # 进行单行注释;为了保证代码的整体,官方建议# 后面添加一个空格;如果和代码写在一行,建议代码和注释之间有两个空格
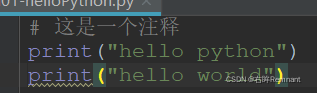
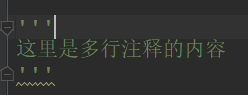
多行注释使用连续的引号,单引号或双引号都可以
我改用IDEA了(heihei)
2.执行Python的方式
1.解释器类型
# 2.x 版本 语法: python 文件名
3.x 版本 语法: python3 文件名
3.x 版本 语法: python3 文件名
2.交互型
命令行终端 输入:python后,输入python代码
缺点:适合小功能的语法学习,不方便大量程序编写;退出后(exit() / ctrl + D)代码不能保存
3.集成开发软件(PyCharm)
三、Python基础语法
1.算术运算符
Python中 + 可以用于相同数据类型对象的相加,但不支持字典和集合
这里不同的就是 幂,采用两个**
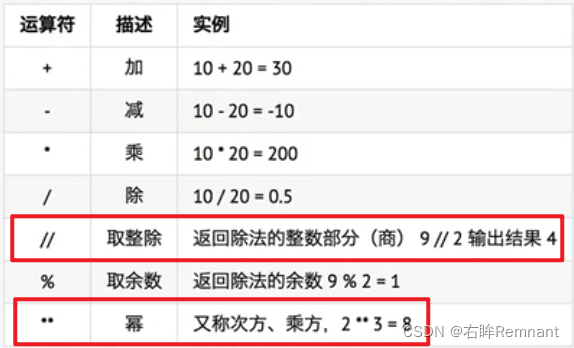
- 运算符还可以用于字符串,用于重复 给定字符串相应的次数
print("test" * 10)
输出:testtesttesttesttesttesttesttesttesttest
print("test" * 10)
输出:testtesttesttesttesttesttesttesttesttest
2.变量
Python的变量只用第一次出现才算定义变量;Python中不需要指定数据的类型,程序运行时由解释器自动推断准确类型
数据类型分为:数字型和非数字型
数字型:int, float, bool, complex(复数型,主要用于科学计算,如波动问题,微积分)
非数字型:字符串,列表,元祖,字典
Python3中,int 和 long 被整合到一起,只有一个 int 类型,不需要进行区分
Python中,bool类型的true表示1, false表示0
数字型变量之间是可以直接进行计算的
Python中,bool类型的true表示1, false表示0
数字型变量之间是可以直接进行计算的
2.2 转义字符:当在字符串中包含\n等会被认为是转义字符,在字符串前面添加r或R表示不转义。
如:r‘C:\windows\notepad.exe’
变量的输入:使用函数input()
格式:字符串变量 = input(“字符串提示信息”)
类型转换函数:int(x), float(x)
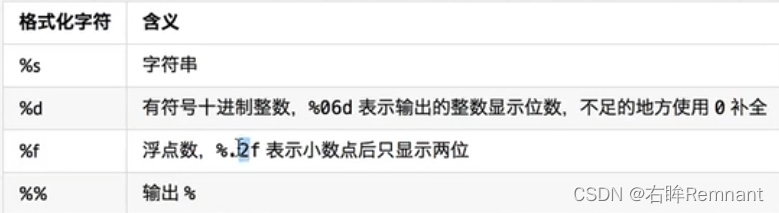
输入格式化与其他语言类似, 如:
print("苹果价格 %f, 重量 %d, 共花费 %f" % (apple_price, apple_weight, money))
print("苹果价格 %f, 重量 %d, 共花费 %f" % (apple_price, apple_weight, money))
3.分支语句
if 语句,书写格式:
if 条件判断:
成立执行的代码
成立执行的代码
Python中缩进使用Tab或者四个空格,建议使用空格
Python中不需要使用{}, 对于if中的多条语句使用缩进进行判断;
Python中的elif 中间没有空格,用于多分支判断
value = 17
if value >= 18:
print("if内部")
print("if第二句") # if语句结束部分
print("if外部")
Python中的逻辑连接词是 and, or, not
Python中没有自增运算
4.while循环
让指定代码重复执行

Python中的print自带换行,如果不希望添加,可以在print内部加入end=“”
Python总的for循环,使用for … in 进行迭代遍历
5. 函数
5.1 基本使用
Python中定义函数语法:def 函数名():
def sum(num1, num2):
"""对两个数进行求和"""
return num1 + num2
res = sum(2, 3)
print(res)
不用像其他语言指定返回值的类型
Python中函数的参数以及返回值都是引用类型;可以通过id()查看变量保存的地址;这里的传参应该参考java,和c语言不同
def swap(num1, num2):
print(id(num1)) # 140725073575008
temp = num1
num1 = num2
num2 = temp
print(id(num1)) # 140725073575040
return (num1, num2) # 当返回类型是元组的时候,小括号可以省略
num1 = 2
num2 = 3
print("%d - %d" % (num1, num2)) # 2 - 3
print(id(num1)) # 140725073575008
(num1, num2) = swap(num1, num2)
print(id(num1)) # 140725073575040
print("%d - %d" % (num1, num2)) # 3 - 2
定义在函数外部的变量称为全局变量,函数内部不允许对全局变量进行修改;
如果在函数内部想要修改全局变量,只会在函数内部创建一个同名的局部变量
想要修改全局变量,需要在赋值语句前面使用global关键字声明变量

定义在函数外部的变量称为全局变量,函数内部不允许对全局变量进行修改;
如果在函数内部想要修改全局变量,只会在函数内部创建一个同名的局部变量
想要修改全局变量,需要在赋值语句前面使用global关键字声明变量
缺省参数:
缺省参数必须在函数参数列表的末尾
当含有多个缺省参数的时候,需要添加参数名
def print_info(name, gender_text="男生"):
"""
:param name: 姓名
:param gender_text: 性别,默认男生
:return:
"""
print(name, gender_text)
print_info("小红") # 小红 男生
print_info("小红", "女生") # 小红 女生
多值参数:当出入的参数个数不确定
变量前面添加 * 表示元组;添加 ** 表示字典;
一般使用 *args 作为列表命名, ** kwargs表示字典
def demo(*args, **kwargs):
print(args)
print(kwargs)
gl_nums = {1, 2, 3}
gl_dict = {"name": "小明", "age": 18}
# 拆包语法,在想要传递的相应的参数前面添加* 或 **
# 拆包可以简化元组和字典变量的传递
demo(*gl_nums, **gl_dict)
5.2 内置函数
| range(start, end) | 遍历区间,默认步长step = 1 |
| range(end) | step = 1, start = 0 |
| min(), max(), sum() | 取最小,最大, 总和 |
| eval() | 计算字符串表达式,如 eval('1 + 2') |
| print() | print(value, sep = "", end = ''); sep表示间隔符,end为结尾,默认是换行 |
| sorted(iterable, key, reverse) | 排序; iterable为迭代对象,key为排序规则 reverse是否降序 |
| enumerate() | 返回可迭代的enumerate对象,需使用list()查看 |
| map(function, iterable) | 将function函数依次映射到序列或迭代器对象 |
| filter(function, iterable) | 将function函数(必须是单个参数)依次映射到序列或迭代器对象 |
| open(file, mode = 'r', encoding = 'utf-8') | 打开磁盘文件 |
print(value, sep = “”, end = ‘’);
sep表示间隔符,end为结尾,默认是换行
排序; iterable为迭代对象,key为排序规则
reverse是否降序
?5.3 Lambda表达式
匿名函数,减少代码量;使用该语法糖返回的是一个匿名函数,可以在需要小函数的地方定义lambda
语法:lambda argument_list: expression # argument_list为参数,expression为表达式
f = lambda x, y : x + y
f = ('我学', 'Python') # 变量赋值,间接调用lambda, 结果:我学Python
# 作为参数
x = filter(lambda x : x % 3 == 0, [1, 2, 3, 4, 5, 6])
# [3, 6]
?5.4 装饰器
?基本使用
代码运行期间动态增加功能的方式,称之为“装饰器”,理解成非业务功能切面添加到代码中
目前包含一个函数:
def add(x, y):
return x + y
装饰器的含义我理解的就是:将目标函数作为参数传递给一个自定义的装饰函数(decorator), 这个函数可以接收任意的参数
装饰函数:
日志函数
def log(func):
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
在目标函数上面添加:@log,为函数进行增强
@log() # 相当与调用log(add)
def add(x, y):
return x + y
此时正常调用add函数的时候,会自动调用log函数,即:log(add)
带有参数的装饰器
@log("test") # 相当与调用log("test")(add)
def add(x, y):
return x + y
定义装饰函数:
def log(text):
def decorator(func):
def wrapper(*args, **kw):
print('call %s-%s():' % (text, func.__name__))
return func(*args, **kw)
return wrapper
return decorator
调用链路:log(“test”) -> 返回decorator(func) -> wrapper
当使用__name__获取信息的时候,最终拿到的是wrapper类型;
由于某些情况我们需要原始的__name__信息,因此可以使用 @functools.wraps(func) # 将装饰函数名字修改为原函数
当使用__name__获取信息的时候,最终拿到的是wrapper类型;
由于某些情况我们需要原始的__name__信息,因此可以使用 @functools.wraps(func) # 将装饰函数名字修改为原函数
修改后的装饰函数:
import functools
def log(text):
def decorator(func):
@functools.wraps(func) # 将装饰函数名字修改为原函数
def wrapper(*args, **kw):
print('call %s-%s():' % (text, func.__name__))
return func(*args, **kw)
return wrapper
return decorator
6.模块
模块就好比是工具包,Python中以.py结尾的源代码文件都可以是一个模块,通过import进行导入;模块中的全局变量,函数可供外界访问
模块名也是一种标识符,所以只能由字母,下划线和数字组成,数字作为开头
导入的模块首先由Python解释器进行一次编译
局部导入:from 模块名 import 工具名
导入的时候,导入文件中没有缩进的代码会被自动执行
为了避免导入的文件中不执行没有缩进的测试代码,可以使用__name__判断,如果是当前文件执行,name__默认是__main;否则,就是模块名
if __name__ == __main__:
# 执行测试代码,可以将测试代码写到一个main()函数中
main()为了避免导入的文件中不执行没有缩进的测试代码,可以使用__name__判断,如果是当前文件执行,name__默认是__main;否则,就是模块名
if __name__ == __main__:
# 执行测试代码,可以将测试代码写到一个main()函数中
main()
7.高级变量类型
?7.1 序列结构
指一块可存放多个值的连续内存空间,按一定顺序排列,可通过索引进行访问;其中字典和集合是无序的,不能索引访问。元组,字符串是不可变序列
静态变量为传值拷贝,动态变量(列表,字典,集合)为引用拷贝
1.列表
- 基础语法
其他语言中的数组,使用 [] 定义;可以存储不同类型的变量del 关键字将变量从内存中删除,后续的代码不能继续使用这个变量
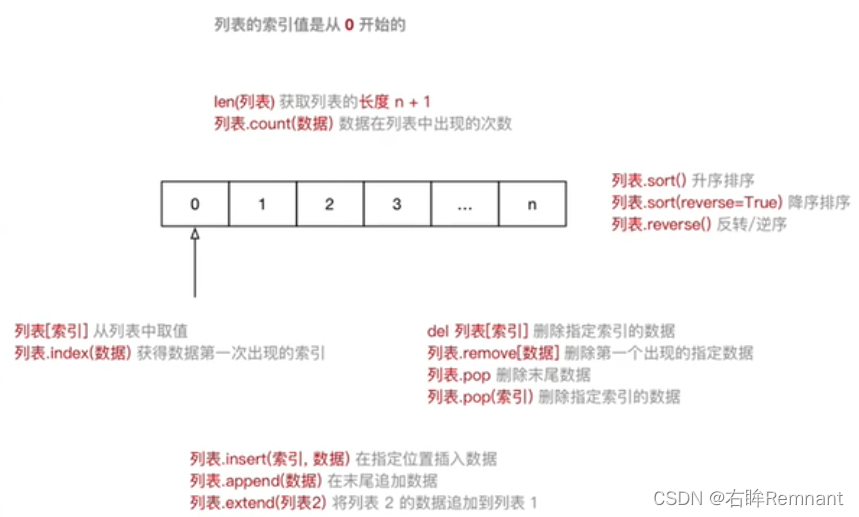 > 列表的比较需要引入 operator 中的eq 方法
> 列表的比较需要引入 operator 中的eq 方法
2.元组(Tuple)
- 基础语法
与列表相似,不同的在于元组中的元素值不能被修改, 使用()定义
TypeError: ‘tuple’ object does not support item assignment
# 测试元组
tuple_array = () # 定义一个空元组
print(tuple_array)
print(type(tuple_array))
tuple_array1 = (1, "asdfasdf", True)
print(tuple_array1)
print(type(tuple_array1))
tuple_array2 = (5) # 只有一个元素的元组
print(tuple_array2)
print(type(tuple_array2)) # <class 'int'>
tuple_array3 = (5, ) # 定义只有一个元素的元组的时候,需要用逗号分隔
print(tuple_array3)
print(type(tuple_array3)) # <class 'tuple'>
 > 可以使用list()和tuple()进行列表和元组之间的相互转换
> 可以使用list()和tuple()进行列表和元组之间的相互转换
元组是不可修改的,但是可以进行拼接:
tup1 = (12, 34.56)
tup2 = ('abc', 'xyz')
# 以下修改元组元素操作是非法的。
# tup1[0] = 100
# 创建一个新的元组
tup3 = tup1 + tup2
print (tup3)元组是不可修改的,但是可以进行拼接:
tup1 = (12, 34.56)
tup2 = ('abc', 'xyz')
# 以下修改元组元素操作是非法的。
# tup1[0] = 100
# 创建一个新的元组
tup3 = tup1 + tup2
print (tup3)
3.字典
- 基础语法:
类似map集合,使用键值对存储,内部无序;键 只能使用数字,字符串或者元组;键值对之间使用:分隔; 键必须唯一; 类型:<class: dict>
使用{} 定义,一般存储物体的信息
可以通过key访问字典中的元素:
tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
print ("tinydict['Name']: ", tinydict['Name'])
删除字典中的元素
删除字典中的元素
tinydict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
del tinydict['Name'] # 删除键 'Name'
字典的key是不可变的,因此不能使用列表充当,可以使用数字或者元组
7.2?推导式
4.1 列表推导式? [val for val in list_item if condition]
a = [x * x for x in range(6)]
# 等价于
a = []
for x in range(6):
a.append(x * x)
4.2 字典推导式??{key:value for key_, val_ in dict.items() if condition}
4.3 集合推导式??{key for key_ in dict.items() if condition}
4.4 元组推导式? (val for val in list_item if confition)
- Python生成器(元组推导式):与列表推导式类似,但是生成器返回的是迭代器对象,具有惰性机制,里面的元素只有在访问的时候才会生成,一旦访问立即释放内存。
语法:(表达式 for 变量 in 序列或迭代对象) 或
(表达式 for 变量 in 序列或迭代对象 if 条件表达式)
# 列表生成器
L = [(i + 1) ** 2 for i in range(6)]
# L = [1, 4, 9, 16, 25, 36], 运行结束就占用内存
# 生成器
G = ((i + 1) ** 2 for i in range(6))
# G , 只有在访问的时候才会占用内存
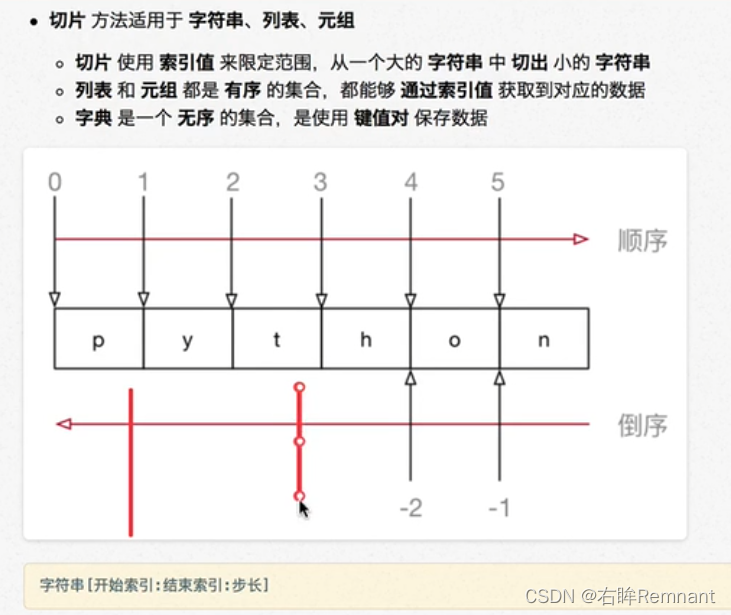
7.3 序列切片
切片是序列元素的另一种方法,可以访问一定范围内的元素,生成新的序列
语法:序列名称[开始 : 结束 : 步长]
公共方法
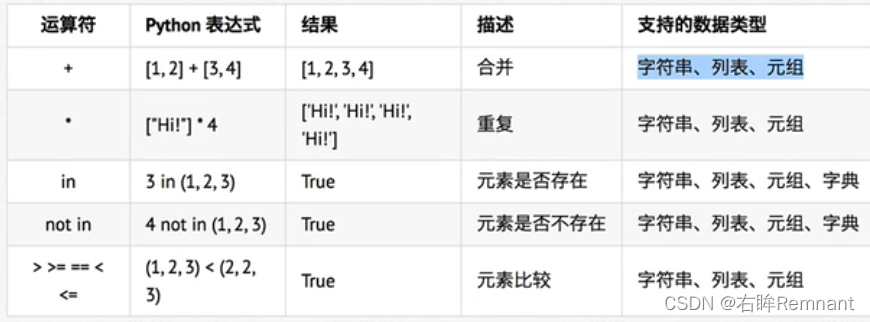
# 使用加号拼接列表,会生成一个新的列表
print([1, 2] + [3, 4])
list1 = [1, 2]
list2 = [3, 4]
list1.extend(list2) # 将列表追加到原来的列表中,不生成新列表
print(list1) # [1, 2, 3, 4]
list1.append(list2) # 将 list2整体看做一个元素添加
print(list1) # [1, 2, 3, 4, [3, 4]]
4.完整for循环
for … in :
for循环中执行的代码
else
for循环中没有经过break退出,完成执行完for循环后会执行这段代码
for循环中执行的代码
else
for循环中没有经过break退出,完成执行完for循环后会执行这段代码
四、Python面向对象
1.可变类型和不可变类型
可变类型:数字型,字符串和元组
不可变类型:列表,字典; 通过相应的方法可以操作列表或字典中的数值;使用赋值改变地址
字典的key只能使用不可变类型作为类型
2.创建类
class FirstClass:
# 类中方法第一个参数必须是self, self就是方法调用对象的引用
def firstmethond(self, name):
print("我是 %s 方法" % name)
def secondmethond(self, name):
print("我是 %s 方法" % name)
# 创建一个类的实例
first = FirstClass()
first.firstmethond("first")
self 就类似 this 指针
Python中可以在类外通过 .属性名的方法添加属性,但是这种方法不推荐
如:first.name = “Tom”
Python中可以在类外通过 .属性名的方法添加属性,但是这种方法不推荐
如:first.name = “Tom”
初始化方法
类中的 __init__方法是Python中的内置方法,用于完成对象的创建和在类中定义属性
class FirstClass:
# 初始化方法,完成对象的对象和属性的赋值
def __init__(self):
print("这是一个初始化方法")
self.name = "Tom"
def first(self, name):
print("%s 的名字是 %s" % (self.name, name))
firstObj = FirstClass()
firstObj.first("first")
就是构造方法,同样可以 有参构造,传入参数就行
del: 也是内置函数,类似C++中的析构函数,java中由JVM自动完成对象的回收
str: 类似java中的toString()方法,自定义对象输出内容,必须返回一个字符串
身份运算符
is / is not, 用于判断是否是对同一个对象的引用
Python中 身份运算符 比较的是两个对象的地址; == 比较的是两个对象的值是否相等;Python中针对 None 进行比较时建议使用 身份运算符
私有属性和私有方法
在属性名或方法前面添加 两个下划线,就是私有的
3. 继承
继承的语法:
class 类名(父类名):
pass
pass
Python中支持多继承,当父类具有同名方法的时候,采用MRO搜索规则
MRO:可以使用内置函数 __mro__查看函数搜索顺序。
搜索的时候,首先在当前类中查找,如果有则停止,否则依次找下一个类,直到最后没有找到。
类也可以被看做一个对象,程序运行中被加载一次
类属性:定义在类中__init__以及其他方法外部,通过赋值语句定义类属性。与实例对象没有关系,表示一种全局概念
类方法:在方法定义上面添加修饰器@classmethod, 方法第一个参数必须是cls,作用与self类似
静态方法:当一个方法既不访问成员属性,成员方法,也不访问类属性和类方法,那么可以在方法上面添加 @staticmethod表示静态方法; 通过类名.的方式调用方法
4.单例
__new__方法:内置的静态方法,在使用类名()创建对象的时候,调用该方法分配空间,并返回对象的引用作为初始化方法__init__的第一个参数self
重写__new__方法,重写规则:return super().new(cls)
注意,这里需要手动传递cls
单例实现:
class Singleton(object):
instance = None # 记录单例对象的引用
init_flag = False
def __new__(cls, *args, **kwargs):
# 判断类属性是否为空对象
if cls.instance is None:
# 调用父类方法分配空间,返回对象引用
cls.instance = super().__new__(cls)
return cls.instance
# 用来判断执行一次初始化方法
def __init__(self):
if not self.init_flag:
print("初始化方法被调用")
self.init_flag = True
sing1 = Singleton()
print(id(sing1)) # 1826555375304
sing2 = Singleton()
print(id(sing2)) # 1826555375304
print(id(Singleton.instance))
5.异常
try:
# 程序尝试执行的代码
num = int(input("请输入一个整数:"))
print(8 / num)
except ZeroDivisionError:
# 发生异常的代码
print("输入不能是0")
except ValueError:
# 其他错误类型捕获
print("输入应该是个整数")
except Exception as result:
# 处理其他未知错误
print("位置错误 %s" % result)
else:
# 只有当没有发生错误的时候执行
print("num的值:%d" % num)
finally:
# 无论是否发生异常,都会执行
print("程序运行结束")
finally的作用:保证即使有return语句,也会执行这部分代码
def fun():
try:
# 程序尝试执行的代码
num = int(input("请输入一个整数:"))
print(8 / num)
except ZeroDivisionError:
# 发生异常的代码
print("输入不能是0")
except ValueError:
# 其他错误类型捕获
print("输入应该是个整数")
except Exception as result:
# 处理其他未知错误
print("位置错误 %s" % result)
else:
# 只有当没有发生错误的时候执行
print("num的值:%d" % num)
return
finally:
# 无论是否发生异常,都会执行
print("程序运行结束")
print("try...except外部")
fun()
6.文件
文件写入的访问方式:

file = open("test.txt")
# text = file.read()
# print(text)
while True:
text = file.readline()
if not text:
break;
print(text, end="")
file.close()
read()方法读取全部内容,readline()读取一行内容
小文件复制:
file_read = open("test.txt")
file_write = open("text1.txt", "r")
text = file_read.read()
file_write.write(text)
file_read.close()
file_write.close()
Python3中默认编码 UTF-8, Python2中编码ASCII
五、其他补充
5.1 With语句
5.1.1 with和上下文管理器
with 语句用于包装带有使用上下文管理器 定义的方法的代码块的执行。with语句允许在一个代码块周围执行初始化和终结化代码。
with语句的上下文管理器
上下文管理器处理进入和退出所需运行时上下文以执行代码块。
with 语句的执行过程如下:
- 对上下文表达式 (在 with_item 中给出的表达式) 求值以获得一个上下文管理器。
- 载入上下文管理器的 __exit__() 以便后续使用。
- 发起调用上下文管理器的 __enter__() 方法。
- 如果 with 语句中包含一个目标,来自 __enter__() 的返回值将被赋值给它。 with语句会保证如果 __enter__() 方法返回时未发生错误,则 __exit__() 将总是被调用。 因此,如果在对目标列表赋值期间发生错误,则会将其视为在语句体内部发生的错误。 参见下面的第 6 步。
- 执行语句体。
- 发起调用上下文管理器的 __exit__() 方法。 如果语句体的退出是由异常导致的,则其类型、值和回溯信息将被作为参数传递给 __exit__()。 否则的话,将提供三个 None 参数。 如果语句体的退出是由异常导致的,并且来自 __exit__() 方法的返回值为假,则该异常会被重新引发。 如果返回值为真,则该异常会被抑制,并会继续执行 with 语句之后的语句。 如果语句体由于异常以外的任何原因退出,则来自 __exit__() 的返回值会被忽略,并会在该类退出正常的发生位置继续执行。
对上下文表达式 (在 with_item 中给出的表达式) 求值以获得一个上下文管理器。
载入上下文管理器的 exit() 以便后续使用。
发起调用上下文管理器的 enter() 方法。
如果 with 语句中包含一个目标,来自 enter() 的返回值将被赋值给它。
with语句会保证如果 enter() 方法返回时未发生错误,则 exit() 将总是被调用。 因此,如果在对目标列表赋值期间发生错误,则会将其视为在语句体内部发生的错误。 参见下面的第 6 步。
执行语句体。
执行语句体。
发起调用上下文管理器的 exit() 方法。 如果语句体的退出是由异常导致的,则其类型、值和回溯信息将被作为参数传递给 exit()。 否则的话,将提供三个 None 参数。
如果语句体的退出是由异常导致的,并且来自 exit() 方法的返回值为假,则该异常会被重新引发。 如果返回值为真,则该异常会被抑制,并会继续执行 with 语句之后的语句。
如果语句体由于异常以外的任何原因退出,则来自 exit() 的返回值会被忽略,并会在该类退出正常的发生位置继续执行。
自定义上下文管理器
class MyContextManager:
def print(self):
print(self.__class__)
def __enter__(self):
print("enter")
return MyContextManager()
def __exit__(self, exc_type=None, exc_val=None, exc_tb=None):
print("资源正在销毁")
from MyContextManager import MyContextManager
if __name__ == '__main__':
with MyContextManager() as mc: # 返回的对象实例为__enter__的返回值
mc.print()

__exit__的参数
在with中手动抛出异常
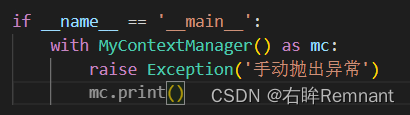

如果在执行 with 语句的语句体期间发生了异常,则参数会包含异常的类型、值以及回溯信息。 在其他情况下三个参数均为 None。
?5.1.2?contextlib?
class contextlib.AbstractAsyncContextManager 一个为实现了 object.aenter() 与 object.aexit() 的类提供的 abstract base class。 为 object.aenter() 提供的一个默认实现是返回 self 而 object.aexit() 是一个默认返回 None 的抽象方法。
在方法上使用装饰器:
@contextlib.contextmanager
这个装饰器是一个生成器函数,可以修饰在一个返回对象的工厂函数上面,不需要在手动创建__exit__和__enter__
@contextmanager
def managed_resource(*args, **kwds):
# Code to acquire resource, e.g.:
resource = acquire_resource(*args, **kwds)
try:
yield resource # 生成器返回一个对象
finally:
# Code to release resource, e.g.:
release_resource(resource)
当生成器发生 yield 时,嵌套在 with 语句中的语句体会被执行。 语句体执行完毕离开之后,该生成器将被恢复执行。 如果在该语句体中发生了未处理的异常,则该异常会在生成器发生 yield 时重新被引发。 因此,在装饰的函数内可以使用 try…except…finally 语句来捕获该异常(如果有的话),确保进行了一些异常处理。
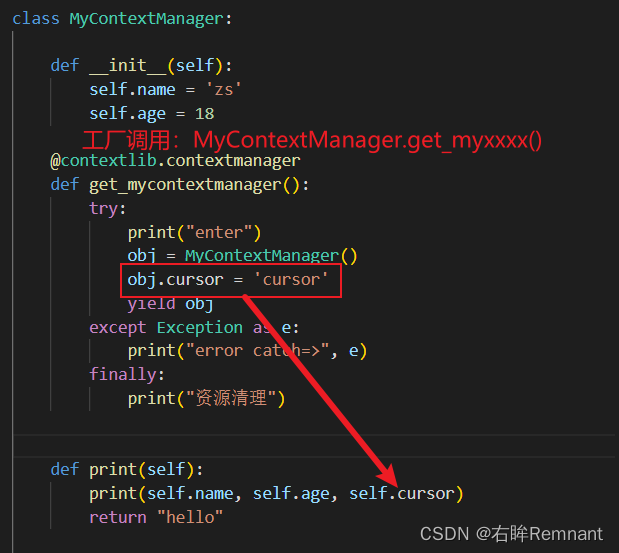
可以在创建对象的时候添加一些实例属性
总结
简单了解Python, 整理并不细致,一些概念还是比较模糊



















 33万+
33万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











