



 本文介绍了Hadoop的基本概念,包括其作为Apache开源项目的目标和组成部分(HDFS和MapReduce),以及核心组件如YARN、HBase、Hive和Spark。还提供了Linux环境下的Hadoop安装和配置实例,展示了如何搭建和部署Hadoop集群进行大数据处理。
本文介绍了Hadoop的基本概念,包括其作为Apache开源项目的目标和组成部分(HDFS和MapReduce),以及核心组件如YARN、HBase、Hive和Spark。还提供了Linux环境下的Hadoop安装和配置实例,展示了如何搭建和部署Hadoop集群进行大数据处理。
Hadoop是一个开源的分布式计算框架,用于处理大规模数据集。本文将介绍Hadoop的基本概念、架构和核心组件,帮助你了解如何使用Hadoop进行大数据处理。
一.hadoop的介绍
1.Hadoop简介
Hadoop是Apache基金会下的一个开源项目,旨在解决大规模数据集的存储和处理问题。它提供了一个可靠的、可扩展的分布式计算环境,适用于各种类型的数据处理任务。
2.Hadoop架构
Hadoop采用分布式架构,包括两个核心组件:Hadoop分布式文件系统(HDFS)和Hadoop分布式计算框架(MapReduce)。HDFS用于存储和管理数据,MapReduce用于并行计算和处理数据。
3.Hadoop核心组件
除了HDFS和MapReduce,Hadoop还包括其他重要组件,如YARN(资源调度和管理)、HBase(分布式数据库)、Hive(数据仓库)、Spark(内存计算框架)等。了解这些组件的功能和用法,能够更好地利用Hadoop进行大数据处理。
4.Hadoop生态系统
Hadoop拥有丰富的生态系统,包括各种工具和框架,用于数据采集、数据清洗、数据分析等。例如,Flume用于实时数据采集,Sqoop用于关系型数据库和Hadoop之间的数据传输,Pig用于数据处理和分析,等等。熟悉这些工具和框架,能够提高大数据处理的效率和灵活性。
二.实例演示
通过一个简单的示例,使用Hadoop集群搭建与部署:
1.在linux操作系统中,下载并安装jdk1.8
2.解压jdk1.8
核心代码

解压结果

2.配置环境变量
核心代码

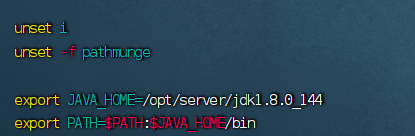
重启环境并查看jdk版本


3.下载并安装hadoop

解压

4.配置环境


5.重启环境并查看hadoop版本

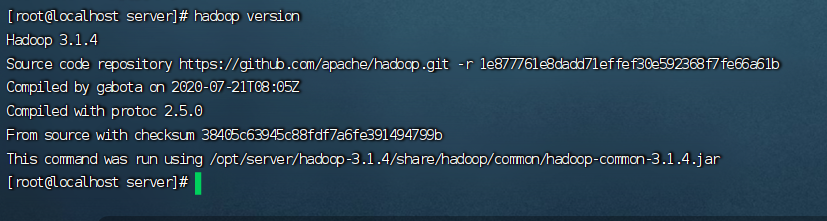
6.修改hadoop各配置文件
(1)
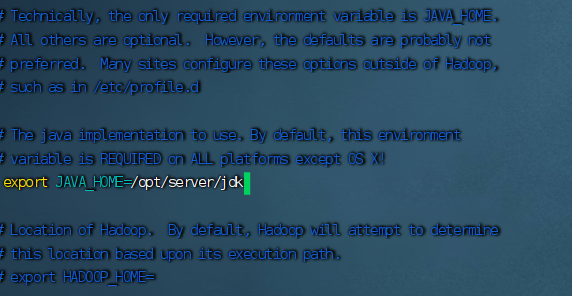
(2)
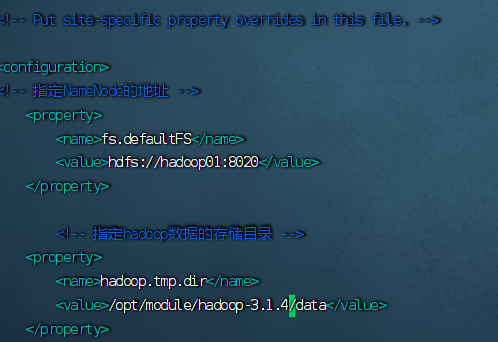
(3)
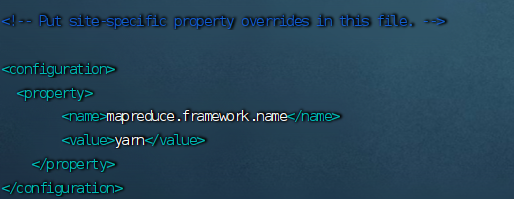
(4)
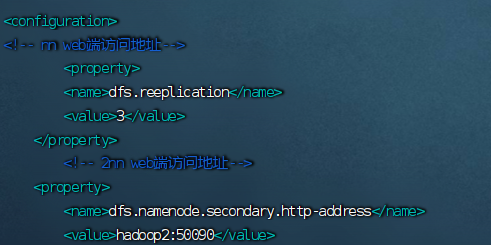
(5)
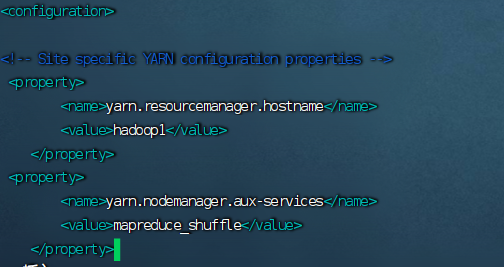
7.配置workers文件

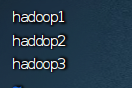
8.拷贝hadoop所有文件到其他节点

















 608
608



 到【灌水乐园】发言
到【灌水乐园】发言








