



现场可编程门阵列高速低功耗可编程互连设计
摘要
本文提出了一种快速互连方案及针对现场可编程门阵列可编程互连的优化电路,以实现优异的性能和静态功耗降低。所提出的快速互连方案包括逻辑块之间的快速连接以及导线段的优化,旨在降低路径延迟并提高连接性。此外,在路由电路中应用非最小沟道长度技术,可有效减少静态功耗。实验结果表明,优化后的互连方案平均可实现33.1%的速度提升。通过非最小沟道长度技术的优化,互连电路最多可降低37.4%的静态功耗,同时保持速度不下降。
引言
随着工艺的不断缩小,晶体管的特征尺寸持续缩小。当晶体管尺寸缩小时,以晶体管漏电流为主的静态功耗明显增加[1]。此外,尽管每逻辑距离的RC延迟随工艺变化较慢,但每物理距离的RC延迟随着工艺缩小而增加[2]。根据先前的研究[3],现场可编程门阵列中的可编程互连资源占芯片面积的50%~90%,延迟的70%~80%以及功耗的60%~85%。因此,路由架构将对芯片的性能和功耗产生显著影响。这些表明,在现场可编程门阵列中设计高速且低功耗的可编程互连具有巨大潜力。
一种最近邻互连架构被用于研究拓扑结构、数量和距离,并最终在适度增加面积的代价下实现了延迟的降低[4]。多阈值电压技术通常应用于现场可编程门阵列的路由电路以提高速度,但会带来更高的静态功耗[5]。本文中,我们专注于快速互连方案以提高速度,并采用非最小沟道长度技术来降低静态功耗。
本文其余部分组织如下:第2节描述快速互连方案。第3节描述基于非最小沟道长度技术的低功耗设计。第4节展示实验结果。第5节总结全文。
2. 快速互连方案
商业现场可编程门阵列架构中提供了相邻逻辑块之间的快速连接,从而降低了由路由矩阵引起的延迟。现场可编程门阵列路由矩阵中相邻瓦片之间的互连模式包括4种基本形状:直线形、L形、T形和十字形,如图1所示。图1显示了一个4×6数组的瓦片。从图1可以看出,从源瓦片F1到相邻的目标瓦片E2的信号经过了L形的路由矩阵。这些模式在不同设计中的使用比例各不相同。如果能在使用最频繁的模式中引入逻辑块之间的快速互连,则可以有效降低由互连开关引起的延迟。

图1 互连模式
本文中,我们基于多种互连模式的可能性,探索了以较小面积开销实现性能提升的快速互连方案。我们使用VPR工具对上述互连模式进行了分析。在VPR7.0中采用了基于现代现场可编程门阵列架构的旗舰架构文件,该架构包括逻辑块、长度为4的导线、块存储器和乘法器。考虑到不同的布线段可能影响互连模式的比例,我们还研究了长度1和6的导线段。我们选取了20个MCNC基准电路,采用时序驱动的布局布线算法进行映射和布线。最后,从布线结果文件中提取布线信息,并分析了不同模式的分布情况,如图2所示。由图2可见,直线形互连模式仍占主导地位,L形互连模式平均占比达38%,而T形和十字形所占比例较小,但由于负载原因,会带来更多的延迟和功耗开销。因此,我们引入了在直线和L形方向上,相邻逻辑块之间的快速连接可减少路由开关数量,并改善信号延迟和连接性,如图3所示。
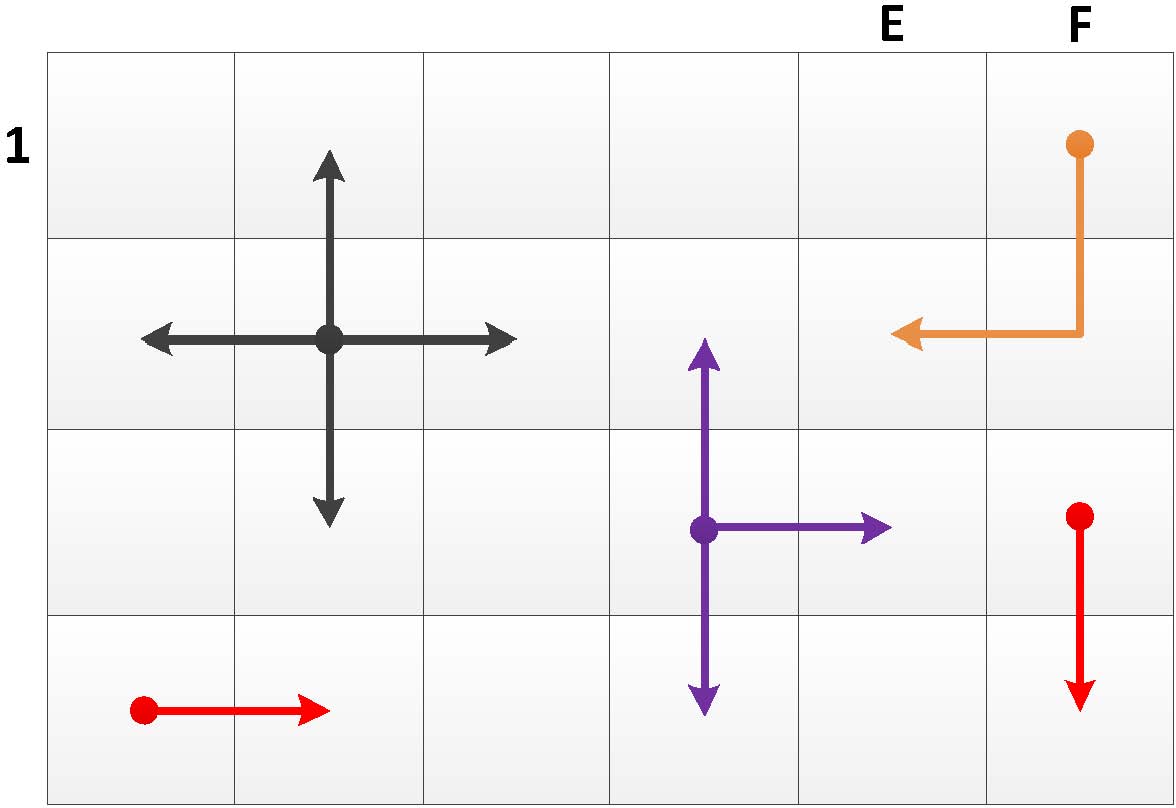

图2 互连模式的分布
图3 相邻LB之间的快速互连
我们还引入了主要用于优化导线段的互连模式。例如,如果长度为6的导线能够访问图4(a)中起始瓦片和结束瓦片之间的瓦片,则连接性将显著提高。这相当于六个水平形状互连模式。然而,由于线路负载较大,这种架构会带来更多的延迟、功耗和面积开销。因此,我们还可以在导线段中引入直线型和L形互连模式,如图4(b)所示。图4(b)显示了一条长度为6的延伸导线连接到END_S瓦片以增强连接性,并且与图4(a)相比仅保留中间连接,从而因减少了导线段上的负载而实现更高速度。实际上,基于现场可编程门阵列的设计包含各种类型的导线段,如长度为2的导线和长度6的导线。因此,在图4中,从瓦片0到瓦片1和瓦片2的信号可以经由长度为2的导线进行布线。类似地,在长度为2的导线中也添加了一条延伸导线。
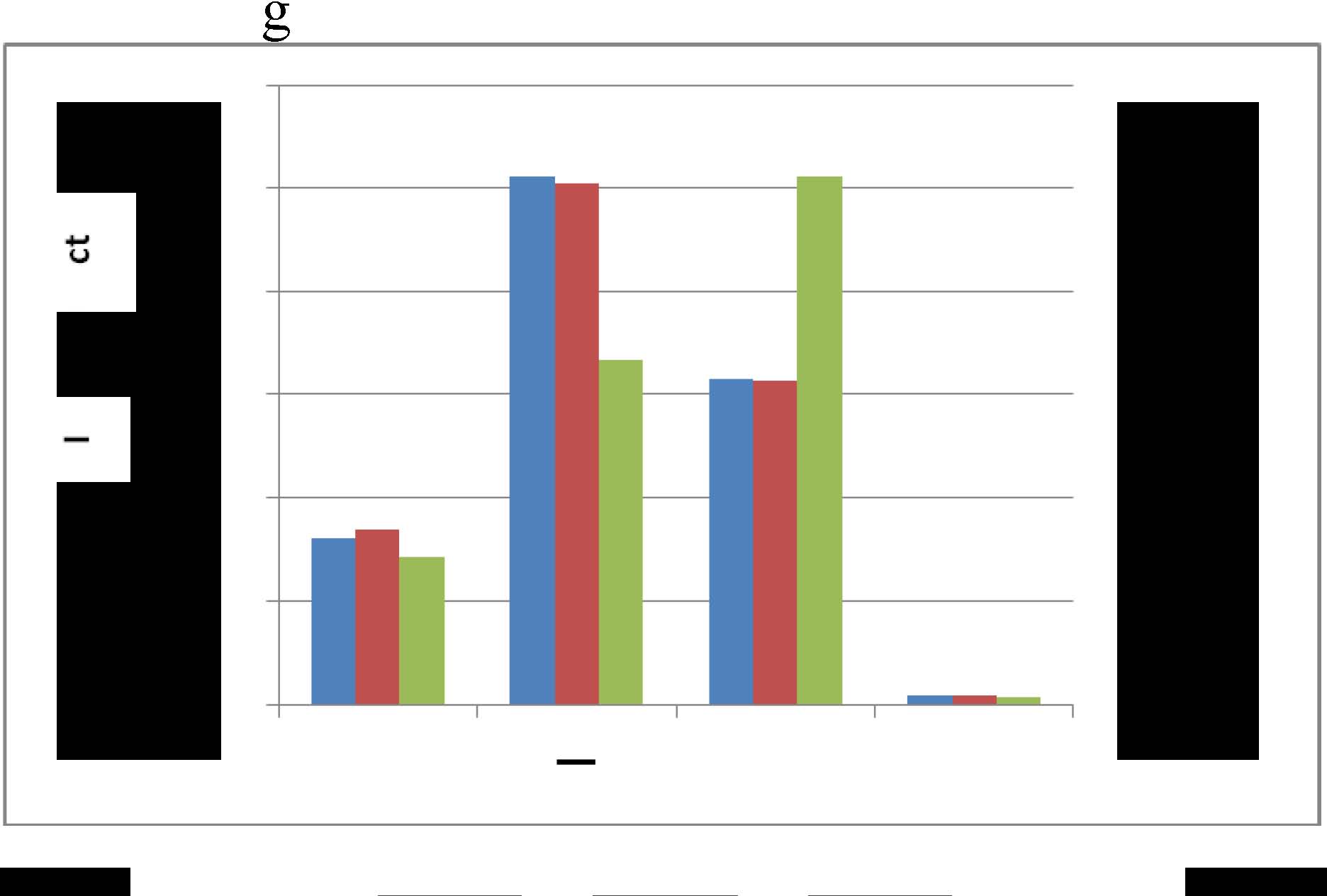
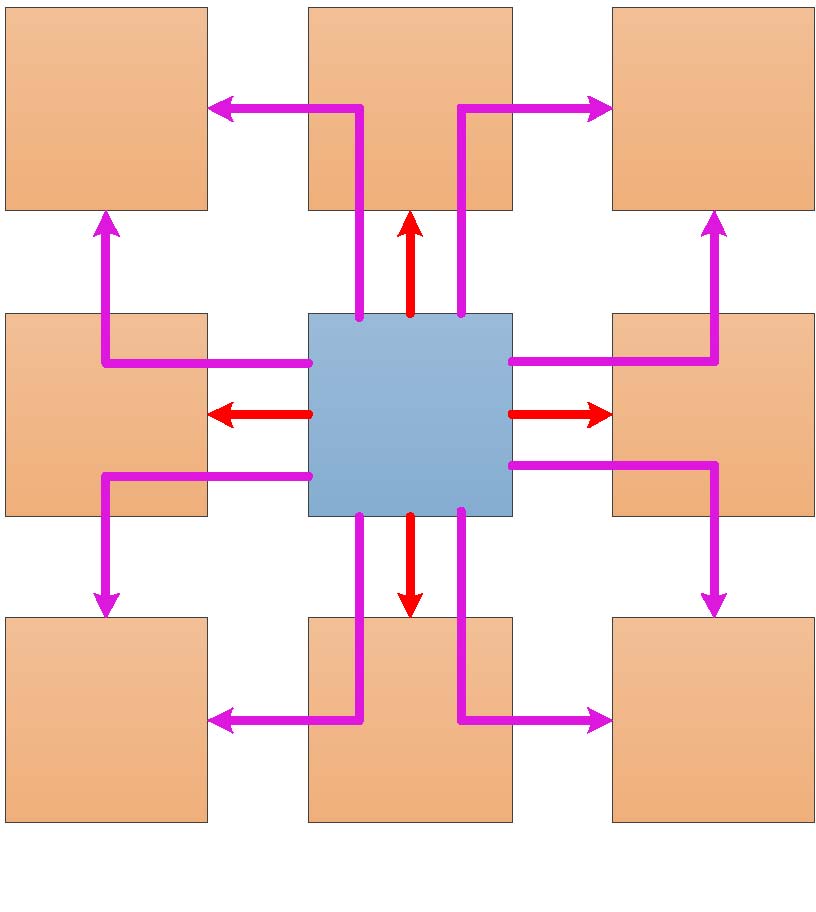
图4 导线段优化
图5 显示了从源瓦片访问的汇点瓦片跳互连。优化前的长度2和长度6的导线用于图5(a),而图5(b)中使用了逻辑块之间的快速互连和优化后的导线段。从图5可以看出,快速互连方案可访问36个汇瓦片,而优化前的方案仅能访问24个汇点瓦片。这意味着快速互连方案在付出较小面积代价的情况下,可实现48%的连接性增益。
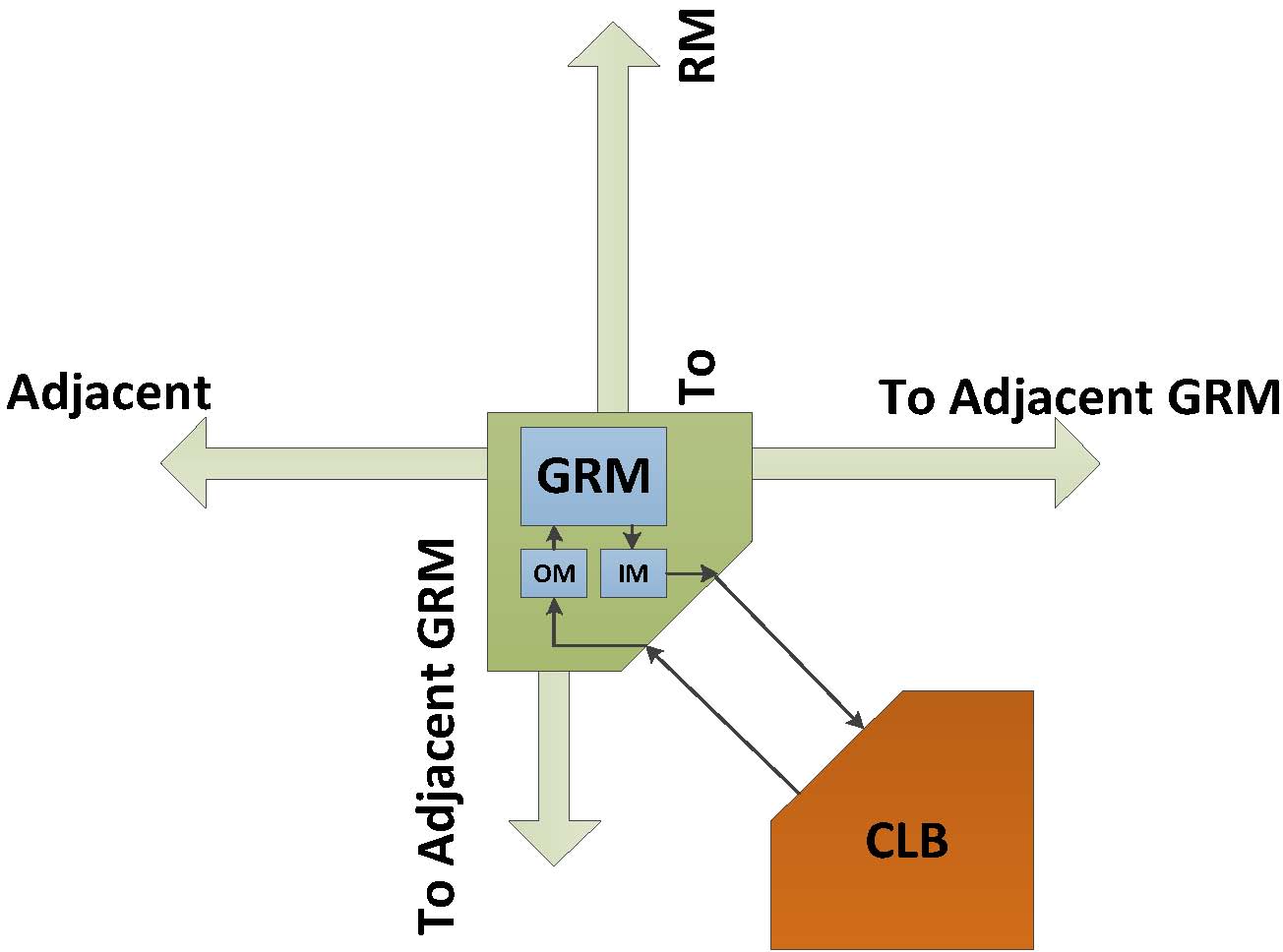
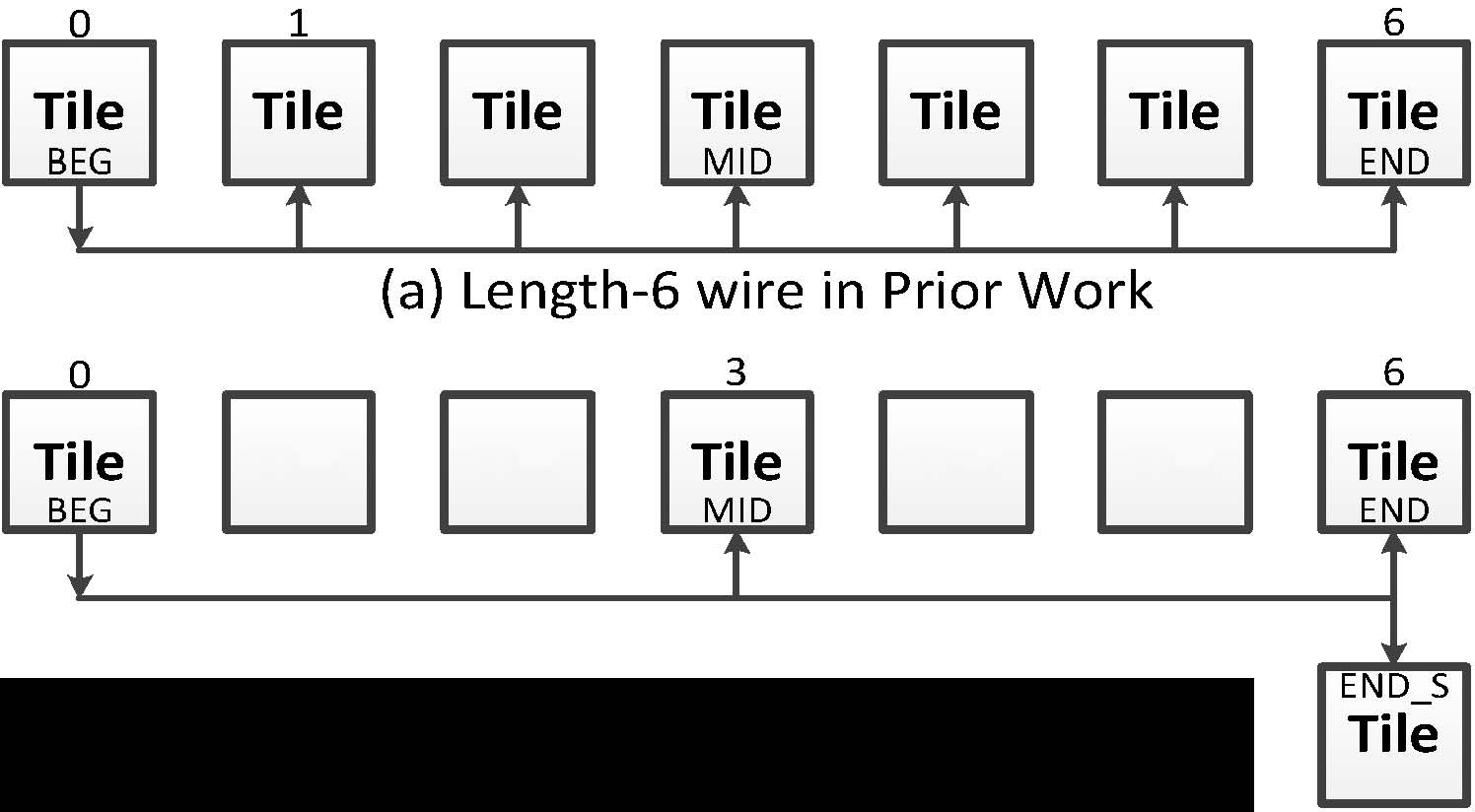
图5 快速互连方案
3. 低功耗设计
一种常见的FPGA路由架构如图6所示。可配置逻辑块通过通用路由矩阵(GRM)、输入多路复用器(IM)和输出多路复用器(OM)连接到全局路由资源。这些全局路由资源基于多路复用器和缓冲器。因此,我们研究了这些路由电路的低功耗技术。

图6 FPGA路由架构
在超深亚微米CMOS工艺中,随着沟道长度的减小,源极和漏极的晕圈区会相互重叠,导致沟道掺杂浓度增加,从而提高阈值电压。这种现象称为反向短沟道效应(RSCE)。然而,当沟道长度继续缩小,漏感应势垒降低(DIBL)效应逐渐占主导地位,使阈值电压下降。因此,阈值电压呈现出先上升后下降的趋势,在某一沟道长度处达到最大值。因此,我们可以采用非最小沟道长度技术来有效降低静态功耗。图7展示了我们优化的基于[5]的电路,该电路是多阈值电压与非最小沟道长度技术的协同优化。MN2和MN3分别被替换为低电压晶体管(LVT),以优化速度。由于MP1、MP2和MP3并非关键路径,可用高电压晶体管(HVT)替代,以降低静态功耗。在图7中,缓冲器最后一级的NMOS晶体管MN4对互连的漏电流影响显著,因此我们选择MN4采用接近最大阈值电压的非最小沟道长度,以减少静态功耗并保持电路速度。
图7 非最小沟道长度互连电路
4. 实验结果
在纳米工艺技术中,互连延迟接近于门延迟。因此,在仿真中应考虑金属线中的寄生参数。为了提高仿真的准确性,我们采用了分布参数模型。本设计基于65纳米,1.2V低漏电技术。我们使用Virtuoso提取工具提取了RC参数,在10微米范围内进行。图8(蓝色部分)显示了一条10微米金属线的导线模型。随后,我们建立了如图8所示的长度为6的导线模型。类似地,长度2的导线模型也以相同方式构建。

图8 六段式导线模型
为了评估快速互连方案的性能增益,我们使用SPECTRE工具分别在典型情况(TT,27°C,1.2V)和最差情况(SS,125°C,1.08V)下对图5(a)所示传统方案和图5(b)所示优化方案中的若干路径延迟进行仿真。这些路径基于上述导线模型。实验结果如表1所示。路径A到E表示从源瓦片出发的路径到图5(a)中所示的单元A到E。路径C中的性能比较表明,逻辑块之间的快速互连实现了36.4%的性能增益。路径A和B的比较表明,优化后的长度为6的导线获得了更好的性能,而长度2可以抵消优化后长度为6的导线带来的连接性损失。路径D和E的比较表明,扩展导线不仅增强了连接性,还提升了性能。
表1 路径延迟仿真
| 路径 | 延迟(纳秒) 典型 | 延迟(纳秒) 最差 | 延迟(纳秒) 典型 | 延迟(纳秒) 最差 |
|---|---|---|---|---|
| 传统方案 | 传统方案 | 优化方案 | 优化方案 | |
| 路径A | 0.252 | 0.387 | 0.223 | 0.336 |
| 路径B | 0.235 | 0.389 | 0.144 | 0.224 |
| 路径C | 0.127 | 0.205 | 0.081 | 0.130 |
| 路径D | 0.258 | 0.410 | 0.157 | 0.241 |
| 路径E | 0.344 | 0.537 | 0.249 | 0.364 |
为了评估我们提出的方案能够节省多少功耗,我们在典型和最差情况下对优化方案中各路径E的静态功耗进行了仿真,如表1所示。结果如表2所示。原始路径未采用非最小沟道长度技术,而优化路径则应用了该技术。结果表明,非最小沟道长度技术最多可降低37.4%的静态功耗。
表2 静态功耗仿真
| 静态功耗 (μW) 典型 | 静态功耗 (μW) 最差 | |
|---|---|---|
| 原始路径E | 54.83 | 47.52 |
| 优化的路径E | 43.04 | 29.70 |
| 改进 | 21.5% | 37.4% |
5. 结论
在65纳米、1.2V低漏电技术下,将快速互连方案与多阈值电压及非最小沟道长度技术的协同优化应用于可编程互连。在面积开销较小的情况下,实现了显著的速度性能提升和功耗降低。

















 51
51

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









