







目录
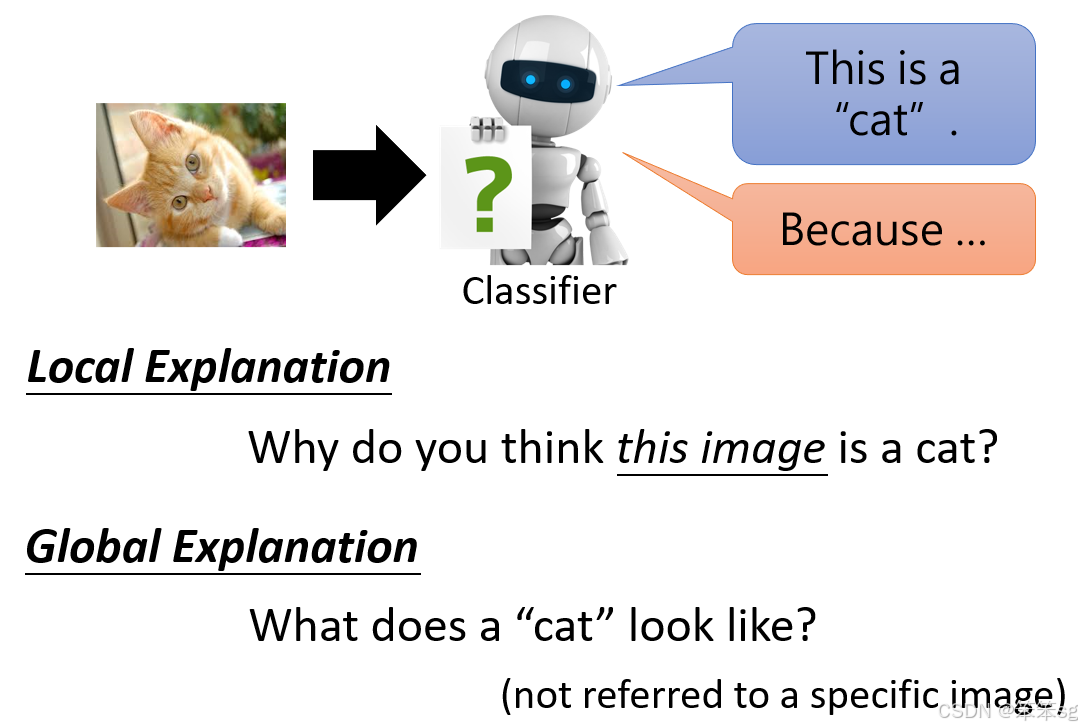
2.2 Interpretable 和 Explainable 的区别
3.1 Explainable Machine Learning 的目标
3.2 Explainable Machine Learning 的分类
4.2 梯度计算(Gradient-Based Method)
5.3 真实场景示例:PASCAL VOC 2007 数据集
0 完整章节内容
本文为李宏毅学习笔记——2024春《GENERATIVE AI》篇——“拓展内容(第6讲)”章节的拓展部分笔记,完整内容参见:
李宏毅学习笔记——2024春《GENERATIVE AI》篇
本章节资源链接:
機器學習模型的可解釋性 (Explainable ML) (上) – 為什麼類神經網路可以正確分辨寶可夢和數碼寶貝呢? - YouTube
機器學習模型的可解釋性 (Explainable ML) (下) –機器心中的貓長什麼樣子? - YouTube
1 为什么我们需要可解释性的ML?
尽管机器学习模型能够给出正确答案,但这并不代表它们一定“聪明”或“理解”问题。例如,神马汉斯这匹马通过观察周围人的反应来推算数学问题的答案,但它并不真正理解数学问题,而是通过“读取”周围人的情感变化来完成任务。这揭示了一个问题:即使机器学习模型提供了结果,我们也可能不知道它是如何得到这个答案的。

在许多真实应用中,可解释性尤为重要。
- 银行贷款决策: 如果银行使用机器学习来判断是否批准贷款,法律要求银行必须提供理由。
- 医疗诊断: 医疗机器学习模型的判断关乎生命,若模型无法解释其判断依据,医生和患者如何信任它的准确性?
- 法律判决: 机器学习可能被用于法律案件的判决,但我们需要确保它的判断公正无私,避免偏见或歧视。
- 自驾车: 自驾车的决策可能直接影响乘客的安全,若自驾车做出急刹车决策,我们需要知道其背后的理由,才能判断是否是合适的决策。

如果机器学习模型能够解释其决策背后的原因,我们可以基于这些解释对模型进行优化。例如,深度学习模型的调优通常依赖调整超参数,如学习率和网络架构,但当前模型的“黑箱”特性使得我们无法明确知道调优的具体依据。若模型能够解释其错误发生的原因,可能会为未来的改进提供更高效的方向。

目前,实现完全可解释的机器学习模型仍面临很大的挑战。尽管我们有一定的技术进步,但要在深度学习领域实现具有高度可解释性的模型并进一步改进其准确性,仍需要克服许多技术难题。
2 Interpretable vs Powerful
2.1 深度学习 vs. 简单模型的争论
有人认为深度学习模型因为是“黑箱”,所以不适合用在需要解释力的场景。是否可以用更简单、易于解释的模型(如线性模型)来取代深度学习呢?

- 线性模型:
- 优点: 线性模型解释性强,训练后可以通过权重直接得知各特征对结果的影响。
- 缺点: 限制性很大,无法处理复杂问题,其表现远不如深度学习模型。
- 深度学习:
- 优点: 深度模型强大且高效,在多种任务中表现优异。
- 缺点: 由于复杂的非线性特性,其内部运行机制难以解释,常被称为“黑箱”。
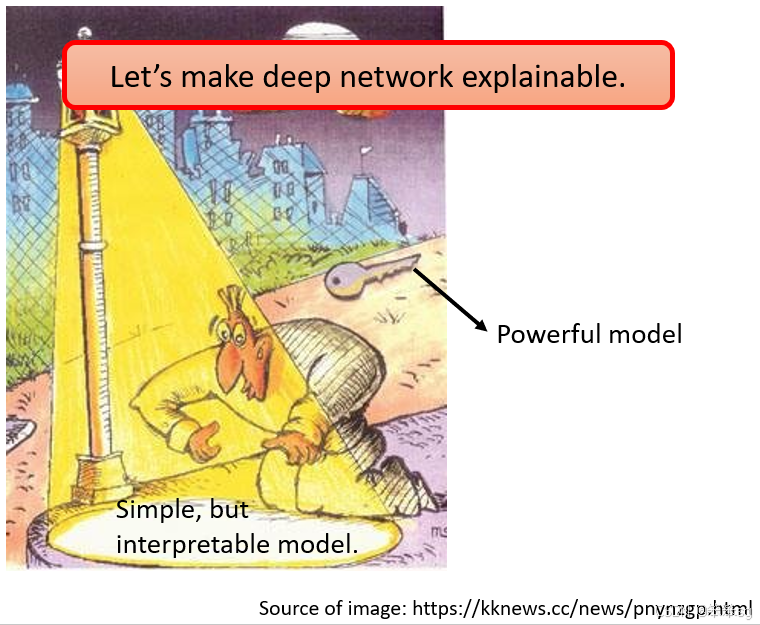
扬弃深度学习模型的建议,就像醉汉在路灯下找钥匙的故事:人们因解释性的方便性而只使用简单模型,但这可能忽视了更强大的解决方案。在此,我们应努力将深度学习的“黑箱”放在“路灯”下,赋予其解释力,而不是简单地放弃。
2.2 Interpretable 和 Explainable 的区别
文献中,Interpretable 和 Explainable 经常被混用,但实际上有所差异:
- Interpretable: 模型本身天然具有解释性,例如线性模型或简单的决策树。
- Explainable: 对于原本是“黑箱”的模型,通过方法让它变得可解释,比如深度学习模型中的可视化技术。
2.3 决策树作为解释性模型的局限
决策树(Decision Tree)在解释性方面占据优势:
- 每个节点对应一个问题,观察节点分裂的规则即可轻松理解模型的判断依据。
- 决策树比线性模型强大,同时具有解释性。
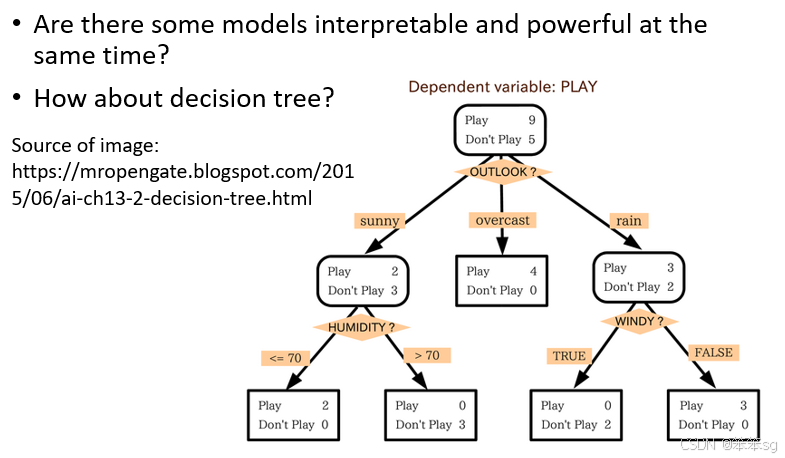
但决策树并非万能解决方案:
- 决策树可能变得过于复杂。例如,有些过于深的决策树结构复杂到无法直观理解。
- 实际应用中,决策树往往被集成为随机森林(Random Forest)。随机森林由许多棵决策树构成,尽管单一决策树是可解释的,但当数百棵树结合后,其整体判断过程仍是“黑箱”。

2.4 深度学习模型的可解释性目标
目前,深度学习模型与简单模型相比,虽然表现更强,但在可解释性上仍然落后。然而,我们的目标不应是退回到简单的线性模型或单一决策树,而是通过新的技术提升深度学习的解释力,使其既强大又透明,从而推动 Explainable Machine Learning 的发展。
结论: 解释性是现代机器学习的关键议题,单靠简单模型无法解决所有问题,复杂模型的透明化是未来研究的方向。这不仅有助于解决实际问题,还能增强对机器学习技术的信任与使用范围。
3 可解释性ML的目标
3.1 Explainable Machine Learning 的目标
Explainable Machine Learning 的目标并不像提升准确率或降低误差率那样明确,它的核心是提供可接受的解释,让人能够信任和接受机器学习模型的决策结果。
目标的误解:
许多人误以为一个好的解释需要完全了解模型的所有细节,但实际上这并非必要。
- 对比人脑:人脑本身也是一个“黑盒子”,我们并不了解其所有运作机制,但依然能接受其他人作出的决策。同样,深度学习模型是否被接受的关键在于是否能给出让人放心的理由,而不是完全解构其内部细节。
心理学实验支持:
心理学家 Ellen Langer 的实验显示,人们更容易接受一个行为,只要有理由支持,哪怕这个理由看似无意义。
- 实验内容:在哈佛大学图书馆排队使用打印机时,有人请求插队:
- 简单请求:“让我先印。” → 60% 同意。
- 加上理由:“让我先印,因为我赶时间。” → 同意率升至 94%。
- 无意义理由:“让我先印,因为我需要先印。” → 同意率仍为 93%。
启示: 人们倾向接受一个行为,只要附加一个理由。因此,Explainable Machine Learning 的目标是提供让人能够信任和接受的理由,而非完全解读模型的内部运行机制。

总结观点:
好的 Explanation 是能够让人接受并感到满意的解释。无论是为了客户、老板,还是自己,只要模型能够提供一个让人安心的理由,这个解释就足够好。

3.2 Explainable Machine Learning 的分类
Explainable Machine Learning 的方法可分为两大类:
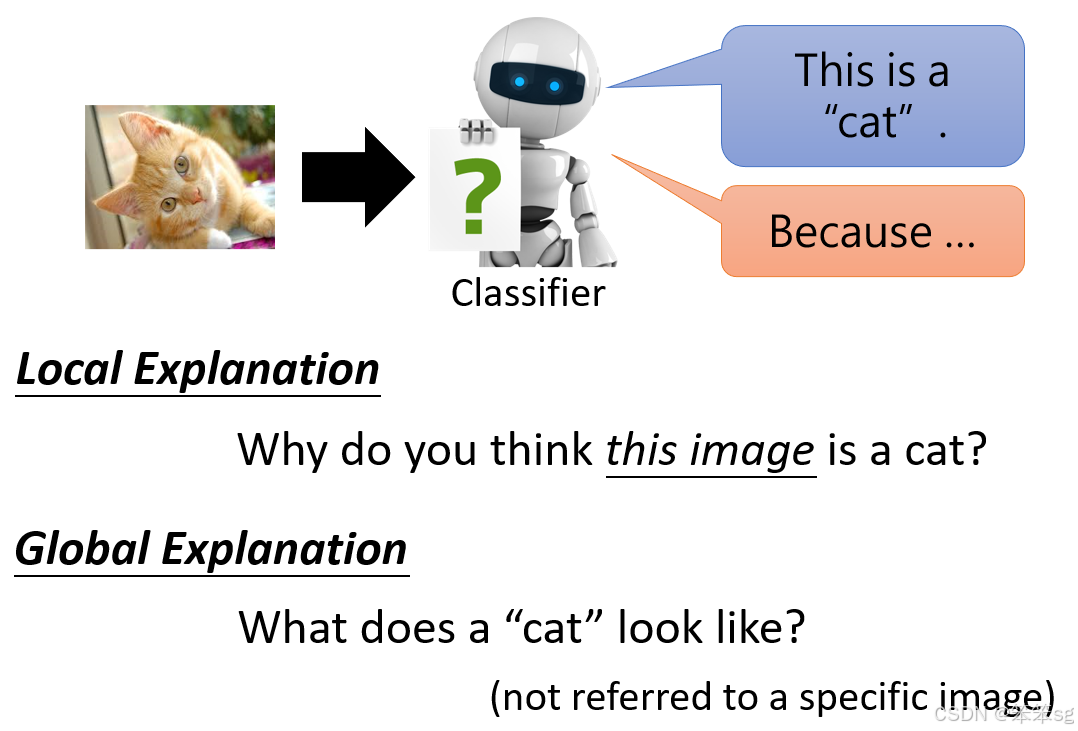
-
Local Explanation(局部解释):
针对特定输入提供解释。- 示例:一个图像分类器将一张图片判断为猫,Local Explanation 就是回答“为什么你认为这张图片是一只猫?”。这种解释基于模型如何对这张特定图片作出决策。
- 以下的4~8章节介绍的均为Local Explanation(局部解释)
-
Global Explanation(全局解释):
面向整个模型的总体行为提供解释。- 示例:分析一个图像分类器的全局规则,回答“什么样的图片被认为是猫?”。这种解释关注的是模型整体参数如何定义某个类别,而非特定输入的判断依据。
- 以下的9~章节介绍的均为Global Explanation(全局解释)
3.3 小结
Explainable Machine Learning 的终极目标是为复杂模型提供可信且可接受的解释,帮助人们更好地理解和信任机器学习模型的决策。无论是局部解释还是全局解释,核心都在于让人能够放心地使用模型,而不是彻底拆解模型的所有细节。
4 哪个Component(组件)是重要的?

4.1 通过修改或删除组件判断重要性
基本原则:如果修改或删除某个组件(如像素或词汇)会显著改变模型输出,则该组件对模型决策至关重要。
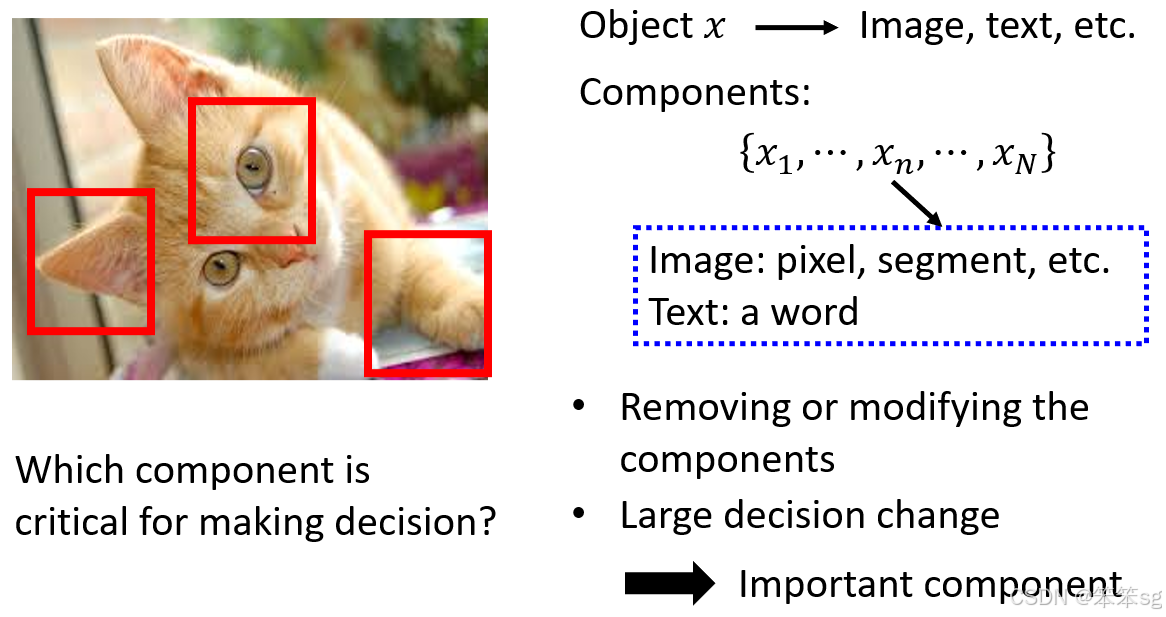
具体方法:

-
遮挡测试:
- 在输入图片上用灰色方块遮挡不同位置,然后观察模型输出的变化。
- 例子:
- 如果遮挡一只博美犬的脸部,模型不再认为它是一只狗,说明脸部区域对决策至关重要。
- 类似地,当遮挡轮胎图片的核心区域时,模型也无法正确判断为“轮胎”,表明模型关注的是关键部位而非背景。
-
多对象场景分析:
- 例如,图片中有两个人和一只阿富汗猎犬。通过逐一遮挡部分区域,发现即使遮挡人的脸,模型仍认为有阿富汗猎犬,说明模型的判断并非误认为人是狗,而是真的识别了猎犬的位置。
4.2 梯度计算(Gradient-Based Method)
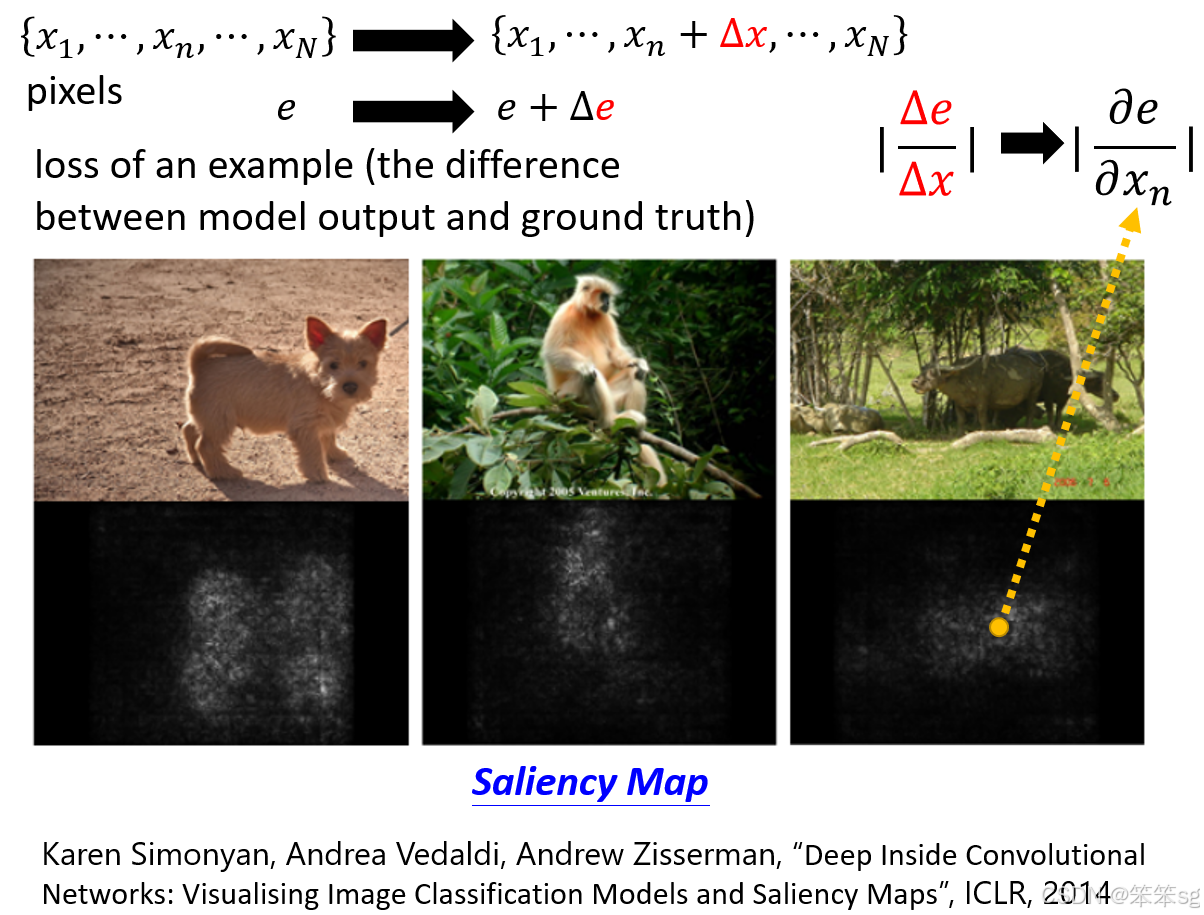
基本思想:分析模型预测结果(如交叉熵损失)对输入组件(如像素或词汇)的敏感性。
具体步骤:
-
计算偏导数:
- 输入图片的像素表示为 x1,x2,...,xNx_1, x_2, ..., x_Nx1,x2,...,xN。
- 计算损失函数 eee 对每个像素的偏导数:∂e∂xi\frac{\partial e}{\partial x_i}∂xi∂e。
- 如果某像素的值发生微小变化(Δxi\Delta x_iΔxi),导致损失 eee 有显著变化,则该像素很重要。
- 反之,若变化对损失无影响,则该像素可能不重要。
-
生成显著性图(Saliency Map):
- 将所有像素的重要性绘制成一张图:
- 白色区域表示重要性高;
- 黑色区域表示重要性低。
- 例子:
- 对水牛的图片,显著性图显示模型关注的是水牛本体,而非草地或竹子。
- 对猴子的图片,显著性图清晰地标记了猴子在树梢上的位置,而非树叶。
- 将所有像素的重要性绘制成一张图:
5 示例学习:Pokemon vs Digimon
5.1 Saliency Map 的介绍与作用
Saliency Map 是一种通过计算每个输入组件(如像素或词汇)对模型决策贡献的大小,来解释模型预测结果的技术。
- 白色区域表示对模型决策重要性较高,黑色区域表示重要性较低。
- 它帮助我们理解模型的决策依据,并验证模型是否基于合理的特征做出判断。
5.2 实际应用示例:宝可梦与数码宝贝分类问题

-
实验背景:
- 宝可梦和数码宝贝是两种虚拟动物,它们的外观特征十分相似,人类难以准确区分。
- 构建了一个二分类模型,通过训练和测试分类宝可梦和数码宝贝的图片。

-
实验结果:
- 训练集准确率:98.9%。
- 测试集准确率:98.4%。
- 结果看似非常成功,机器学习似乎能轻松完成这项人类难以完成的任务。

-
Saliency Map 分析:
- 数码宝贝图片:Saliency Map 显示模型关注的是图片的四角,而不是数码宝贝的本体。
- 宝可梦图片:Saliency Map 结果更明显,模型关注的是背景区域,而非宝可梦本身。


问题原因:宝可梦图片使用 PNG 格式,背景为黑色;数码宝贝图片使用 JPEG 格式,背景非黑色。模型仅通过背景格式的差异就完成了分类,而没有学习图片中真正的内容特征。

5.3 真实场景示例:PASCAL VOC 2007 数据集
- 任务:从 PASCAL VOC 2007 数据集中分类物体图片。
- 异常现象:
- 一张马的图片,模型正确地分类为“马”,但 Saliency Map 显示模型关注的是图片左下角的英文标记,而非马的特征。
- 问题原因:
数据集中许多马的图片来源于同一个网站,该网站的水印文本出现在左下角,模型实际上学会了识别水印,而非马的特征。

5.4 总结:Explainable AI 的必要性
-
发现潜在问题:
- Saliency Map 揭示了模型可能基于无关特征(如背景颜色或水印)做出预测的问题。
- 这种问题在真实世界中并不罕见,可能导致模型在实际应用中的表现远不如测试时理想。
-
改进模型训练:
- 通过可解释技术,可以发现数据集和训练流程中的问题(如数据偏差或标签泄漏)。
- 针对问题优化数据集(如调整图片格式、一致化背景)或模型设计。
-
提升模型信任度:
- 可解释性为模型决策提供透明依据,使研究人员或用户对 AI 的决策过程更加信任。
6 SmoothGrad
6.1 背景与问题
Saliency Map 是解释机器学习模型的重要工具,但直接生成的结果可能包含大量杂讯,难以清晰地展示模型的关注点。
- 示例:对瞪羚图片生成的 Saliency Map 中,尽管瞪羚周围有较多亮点,但背景(如草地和天空)也出现了不少亮点,显得杂乱无章。

6.2 SmoothGrad 方法介绍
SmoothGrad 是一种改进 Saliency Map 的技术,可以减少杂讯,使结果更清晰,更容易解读。
-
核心思想:
- 在原始图片上添加随机噪声,生成多张稍有差异的图片。
- 对每张加噪图片分别生成 Saliency Map。
- 将所有 Saliency Map 的结果进行平均,得到最终的 SmoothGrad Map。
-
效果对比:
- 原始 Saliency Map:杂讯较多,亮点分布在瞪羚和背景区域。
- SmoothGrad 结果:亮点集中在瞪羚本身,背景的干扰显著减少。
6.3 SmoothGrad 的价值与局限性
-
提升解释性:
- SmoothGrad 减少了 Saliency Map 中的杂讯,使模型的决策依据更加直观。
- 在瞪羚的例子中,SmoothGrad 更加突出瞪羚作为模型关注点的重要性。
-
局限性与争议:
- 真实性问题:SmoothGrad 的结果更符合人类的直觉,但未必能真实反映模型的内部逻辑。例如,模型可能真的认为草地或天空的重要性不亚于瞪羚。
- 以人为主导的解释性:SmoothGrad 更强调解释性而非准确性,其目的是让人类(尤其是上级或客户)更容易接受模型的表现。
6.4 为何SmoothGrad得到的图像更容易观察呢?
单次 Saliency Map 可能会受到模型局部决策的影响,从而导致噪声点突出。通过引入随机性并多次生成结果,SmoothGrad 能够:
- 对不重要区域的噪声梯度值起到相互抵消作用,因为噪声是随机的,其在不重要区域的效果不会被累积。
- 在重要区域上,尽管存在噪声,但梯度值的变化总体保持一致性,平均后仍会显现出强的特征模式。
7 限制:梯度饱和度——梯度不能总是反映重要性
7.1 Saliency Map 的局限性
- 梯度值趋近于 0 的问题:通过 Saliency Map 来分析特征重要性时,基于梯度(Gradient)计算的结果可能不完全准确。例如:
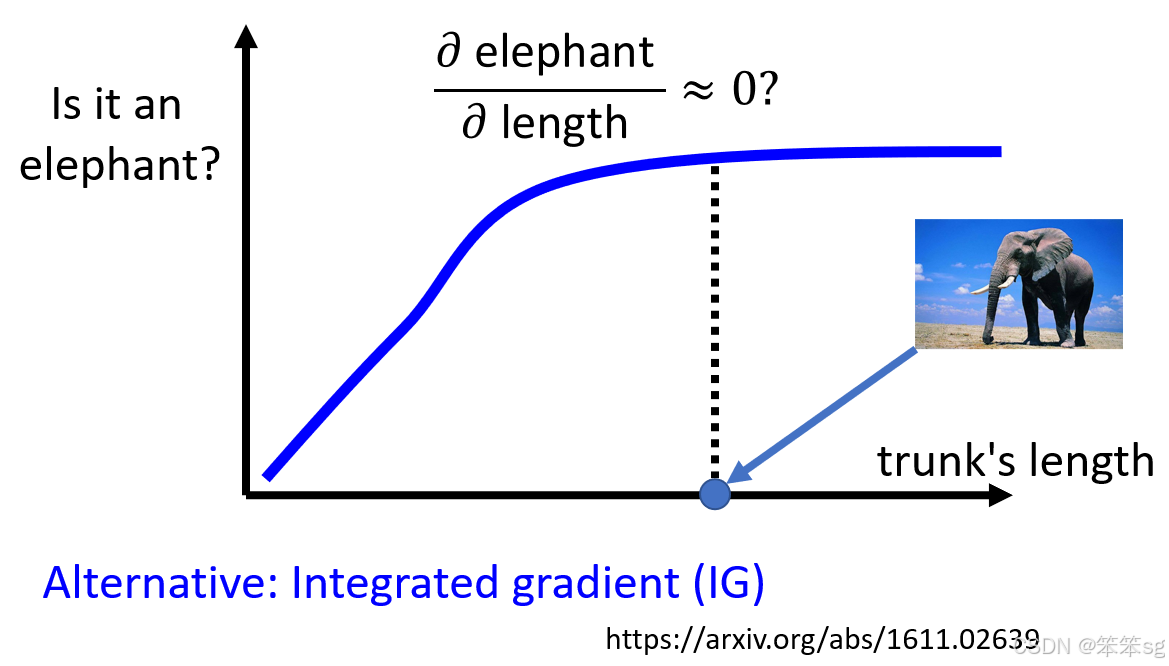
- 案例:大象鼻子的长度
鼻子的长度确实是判断是否为大象的重要指标,但当鼻子的长度达到一定值后,再增加长度不会显著改变大象的可能性。在这种情况下,鼻子长度对分类结果的梯度趋于 0,因此 Saliency Map 可能会误导我们,认为鼻子的长度不重要。 - 错误结论
光看梯度值可能忽视了某些重要特征(如鼻子长度),而这些特征实际上对模型的最终决策起到了关键作用。
- 案例:大象鼻子的长度
7.2 Integrated Gradients 的引入
为了解决上述问题,引入了一种改进方法:Integrated Gradients(IG)。
- 核心思想:IG 方法通过计算从基线(通常为全零图片或均值图片)到目标图片之间所有变化路径上的梯度累积,量化特征的重要性。这种方法可以避免梯度在某些点上趋于 0 时遗漏重要特征的问题。
- 直观效果:通过 IG,能够更全面地评估特征对模型输出的整体贡献,而不仅仅是关注当前输入点的局部变化。
7.3 具体案例的引申
- 横轴代表鼻子长度,纵轴代表分类概率
- 鼻子的长度对是否为大象的可能性一开始影响显著(梯度较大)。
- 随着长度达到一定值,影响趋于饱和(梯度趋于 0)。
- Saliency Map 的问题:只看当前的梯度,可能会忽略鼻子长度的整体贡献,导致错误的解释。
- IG 的改进:IG 累积从基线到输入值的所有梯度贡献,从整体视角评估特征的重要性,避免局部梯度导致的误导。
8 一个网络如何处理这个输入数据?
8.1 问题背景
- 研究输入的处理过程:想要理解深度学习网络是如何处理输入并生成最终输出的,例如:
- 输入的哪些部分重要(Saliency Map 的分析)。
- 输入在网络中的具体处理过程。
- 案例背景:在课堂例子中,研究的是语音信号的处理。
8.2 输入的处理流程
- 网络的各层输出可视化:假设一个语音识别网络的每一层有 100 个神经元:
- 第 1 层输出可以看作一个 100 维向量。
- 第 2 层输出同样是 100 维向量。
- 逐层分析这些向量有助于理解网络的运作机制。
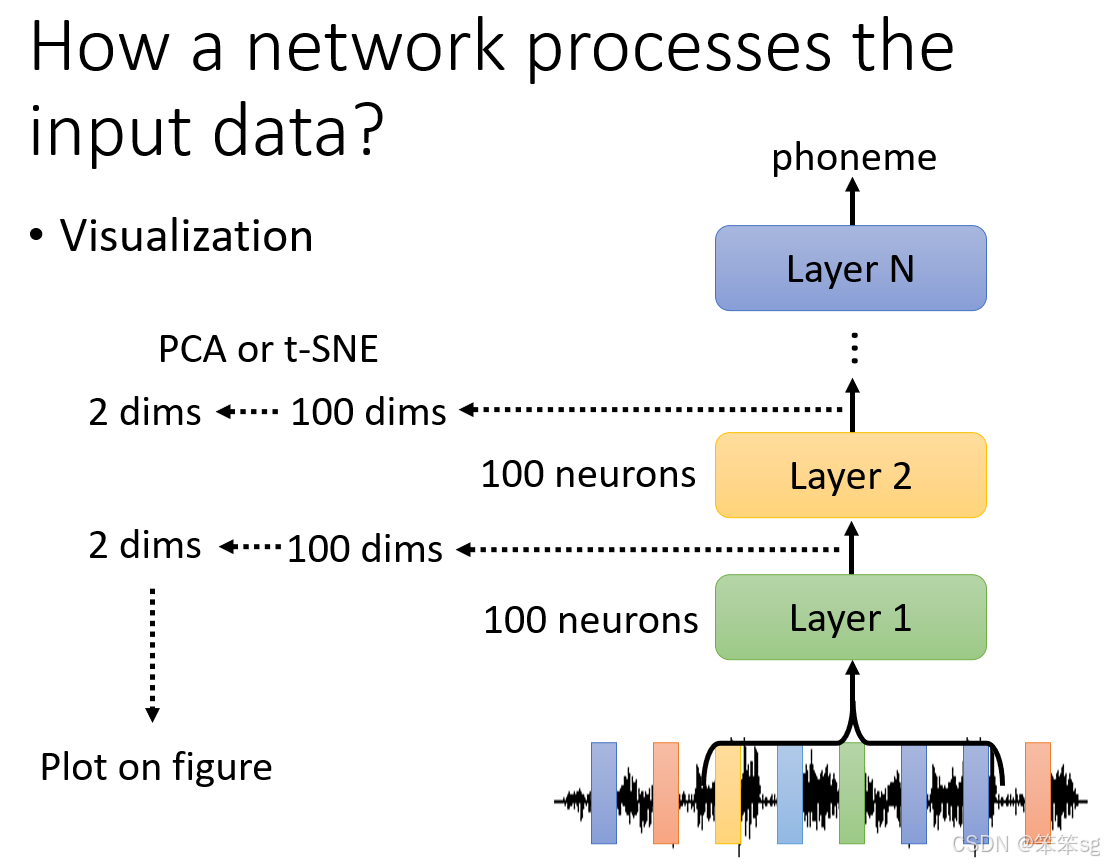
- 高维向量降维
- 由于高维向量难以观察和分析,通常通过降维技术(例如 PCA、t-SNE 等)将其降到二维,便于直观观察。
- 在二维平面中,每个点代表一小段语音信号,每种颜色代表一个说话者(Speaker)。
8.3 案例分析:语音信号处理
-
初始输入:Acoustic Feature(MFCC)
- 将原始音频信号(MFCC 特征)降到二维。
- 该数据集中包含了许多不同人说的相同内容句段,例如小明说“你真可爱”,小丽也说过“你真可爱”。
- 观察结果:
- 不同说话者说同样的句子时,特征分布仍然差异巨大。
- 相同的说话者说不同句子时,特征可能更为接近。
- 结论:单纯从 MFCC 特征中看不出内容的一致性。

-
深度网络的输出(第 8 层)
- 网络逐层处理输入后,输出逐渐表现出更高的语义一致性。
- 观察结果:
- 在第 8 层输出中,同一句话(内容相同)被不同的人说出的信号会 align 在一起。
- 不同内容的句子被分成不同的区域,表现为一条条有序的分布。
8.4 结果与启发
- 深度网络的能力
- 网络通过层层处理,将原始的语音特征映射到语义空间中,使得内容一致的信号最终 align。
- 网络在高层次学习到了与具体说话者无关的内容表征。
- 对比分析
- MFCC 特征:无法直接表现内容一致性。
- 高层网络输出:能够对不同说话者说同样内容的信号对齐,从而实现精准的分类。
- 启发:深度网络的核心能力在于逐层提取抽象特征,将复杂的信号转化为可解析的高层语义信息。
8.5 时代变迁的趣谈
- 案例来源:该例子来自 Hinton 教授在 2012 年的论文,研究 Deep Belief Network(DBN)对语音信号的处理。当时训练类似网络需要一周以上时间,而今天使用深度神经网络(DNN),训练同类模型仅需一小时。
- 趣味点
- 如果将今天的作业结果展示给当时的研究者,会让他们震惊。
- DBN 作为一种曾经的技术热点,现已被更强大的 DNN 取代。
8.6 直接分析神经元输出
- 降维观察:通过将高维的神经元输出降到二维并进行可视化,可以更直观地分析模型如何处理输入数据。例如,使用Hinton等人的语音识别实验,通过模型的多层输出,展示了如何将不同人说同样内容的句子对齐(align)。
- 应用案例:在语音识别中,初始的MFCC特征无法区分不同人讲的相同句子,而在模型第8层的输出中,不同人的相同句子可以被成功对齐,说明网络学会了去除语者信息,仅保留了内容信息。
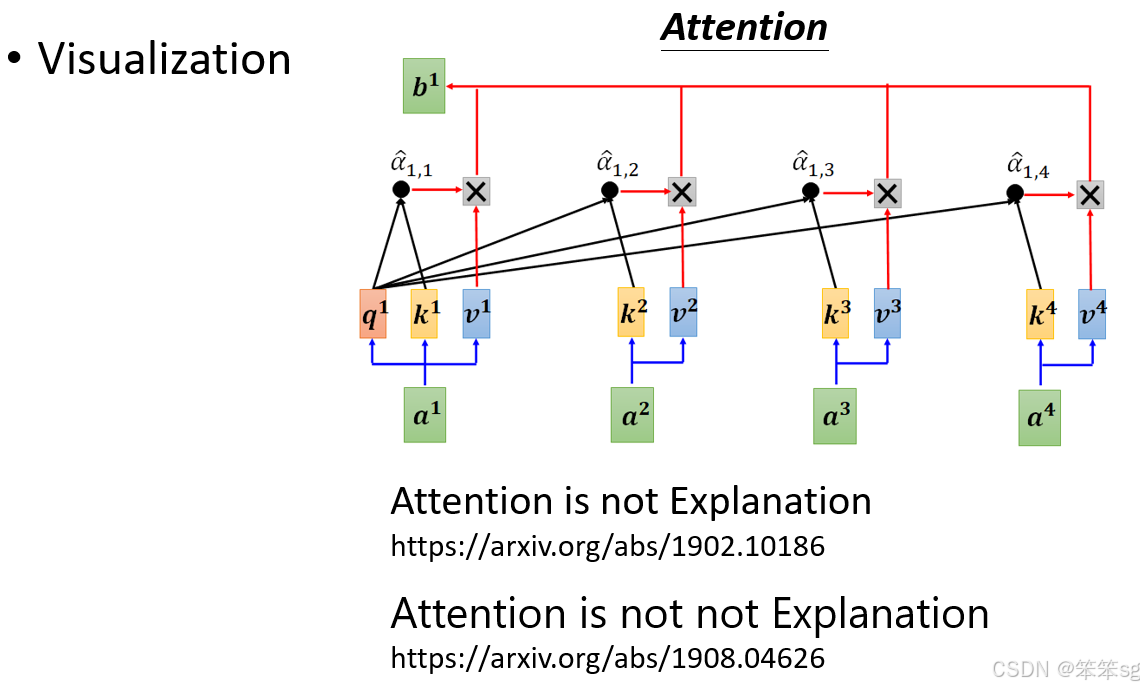
8.7 Attention层的分析
直觉与争议:Attention被认为具有解释性(如一个词汇“attend”到另一个词汇),但文献中也有争议(如“Attention is not Explanation”)。研究仍在探索哪些情况下Attention可以解释模型行为。
8.8 Probing方法
- 定义与分类器分析:Probing通过训练探针(分类器)来分析网络某层学到的信息。例如,用POS分类器判断Embedding中是否含有词性信息;用NER分类器判断是否含有实体名称信息。
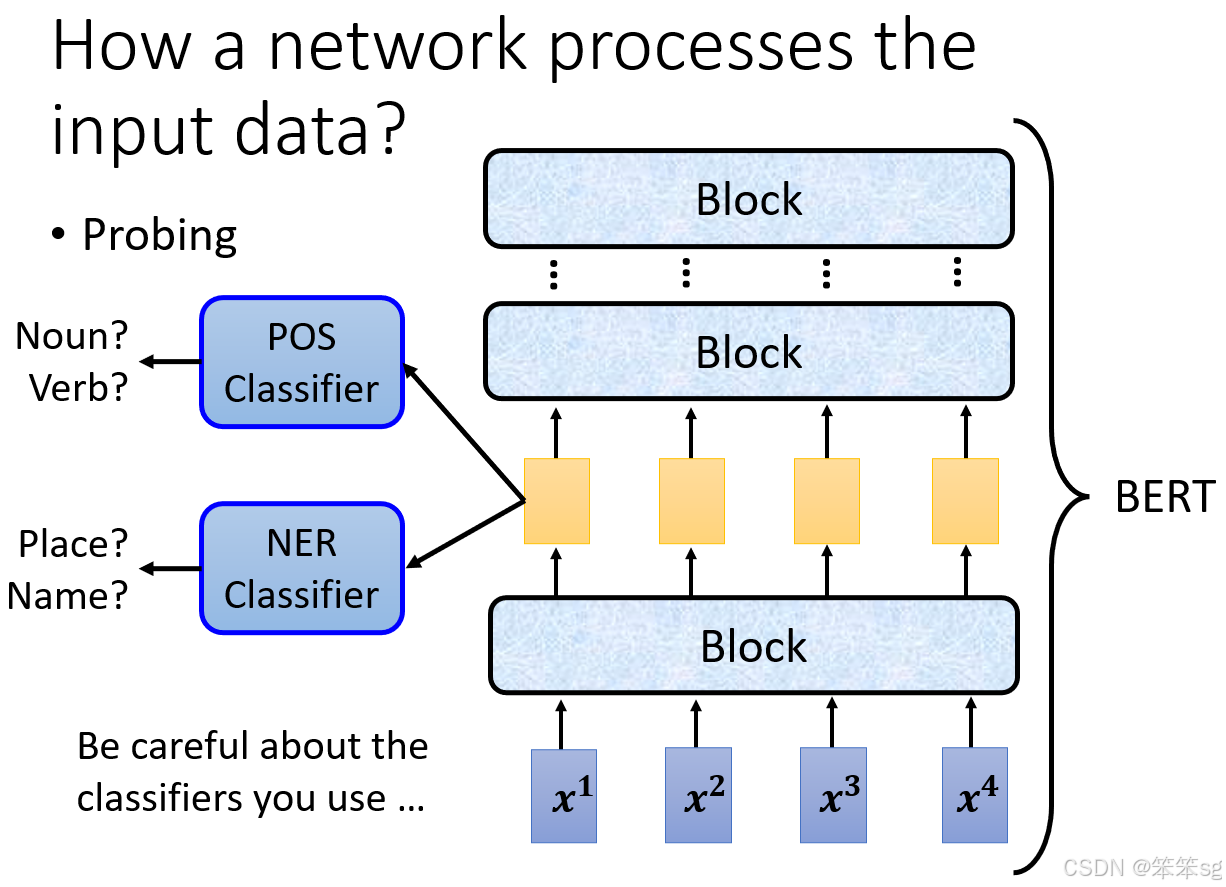
- 注意点:
- 分类器性能可能影响分析结果。若分类器表现差,可能是因为其训练不足,而非Embedding缺乏目标信息。
- 需控制分类器的复杂度,避免过强或过弱对结果的影响。
8.9 特殊的Probing案例
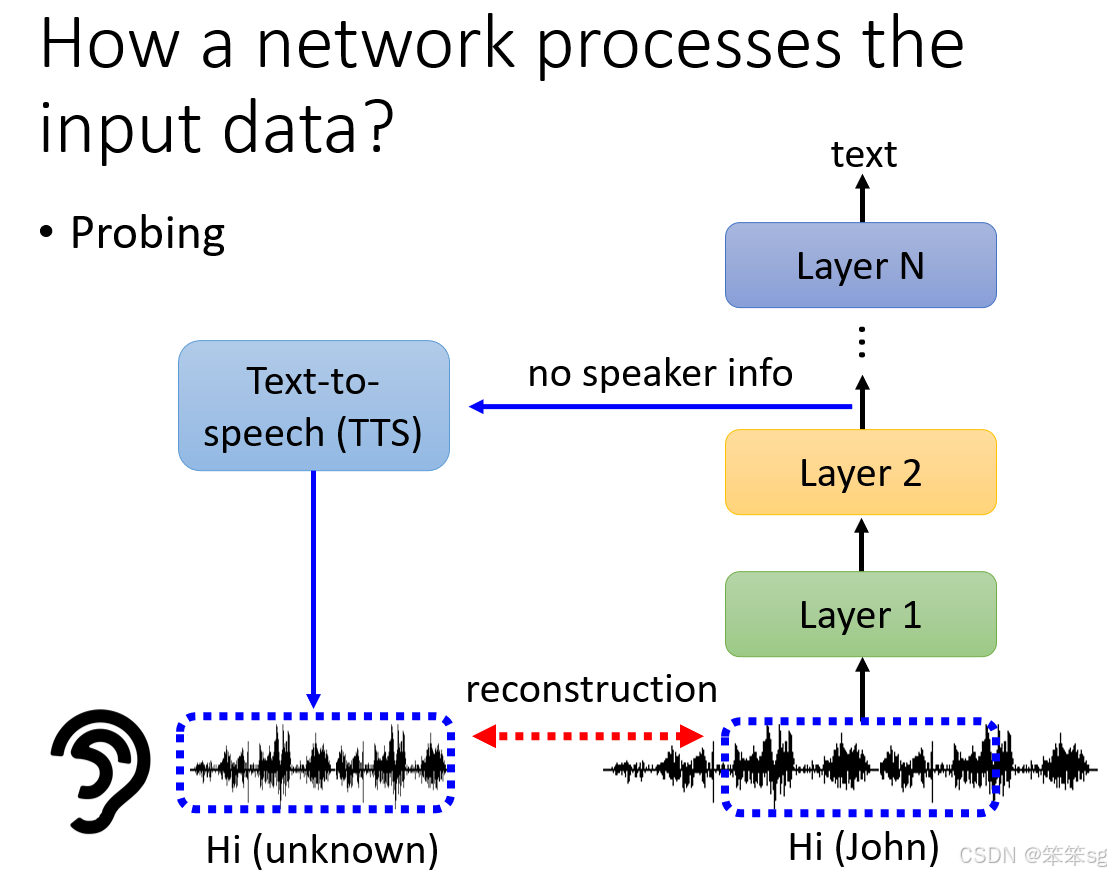
- 语音合成验证:将模型某层的Embedding输入到TTS(文本到语音转换)模型中,尝试重建原始的声音信号。
- 发现语者信息的消除:在语音识别模型中,经过多层LSTM后,语者的声音特征被去除,仅保留内容信息。通过TTS模型重建的语音,虽然内容相同,但已听不出原语者是谁。
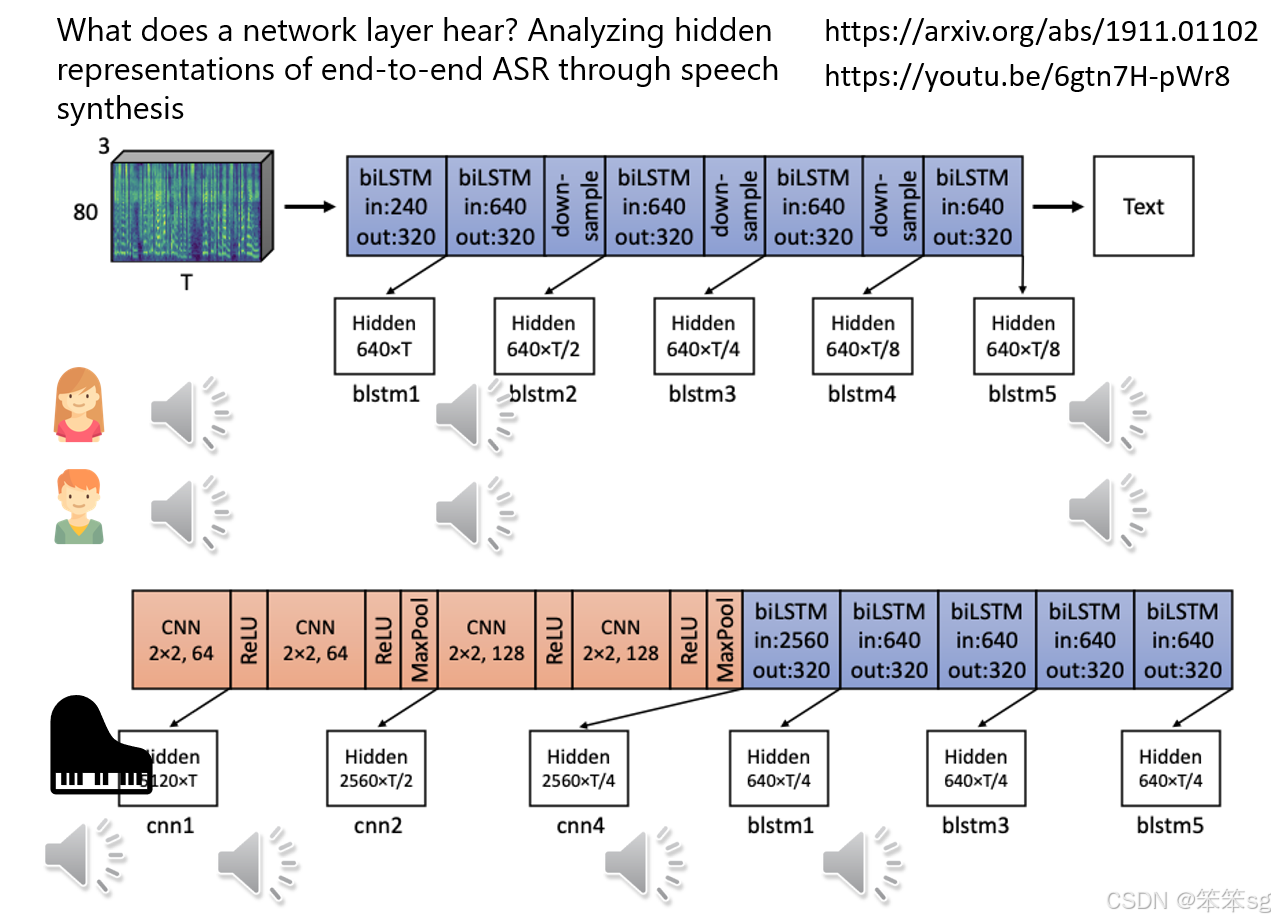
- 噪声的过滤:分析语音模型中每一层的输出,发现噪声(如钢琴声)在特定层(如第一层LSTM)被逐渐滤除,而前面的CNN层未起到显著的过滤作用。
9 过滤器能检测到什么?

9.1 Global Explanation 的定义:
与 Local Explanation 针对特定输入的分析不同,Global Explanation 是分析神经网络模型在整体层面上学到了什么。它不是针对某一张图片分析,而是从模型的角度出发,揭示模型所学到的特征。
9.2 模型训练与卷积神经网络(CNN):
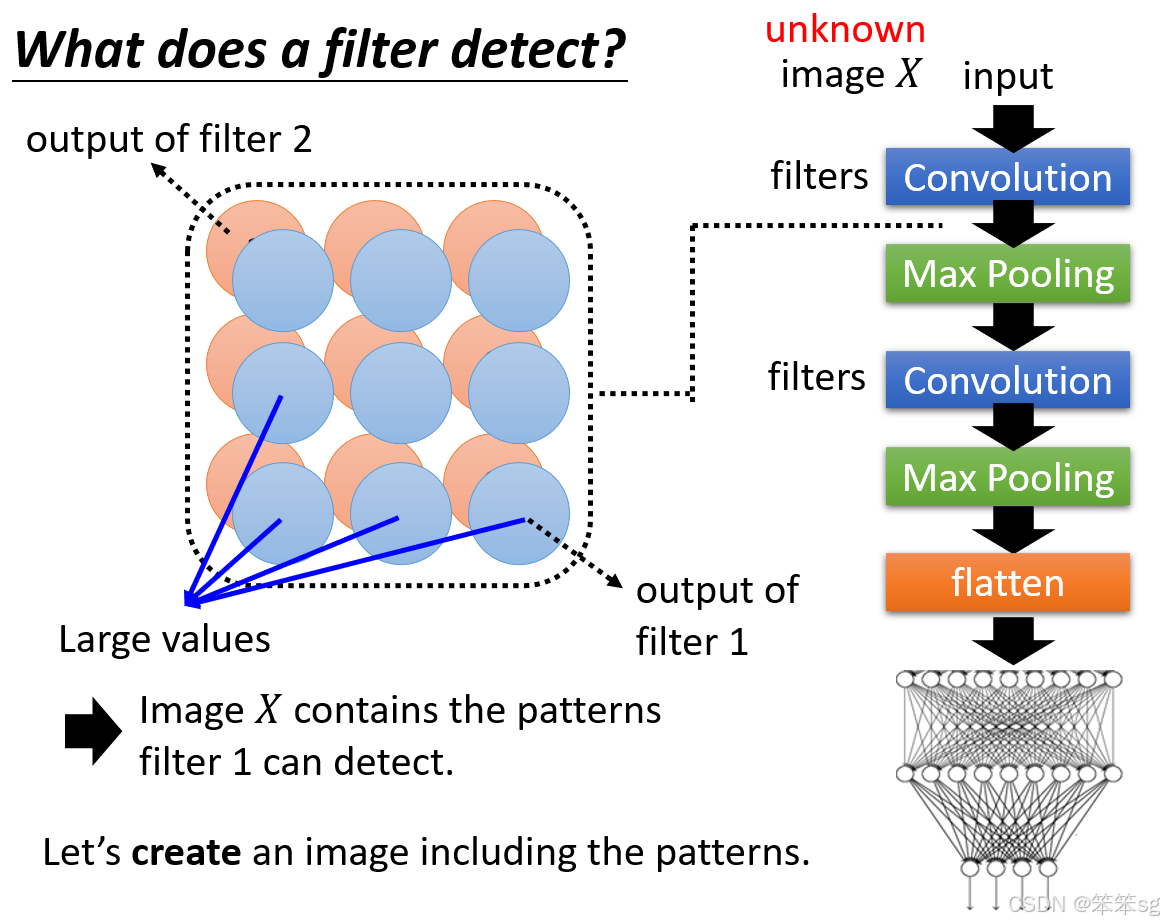
假设我们已经训练好了一个卷积神经网络(CNN),这个网络包含多个卷积层和滤波器(Filter)。每个卷积层的滤波器负责从输入图像中提取特定的特征。假设输入图像为 X,通过卷积层,滤波器输出特征图(Feature Map),而每个滤波器都会根据图像中的某些特征输出一个数值。
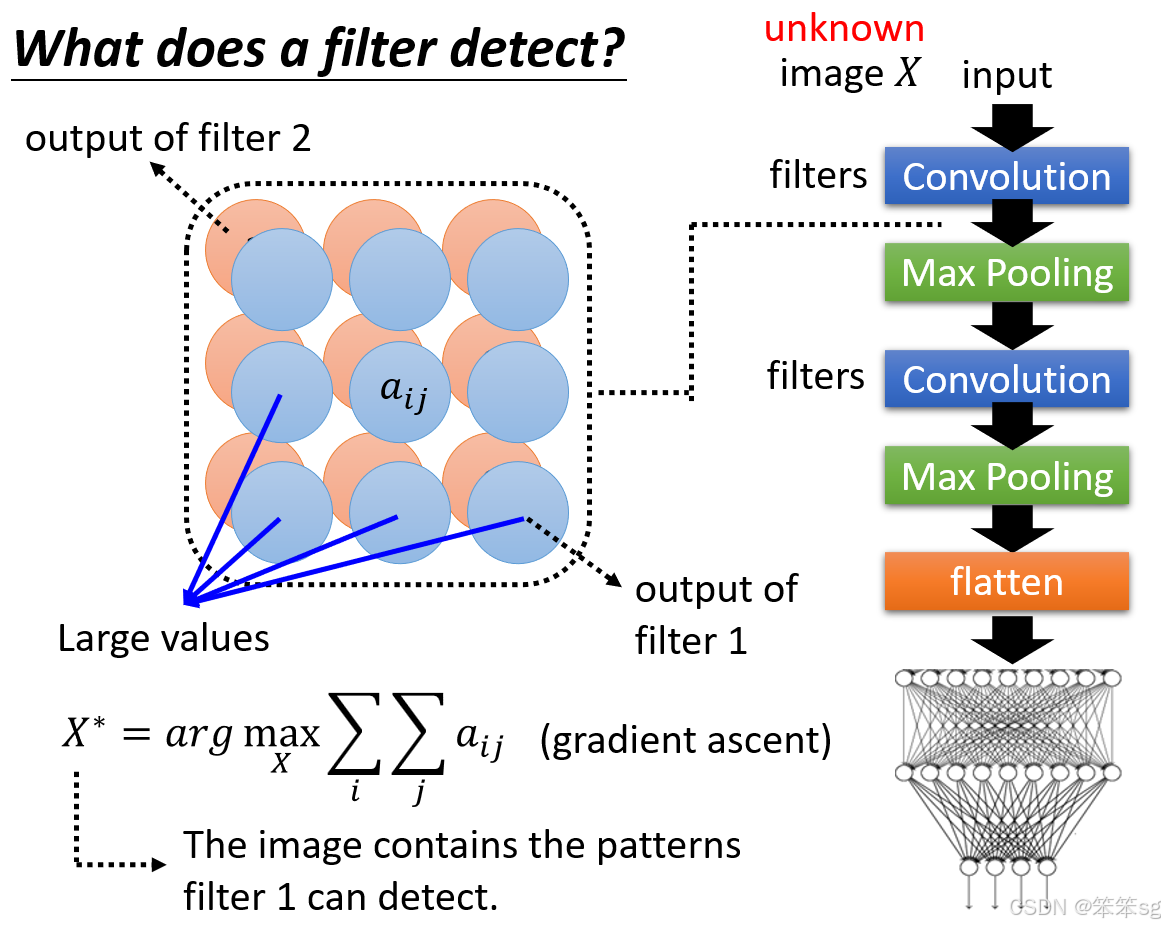
9.3 如何进行 Global Explanation:
在进行 Global Explanation 时,我们不关注某张具体的图像,而是想要理解某个滤波器(Filter)所能检测的模式。例如,如果某个滤波器在特征图中产生了较大的输出值,说明它检测到了特定的图案或特征。Global Explanation 的目标是构造一张新的图像 ,这张图像并非数据集中的任何一张图片,而是通过机器生成的,旨在最大化该滤波器的输出特征图的值。
也就是现在我们要反着来,来生成一个输入图像,使得其经过滤波器后得到的特征图的所有数值之和最大化。
9.4 生成目标图像  :
:
我们假设 是一个未知变量,通过训练找出这张图像,使得它能够最大化某个滤波器的输出特征图的值。为了实现这一点,采用类似梯度上升(Gradient Ascent)的方法,优化
使得滤波器的特征图中的数值最大化。
如何最大化:
这通常是通过“梯度上升”(Gradient Ascent)的方法实现的。类似于梯度下降(Gradient Descent)优化算法,梯度上升是通过计算损失函数相对于输入图像的梯度,然后沿着梯度的方向调整图像,从而增加目标值(在这里是滤波器的输出特征图的值)。
9.5 实际操作结果 - 使用 MNIST 数据集:
以 MNIST 数据集为例,训练一个手写数字分类器。通过对第二层卷积层的滤波器进行分析,我们可以生成每个滤波器的对应图像 。每张图片对应于一个滤波器,它展示了该滤波器检测的特定模式。例如,某些滤波器可能会检测到横线、斜线或其他基本的笔画模式。

9.6 总结:
在卷积神经网络中,每个滤波器的任务是检测输入图像中的基本模式或特征,而通过 Global Explanation,我们可以创造出一张图像,揭示该滤波器所检测的模式。通过这种方式,我们能够更好地理解神经网络在进行图像分类任务时的工作机制,尤其是在处理像手写数字这样的图像时,卷积层滤波器对笔画形态的侦测尤为重要。
10 CNN认为一个数字长什么样子?
10.1 Global Explanation 的目标:
- 在 Global Explanation 中,我们的目标并不是查看单个滤波器的作用,而是理解整个图像分类器(如数字分类器)如何做出决策。
- 通过优化某一类别的输出,我们希望找到一张图片 X,使得该分类器对某个类别(如数字 1)的预测分数最大化。

10.2 观察到的现象(杂讯问题):
- 当我们仅仅优化某一类别的输出时,得到的图片通常会充满杂讯,而无法明确看到某个数字。这是因为模型可能不需要看到非常明确的数字特征,只要有一些不显眼的噪音就能影响模型输出。例如,机器可能会认为这张杂乱无章的图像仍然是数字 1。
- 这与对抗攻击(Adversarial Attack)类似,虽然人眼无法识别,但模型仍然能正确地识别为某个类别。
10.3 如何改进结果(加限制):
- 为了让生成的图片更符合我们对数字的认知,我们需要在优化过程中加入一些限制(Constraints)。这些限制可以确保生成的图像在某种程度上更像我们所期待的数字。
- 例如,可以添加约束条件,要求生成的图片具有更少的白色像素,以减少噪音并更接近数字的笔画特征。

10.4 案例研究(添加额外限制以生成合理图像):
- 在实际应用中,例如使用 Global Explanation 方法反推分类器内部对某些动物(如丹顶鹤、甲虫)的理解,确实能够得到更接近实际动物样子的图像。但要做到这一点,并不是简单的操作,需要加入大量的约束和超参数调优。
- 通过深入理解目标对象(如丹顶鹤或甲虫)的特征,可以加入更多的约束条件,结合调节超参数(如学习率等)来精确地生成符合预期的图像。
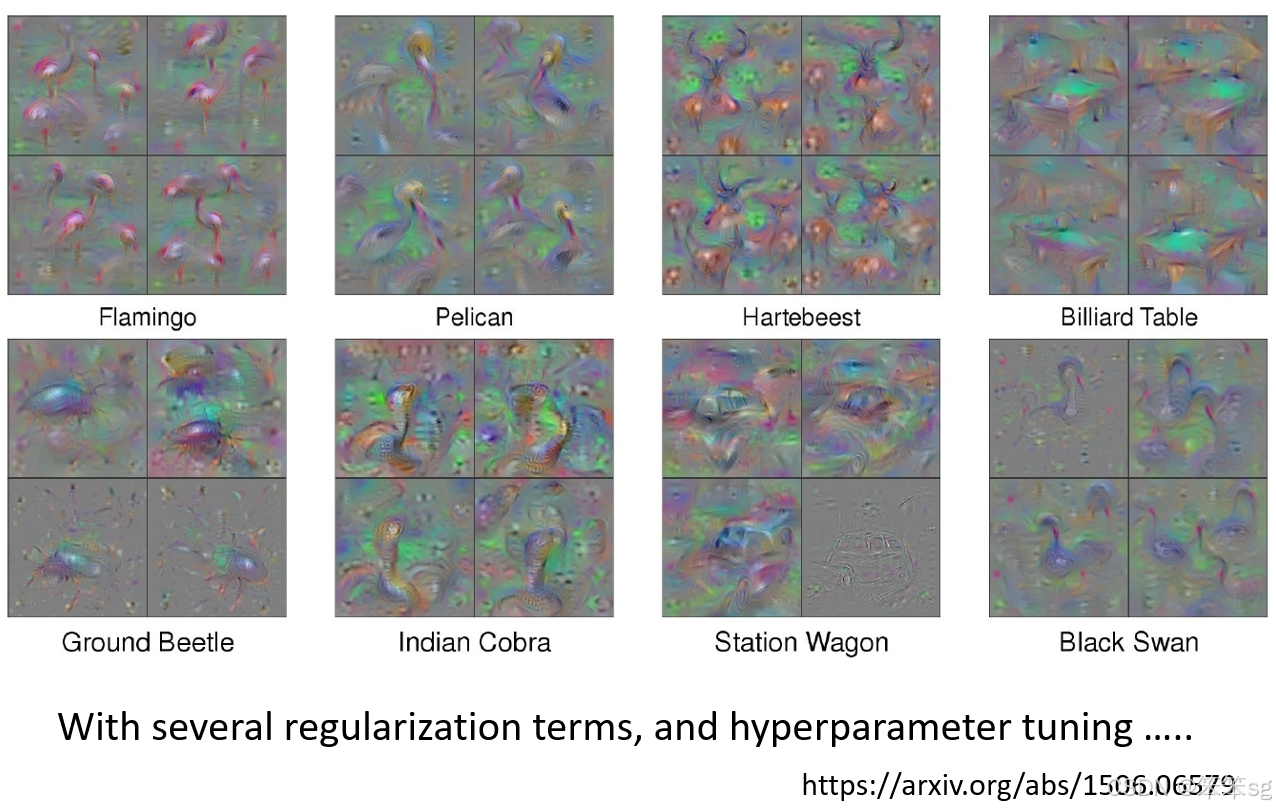
10.5 总结:
- 通过 Global Explanation 方法来理解分类器如何识别特定类别,虽然能够生成对应的图像,但生成的图像是否具有可理解的意义,取决于加入的约束条件和对目标对象的理解。
- 这些技术并不容易实现,需要细致的调节和大量的参数优化,以确保生成的图像具有更高的可解释性和现实感。
11 来自生成器的约束
11.1 使用生成器(Generator)来增强解释性:
- 为了更清晰地看到图像分类器(Image Classifier)所“想象”的某个类别(如猫或狗)的样子,可以使用图像生成器(如GAN或VAE)。
- 生成器是通过输入低维度的向量 z 来生成图像 X,其中 z 是从高斯分布中抽样的低维度向量。
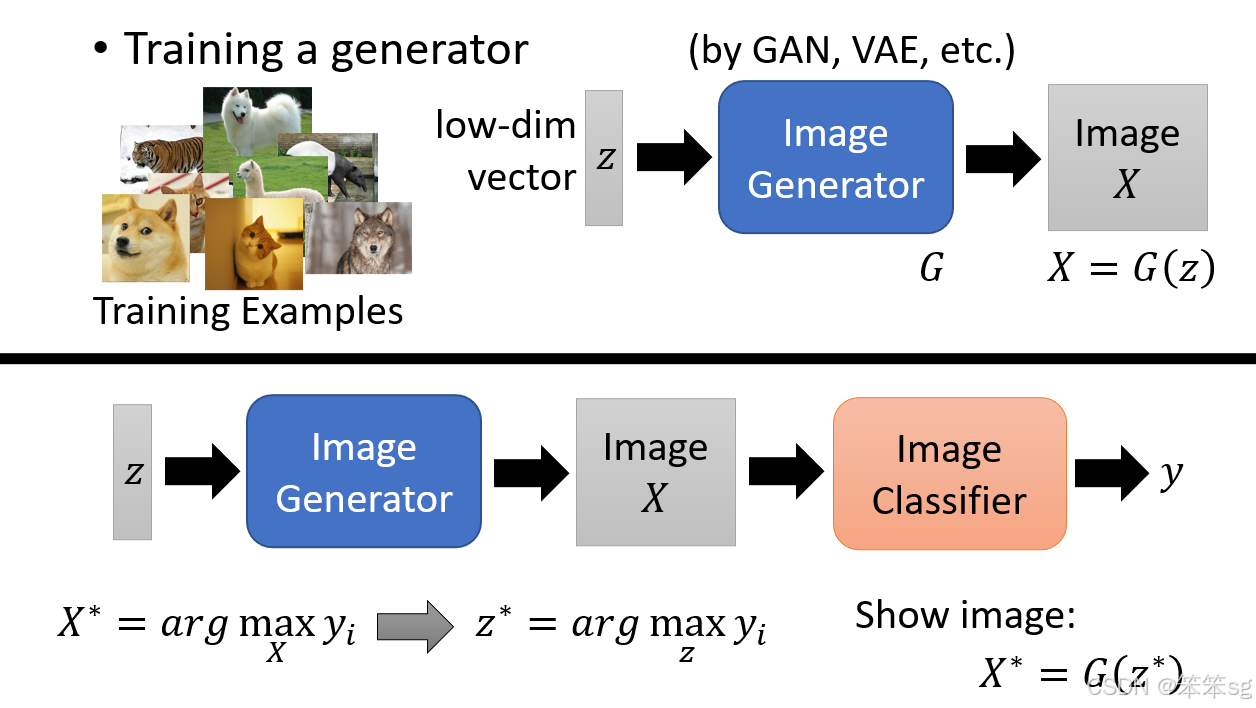
11.2 图像生成器和分类器结合:
生成器和分类器结合的过程是:我们通过优化一个低维度向量 z 来最大化分类器对某个类别的预测分数(例如,最大化分类器对“猫”的预测信心分数)。这样,我们不是直接优化图像 X,而是优化输入到生成器中的向量 z,然后生成图像 X,通过分类器输出最终的类别分数。

11.3 通过优化 z 得到最优图像:
- 目标是找到一个最优的向量
,使得生成器生成的图像
对某个类别的信心分数最大化。
- 例如,如果我们希望生成一张能让分类器认为是“蚂蚁”的图片,优化
- 类似地,可以优化得到能够让分类器认为是“火山”的图像。
11.4 生成的图像是否符合直觉:
- 尽管使用生成器方法可以生成高信心分数的图像,但这些图像可能并不总是符合我们直观认知的“蚂蚁”或“火山”的样子。
- 例如,生成的蚂蚁图像可能对于机器非常合适,但从人的角度看,可能不完全符合我们想象中的蚂蚁形象。
11.5 人类对生成结果的期待与机器的实际认知差异:
这引出了一个更深层次的问题:我们在解释AI时,往往更倾向于通过一些方法来生成符合人类直觉的图像,而不是机器本身的认知。例如,可能机器“心里”想象的数字就是一堆杂讯,但我们却不接受这一点,而是硬要调整生成的方法,让机器“产生”一个我们能接受的解释性结果。
11.6 解释性AI的挑战:
解释性AI的技术常常有这种倾向:它不仅仅关注机器内部的真实“想法”,而是更多关注外部展示给人类的结果。这意味着,尽管我们不知道机器的真实思维方式,但我们更希望生成的解释结果是直观且让人类感到满意的,这样才能让用户(如老板或客户)感到满意。
12 结束语
12.1 Explainable AI 的两种主流技术:
- 本文介绍了两种主流的可解释AI技术:Local Explanation 和 Global Explanation。
- Local Explanation 侧重于解释单个预测的结果,而 Global Explanation 侧重于解释整个模型的行为。
12.2 使用简单模型模仿复杂模型的行为:
- 另一种解释性方法是使用简单模型去模仿复杂模型的行为。比如,通过训练一个线性模型(Linear Model)来模拟神经网络(Neural Network)的输出。
- 具体方法是:通过输入
到
,神经网络输出
到
,然后训练一个线性模型使其输出与神经网络一致。如果成功,分析线性模型的行为,可能帮助我们理解神经网络的决策过程。
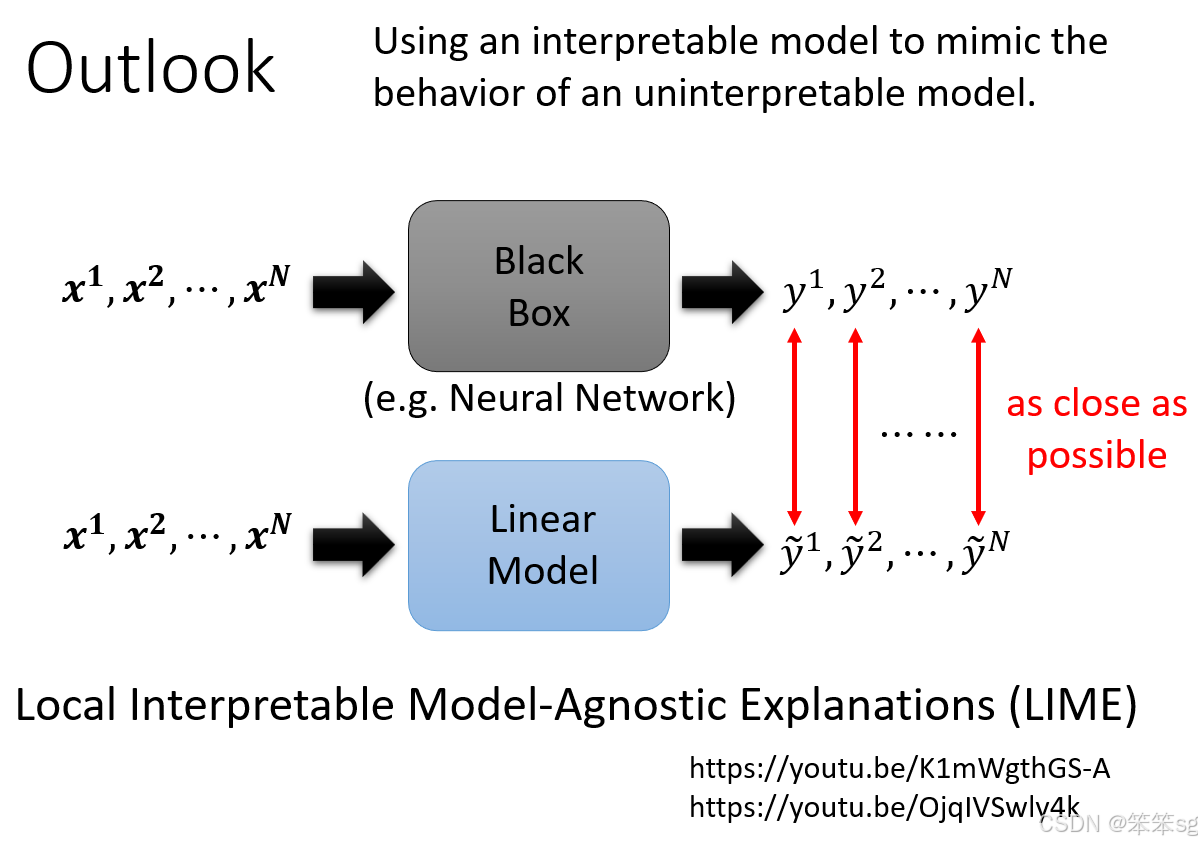
12.3 线性模型能否模仿神经网络的行为?:
- 尽管线性模型可能无法完全模拟神经网络的行为,特别是神经网络能够处理的复杂任务,线性模型能够局部模拟神经网络的某些行为。
- 这里提到的经典方法是 LIME(Local Interpretable Model-Agnostic Explanations),它通过训练线性模型来模仿黑盒模型在局部区域内的行为。LIME方法的优势是可以对复杂模型的局部行为进行解释。
12.4 LIME 方法的特点:
- LIME 方法的关键在于它不试图模仿整个神经网络的行为,而是局部地模拟神经网络在某一特定区域内的决策过程。这样,尽管线性模型的能力有限,但能够提供对复杂模型的某些理解。
- LIME 是一种非常经典的方法,如果想深入了解,可以通过文献学习。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









