








 本文对比了Kafka和RocketMQ两大消息中间件的特点。Kafka通过Zookeeper进行协调,支持选举机制,确保高可用性;RocketMQ则通过Namesrv进行协调,采用镜像同步保证高可用。Kafka在消息存储上采用多文件并发写入,吞吐量较高,而RocketMQ采用单一文件的commitLog方式。两者在协调节点设计和消息存储方式上各有优势。
本文对比了Kafka和RocketMQ两大消息中间件的特点。Kafka通过Zookeeper进行协调,支持选举机制,确保高可用性;RocketMQ则通过Namesrv进行协调,采用镜像同步保证高可用。Kafka在消息存储上采用多文件并发写入,吞吐量较高,而RocketMQ采用单一文件的commitLog方式。两者在协调节点设计和消息存储方式上各有优势。
概述
在网上看到一篇主要讲清楚kafka和rocketMq的两个不同点的文章;1、rocketMq的namesvr和kafka的zookeeper对比;2、kafka为什么比rocketMq有更大的吞吐量。所以摘录下来学习一下。
namesrv VS zk
1、我们可以对比下kafka和rocketMq在协调节点选择上的差异,kafka通过zookeeper来进行协调,而rocketMq通过自身的namesrv进行协调。
2、kafka在具备选举功能,在Kafka里面,Master/Slave的选举,有2步:第1步,先通过ZK在所有机器中,选举出一个KafkaController;第2步,再由这个Controller,决定每个partition的Master是谁,Slave是谁。因为有了选举功能,所以kafka某个partition的master挂了,该partition对应的某个slave会升级为主对外提供服务。
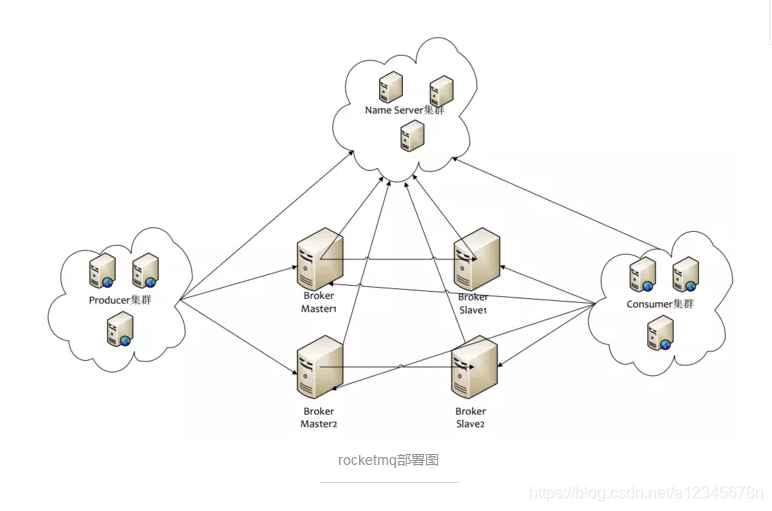
3、rocketMQ不具备选举,Master/Slave的角色也是固定的(集群中有写磁盘和内存)。当一个Master挂了之后,你可以写到其他Master上,但不能让一个Slave切换成Master。那么rocketMq是如何实现高可用的呢,其实很简单,rocketMq的所有broker节点的角色都是一样,上面分配的topic和对应的queue的数量也是一样的(镜像同步),Mq只能保证当一个broker挂了,把原本写到这个broker的请求迁移到其他broker上面,而并不是这个broker对应的slave升级为主。
4、rocketMq在协调节点的设计上显得更加轻量,用了另外一种方式解决高可用的问题,思路也是可以借鉴的。
关于吞吐量
1、首先说明下面的几张图片来自于互联网共享,也就是我后面参考文章里面的列出的文章。
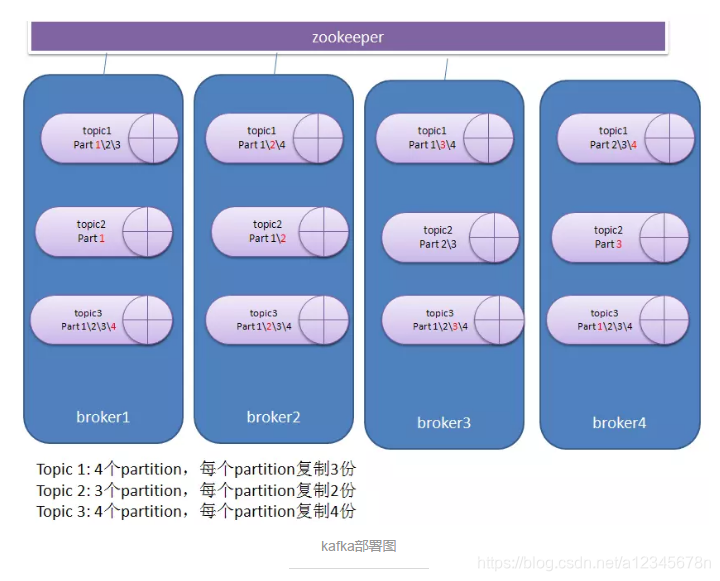
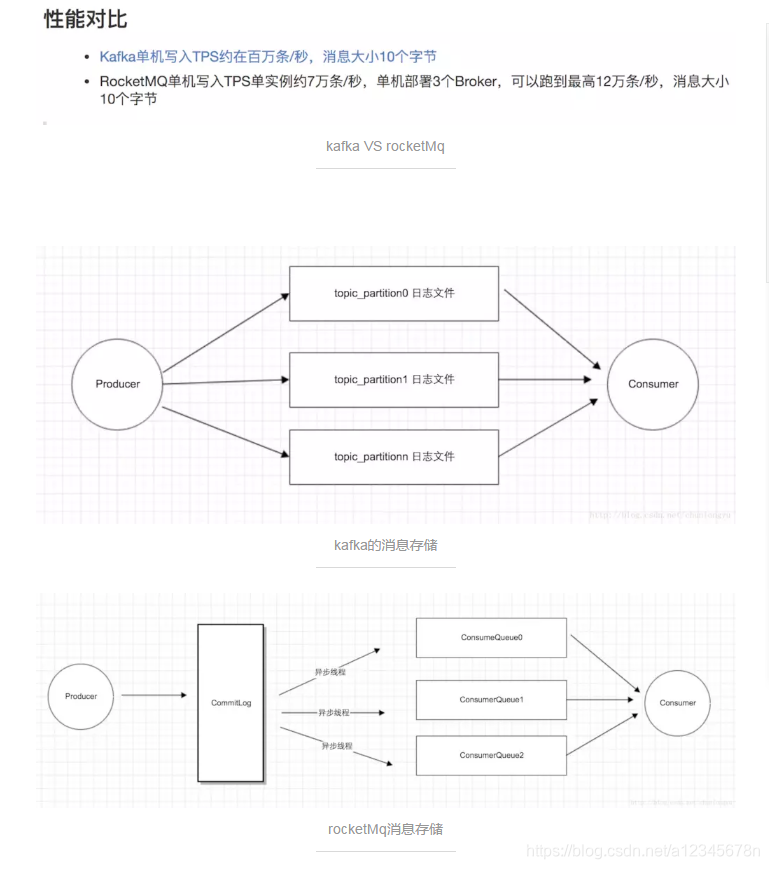
2、kafka在消息存储过程中会根据topic和partition的数量创建物理文件,也就是说我们创建一个topic并指定了3个partition,那么就会有3个物理文件目录,也就说说partition的数量和对应的物理文件是一一对应的。
3、rocketMq在消息存储方式就一个物流问题,也就说传说中的commitLog,rocketMq的queue的数量其实是在consumeQueue里面体现的,在真正存储消息的commitLog其实就只有一个物理文件。
4、kafka的多文件并发写入 VS rocketMq的单文件写入,性能差异kafka完胜可想而知。
5、kafka的大量文件存储会导致一个问题,也就说在partition特别多的时候,磁盘的访问会发生很大的瓶颈,毕竟单个文件看着是append操作,但是多个文件之间必然会导致磁盘的寻道。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









