



第3章 自然语言处理、情感分析和临床分析
3.1 简介
大数据革命改变了科学家在几乎所有(如果不是全部)研究领域中解决问题的方式(利特拉斯、拉加万和达米亚尼,2017年)。大数据领域汇集了计算机科学多个分支的概念,包括自然语言处理(NLP)、信息检索(IR)、人工智能、机器学习(ML)、网络分析和图论等。上述领域几十年来一直是计算机科学研究的重要组成部分。然而,Web 2.0 和社交媒体的出现导致了大数据的三个V——多样性、真实性和体量(莱尼,2001年)。
3.1.1 自然语言处理与医疗/临床分析
心理学和精神病学领域的研究人员和从业者面临的一个挑战是难以获取能够真实反映受试者/患者心理状态的数据。传统方法依赖于从受试者及其直系亲属/朋友收集数据,和/或要求特定群体中的部分个体填写调查/问卷,以期获得有关不同个体或群体心理状态的洞察。
情感分析领域——也被称为意见挖掘——使科学家能够筛选通过各种来源收集的文本,并了解相关主题的感受。该领域在很大程度上依赖于自然语言处理技术。自然语言处理使机器能够处理人类自然语言,并将其转换为机器可理解的格式。自然语言处理起源于20世纪60年代,但随着万维网和搜索引擎的出现而变得非常流行。搜索引擎的查询处理能力需要为用户输入的术语添加上下文,进而呈现一组可供用户选择的结果。
3.1.2 情感分析
利用自然语言处理技术,情感分析领域会分析用户的表达式,并据此将情绪与用户提供的内容相关联。文化规范为这一领域增添了不同的复杂性。例如,以下陈述可能会被非常不同地解读。
这个新玩意真糟糕!
虽然字面意思暗示用户不喜欢该设备,但属于特定年龄组的用户群体可能会将上述陈述视为对该设备的强烈认可。此外,情感分析还会考察用户表达情感或观点的时间。同一用户可能受到某些压力因素的影响,从而影响其判断力,因此在时间连续体上收集陈述可以更准确地反映所表达的情感。
社交媒体平台在这一领域既带来了挑战也带来了机遇。从积极的角度来看,它为在网络上写作的人提供了匿名性,从而使其能够自由地表达自己的感受(拉贾德辛甘、扎法拉尼和刘,2015)。此外,可以针对特定时间段收集数据,这对于确保一致性至关重要。以这种方式获取的数据将提供大量证据来支持研究者的假设,并为科学推论奠定坚实的基础。从网络上收集数据已成为市场营销等许多领域的首选。谷歌、YouTube 和亚马逊就是企业如何向最终用户提供定制化内容的实例。许多此类领域在很大程度上依赖于点赞数、给定年龄范围内的商品总销量等客观指标。然而,心理学/精神病学领域却没有这样的便利,因为其数据是以用户在博客、社交媒体等各种媒体上撰写的文本形式存在的。这一维度增加了更多的复杂性,原因在于:(1)在某一主题或博客中使用了不同的语言,(2)使用了词典中无法找到的非标准词汇,以及(3)使用了表情符号和符号。这些问题由自然语言处理领域以及情感分析领域的专家共同应对。
有必要为社会科学家和精神科医生提供必要的词汇以及从网络采集数据、适当解析文本并提取上下文信息的基本工具。本文旨在朝这个方向迈出一步。具体而言,本文提供了以下内容:
- 提供对自然语言处理中各种流行理论的基本理解
- 解释自然语言处理的传统方法和统计方法
- 探讨在情感分析领域已开展的工作以及在心理健康问题背景下所面临的挑战
- 简要概述将自然语言处理概念应用于心理健康问题和情感分析的各种应用
本文将介绍每个部分的关键概念和定义,而不是将其全部集中在一个单独的章节中。
3.2 自然语言处理
自然语言处理领域已有数十年历史,多年来已显著成熟。最初局限于从有限的数字化文档中收集数据,而万维网的出现导致了多种语言的信息爆炸。在自然语言处理领域的一个应用——信息检索领域,人们进行了大量工作。在进一步讨论信息检索技术之前,让我们深入探讨一下自然语言处理的理论和实践方面。
3.2.1 传统方法——关键概念
最初,自然语言处理方法遵循以下离散步骤。
- 文本预处理/分词
- 词法分析
- 句法分析
- 语义分析
3.2.1.1 预处理/分词
第一个挑战是将给定的文档分割成词语和句子。词元——最初局限于编程语言理论——现在等同于将文本分割成词语。大多数语言使用空白字符作为分隔符,但在某些语言中可能会比较复杂。虽然看似简单,但其中的挑战包括将诸如“I’m”这样的词拆分为“I am”,以及决定是否将“high‐impact”这样的词元拆分为两个词语。文档的语言进一步增加了问题的复杂性。Unicode标准在这方面提供了极大的帮助,因为每个字符都被赋予了唯一的值,从而可以方便地判断底层语言。
自然语言处理专家经常使用的另一个概念是“正则表达式(RE)”。正则表达式同样源于计算机编程语言理论,它规定了需要查找的字符串格式。例如,仅包含大写字母的密码字符串(词元)将被表示为 [A-Z],而包含数字的字符串将被表示为 [0-9]。正则表达式的重要性将在下一小节中变得明显。
除了将文本分割成词元/词语外,自然语言处理领域还非常重视句子边界的识别。尽管许多语言会使用标点符号来定义句子边界时,中文、韩语等其他语言在这方面要困难得多。更复杂的是使用句号符号“.”的缩写形式。虽然句号用于结束句子,但像“Mr.”这样的词元可能会发出错误的信号。
3.2.1.2 词法分析
处理文本后,下一个挑战是将文本划分为词素。在语言学中,词素表示一个意义,被视为词汇表的基本单位。一个词素可以有不同的词尾形式,即屈折词尾。例如,“sleep”是一个可以呈现多种形式的单位,如“sleeping”、“slept”或“sleeps”。该单位词元也称为词元(lemma)。词素由黏着词素和自由词素组成。自由词素是可以作为独立词语的词素,例如 cat。黏着词素则是像“un”、“-tion”等的词缀和后缀。
在对文本进行预处理并将其分词为词语后,自然语言处理从业者会将每个词元缩减为其基本的词元形式。因此,“depression”和“depressed”这两个词都将被缩减为同一个词根形式——“depress”。此过程也称为词干提取,即将每个词元缩减为称为词干的词根形式。该术语在计算机科学中更为常见,在某些情况下可能与词元(lemma)不完全相同。这一技术最著名的算法是波特算法(Porter, 1980),其后续改进版本为波特2算法或Snowball算法。兰开斯特词干提取器也经常被使用,但被认为更具激进性。这将在实践部分进行更详细的讨论。
词干提取最重要的好处之一是收集给定文本中各个词语的频率分布。频率分布有助于推断当前所考虑文本的主题。在语言学和计算机科学领域广泛使用的著名tf-idf算法即是如此。tf用于衡量文档中术语出现的频率,并推断描述文档的主题/关键词。idf因子则侧重于消除常用词,如介词、冠词等,从而使tf因子能够准确表示当前文档的主题。尽管已提出并测试了许多其他技术,但在处理文本时,tf-idf算法通常作为起点。
3.2.1.3 句法分析
现在我们已经了解了如何通过词元的概念将文本分解为句子和词语,接下来的挑战是确保所处理的文本遵循语法规则并传达特定含义。句法分析就是确保遵循语法规则的过程。例如,考虑句子“Mary Joe road deer drive”。尽管词元和句号表明这是一个完整的句子,但它并不传达任何意义。语法被描述为一组规则。以下规则,
例如,描述表示数字的规则以及四种运算符,即加法、减法、除法和乘法。
, E.-Number
, E.-ð, E.Þ
, E.-, E. 1, E.
, E.-, E. 2, E.
, E.-, E.=, E.
, E.-, E. 3, E.
语法(称为数学语法)由终结符和非终结符组成。在上述示例中,Number 是终结符,而 ,E. 是非终结符。如果我们假设 Number 符号表示整数,那么以下表达式在解析时将符合上述语法。
1341 256; 134; ð256Þ
然而,诸如“ 134”、“134”、“25”和“134/12 34”之类的表达式将不符合上述语法。确保词元遵循特定语法的过程也被计算机科学家/计算语言学家称为解析。
处理文本需要前一小节中描述的词法分析器和一个解析器。尽管上述内容乍一看可能有些复杂,但可以这样思考:如果文本包含以下两个句子,如何判断这些句子是否符合英语语法?
狗追着球跑
球狗跑球的
看到上面这两个句子,人类会立即认为第二个句子是无意义语句,但计算机却不容易做出这样的判断。计算机科学家和计算语言学家传统上面临的问题是:自然语言是否可以用数学语法(也称为形式语法)来表示。研究人员传统上研究的语法最好用乔姆斯基层次结构(乔姆斯基等人,2012)来描述。形式语法可以如下划分:
- 无限制文法 :这类文法的规则形式为 α-β,其中 α和 β可以均为终结符、非终结符或为空。此类无限制文法是最通用的,包含了所有其他类型的文法。这类文法的问题在于它们过于宽泛,无法用于描述任何编程语言或自然语言。
- 上下文有关文法 :这类文法由如下形式的规则描述:αAβ-αγβ,其中 α和 β可以是非终结符、终结符或为空,γ可以是非终结符或终结符但不能为空,而A必须是一个非终结符。简而言之,上下文有关文法指的是某些词语只能在特定上下文中出现的现象。在特定上下文中是合适的——这是对人类来说很直观的问题。这类文法的问题在于它们在计算上极为困难(甚至可能不可判定)。请注意,上下文有关文法包含上下文无关文法和正则文法,但反之则不成立。
- 上下文无关文法 :这些文法由诸如 A-γ 的规则描述,其中 γ 可以是非终结符或终结符,但不能为空,且 A 必须是一个非终结符。这些文法用于描述大多数编程语言(如 C语言等)的语法。上下文无关文法包含正则文法,但反之不成立。
- 正则文法 :这些文法由 A-aB 或 A-Ba 描述,其中 a 是一个终结符,A 和 B 都是非终结符。正则文法用于定义编程语言的搜索模式和词法结构。
计算机科学和计算语言学领域的研究人员长期以来面临的问题是,上述方法虽然足以描述编程语言,但对于自然语言来说却不够充分。这一问题将通过统计方法来解决,我们将在第3.2节中看到。
3.2.1.4 语义分析
最后,我们将在查看统计方法之前简要讨论语义分析。请回想一下,当我们需要处理文本时,首先要对文本进行预处理,将文本分解为词语和句子。接下来进行词法分析,在此过程中我们将具有相同词根标记(即词元)的各个词语归为一组。句法分析使我们能够确保文本遵循一定的语法结构,从而可以成为某种语言的合法组成部分。还要记得,大多数语言都可以通过这种方法进行处理,但少数语言(如中文和泰语)在分词和词形还原过程中会遇到困难。完成上述步骤后,我们需要确认所写的句子是否传达了有意义的内容。除了在句法分析中的例子中有一个句子被归类为无意义语句之外,请考虑以下句子:
我正在下去
我感到情绪低落
我正在往下走
这三个句子可以有不同的理解。此外,第一句和第三句可能意味着这个人要下楼,或者如果此前讨论过流感症状,第一句可能意味着这个人即将患上流感(回想一下上下文有关文法,其中文本需要文本历史)。它也可能表示一名选手提到他/她可能会输掉比赛。总之,可以推断出任何给定的句子都可能传达多种含义。语言学过去一个世纪见证了众多理论的涌现,这些理论成为计算机科学家/计算语言学家工作的基础。尽管在此详尽涵盖所有理论超出了本文的范围,我们将简要总结其中四个理论。
- 形式语义学 :形式语义学的关键前提是自然语言和人工语言之间没有区别。两者都可以表示为一组规则,并且基于这些规则我们可以进行推理。例如,考虑以下规则:
每个人都是会死的
John 是一个男人
约翰是凡人
这可以用数学方式表示如下:
人-会死
约翰是人
约翰会死
-
认知语义学 :与形式语义学相反,认知语义学者相信交流中的直觉/心理层面。换句话说,他们认为每个句子都具有传递信息的直觉层面。例如,“He is going down”可以被理解为生病了,或是向下走的物理动作。这种差异取决于上下文/直觉。此外,不同的文化可以为不同的句子增添意义。
-
词汇语义学 :词汇语义学研究单个词素的意义以及由这些词素引发的意义。词素可以带有后缀和词缀,这些后缀和词缀会改变单词的个别意义。此外,单个词素可能具有与之相关的感官意义。例如,以下句子在语法上是正确的,但第二个句子不会被视为正确的句子。
猫追赶了一只老鼠
老鼠追逐了一只猫
- 组合语义学 :组合语义学不关注词素的单独含义,而是关注句子是如何构成的。例如,一个句子可以由名词短语(NP)或动词短语(VP)构成。因此,以下两个句子将被视为正确:
杰克是个男孩
J 是 B
上述观点的关键前提是,除去词汇部分,剩下的就是组合规则。
在预处理和分词阶段,传统的文本处理方法能够产生较好的结果。然而,从上述示例可以推断,句法分析和语义分析阶段的任务复杂性显著增加。这促使了自然语言处理中统计方法的兴起,本文稍后将对此进行讨论。然而,理解上述概念对于掌握和实现统计方法至关重要。
3.2.2 统计方法——关键概念
正如我们在上一节中所看到的,传统方法在进行句法和语义分析时面临诸多挑战。统计方法的提出受到机器学习方法的启发。简单来说,机器学习方法选取一部分数据,研究输入与输出背后的结构和行为特征。具体而言,该过程旨在找到将给定输入转换为期望输出的最佳方式,这被称为“监督学习”。用于监督学习的数据称为训练数据集。一旦发现算法,便将其应用于新的数据集——测试数据集,以检验算法的有效性。这一过程被称为“无监督学习”。尽管上述过程背后存在许多复杂性,但以下概念描述了该方法中的关键思想。
3.2.2.1 语料库及其复杂性
尽管语料库有多种定义,我们选择了以下来自(辛克莱,1991)的定义:
一组自然发生的文本,用于描述一种语言的状态或变体
对于自然语言处理而言,文本需要是机器可读的,以便进行标注。自然语言处理中的标注过程会对文本中的各个词语添加称为元数据的特殊标签——具体细节将在后面的章节中详细描述。
几十年来,研究人员为我们提供了许多语料库。这些语料库包括布朗语料库(马库斯、马钦凯维奇和桑托里尼,1993)、英国国家语料库(阿斯顿和伯纳德,1998)以及英语国际语料库和谷歌Ngram语料库(林等,2012)。此类语料库使我们免于法律方面的困扰,正如陈等(2016)所指出的那样。然而,鉴于具体任务的不同,语料库的选择至关重要,结果可能具有很强的领域特异性(戈登、范杜尔梅和舒伯特,2009)。直观而言,若有人意图研究英国人群,自然会倾向于使用英国国家语料库以获得更深入的见解。尽管我们已有大量可用的语料库,但仍需持续构建新的语料库。例如,拉朱等(2019b)描述了这一需求建立一个用于心理学和精神病学的语料库。这就引出了一个问题:语料库的关键特征是什么?需要关注的三个方面是大小、平衡性和代表性。
3.2.2.1.1 大小
首先需要回答的问题是,语料库应有多大才能代表所需的文本。由于语料库依赖于抽样,回答这个问题有助于构建能够满足研究人员需求的语料库。虽然直觉上让语料库尽可能大是有道理的,但较小的语料库具有非常重要的作用——进行标注以及研究语法/文本底层结构。因此,如果某人专注于对特定文本进行深入标注和/或研究其语法结构,那么使用过大的语料库将使其工作变得非常困难甚至不可能。粗略地说,大型语料库有助于研究词素的出现情况、它们的频率以及各种词元的搭配(Berber-Sardinha, 2000)。搭配是指某些词语在特定文本中共同出现的现象。例如,当用户输入“I can”时,谷歌补全某些词语如“have”,就是基于对各种查询和语料库的研究。当我们讨论词性标注时,这一点将变得更加清晰。
3.2.2.1.2 平衡性
语料库的平衡性指的是语料库在多大程度上能够代表所研究的语言。甚至在聊天时代缩写词流行之前,人们就会预期口语的文本脚本与书面文本存在显著差异。此外,拥有多种口语方言的语言在不同地区会使用不同的文本表达形式。例如,突尼斯的阿拉伯语社区在词语/词素的选择上会与埃及人有所不同。而特定社区使用的口语词汇进一步增加了复杂性。此外,同一个词素在不同社区中可能具有不同的含义。例如,“unionized”一词可以读作“union-ized”(指工会相关),也可以读作“un-ionized”(指化学中的未离子化)。同样,缩写ROE在金融界会被理解为“股本回报率”,而在军方则会被理解为“交战规则”。可以想象,不同的语料库往往针对不同的领域,因此持续构建语料库的需求始终存在。
3.2.2.1.3 代表性
可以考虑研究或标注一部莎士比亚戏剧的片段,用以展示人们日常对话是如何展开的。显然,这并不能代表我们当今的时代。一个更好的例子是回顾即时通讯刚出现时人们的聊天方式。随着时间的推移,“lol”(哈哈)和“imo”(依我看)等术语已融入日常用语中。那么,一段文本要如何才能持续代表一种语言在一段时间内?需要多久更新一次?这些是在构建语料库时需要牢记的问题。然而,也有一些语料库完全不应被更新。例如,代表20世纪90年代电话通话记录的文本脚本反映了那个十年间的用词选择。另一方面,社交媒体的兴起以及各种术语/缩略词的出现,要求某些语料库必须频繁更新。例如,用于表示各种心理障碍行为的语料库,是否应仅限于调查所选个体的回答?还是应该纳入从大量讨论抑郁症的推文中提取出的词素/词语?对于那些在词典中无法找到但在这些群体中广泛存在的词汇表外词(OOV词),人们又该如何处理?尽管这些问题尚需众多研究人员的审慎探讨,并超出了本教程的范围,但它们凸显了语料库构建与选择在人文、社会科学和医学科学中的重要性。
3.2.2.2 词性标注
到目前为止,我们已经讨论了创建语料库的过程,该语料库将作为我们的训练或测试数据集,或两者兼有。词性标注是一个类似于孩子们在学习语法时所学的过程,即识别他们遇到的单词类型。例如,句子“The dog jumped over the fence”可以被标注如下:
这只 限定词(定冠词)
狗 名词
跳过 动词
越过 介词
这道 限定词(定冠词)
篱笆 名词
让我们做一些观察。首先,尽管上述内容看似简单(一旦我们学会了语法规则),但在自然语言处理中,这个问题要复杂得多,因为许多词语可能具有不同的词性标签。“over”这个词可以是介词(如上所示),也可以是副词(考虑句子“He fell over”)。其次,经过本入门部分前面所述的词形还原过程后,我们会将“jumped”识别为动词。正如我们之前所指出的,针对传统方法的预处理和词法分析过程同样适用于统计方法。第三,在语料库创建中,我们讨论过所有语料库在标注和词性标注方面都特别有用。一个小规模的语料库通常能够相当全面地反映某种语言的规则,因此小规模语料库具有优势(布兰茨,2000年)。我们还将在下一节中讨论标注器的应用,该节将详细探讨标注问题。
词性标注有三种广泛使用的主要流行技术。
- 基于规则的词性标注 :通过手动编写规则进行的基于规则的标注。例如,一条规则可以是名词总是跟在限定词之后。如果考虑到“excuse”这个词既可以被标注为名词也可以被标注为动词时,这一点可能会非常有帮助。现在考虑以下两个句子:
- 这个借口没有被接受
- 该员工未被准假
基于规则的标注器会因此将“excuse”标记为名词。基于规则的标注器的问题在于,它需要对文本进行多次迭代,从而消耗大量的计算时间和空间。为缓解此问题,研究人员采用一种称为马尔可夫模型方法的概率方法。
- 马尔可夫模型词性标注 :马尔可夫模型是概率与统计学中的一个概念,它指出事件并不总是独立的(例如抛硬币,每次结果都与前一次无关)。相反,事件可能与历史有关。马尔可夫模型的最简单形式假设,给定一系列顺序事件 E₁, E₂, …, Eₙ,下一个事件 Eₙ₊₁ 仅依赖于前一个事件。这被称为无记忆性。例如,有人认为,如果一名篮球运动员命中了第一个罚球,那么他命中第二个罚球的概率会提高;相反,如果他错过了第一次投篮,命中第二次的概率就会降低。
回顾基于规则标注的例子,名词出现在限定词之后的概率可以设为1。因此,在第一个句子中,“excuse”将被标注为名词。这在确保句子遵循特定语言的语法规则方面非常有帮助。马尔可夫模型假设有关最后状态的信息是可用的。在某些情况下,可以获得更多的历史信息,例如语音标注中的情况。具体来说,我们可以寻找在句子中高频率出现的其他词语。隐马尔可夫模型是引起研究人员兴趣的数学模型,已有许多变体被尝试和测试,例如可变马尔可夫记忆模型。进一步地,研究人员还会寻找在文档中经常一起出现的词语——这一概念称为搭配。
- 基于特征的词性标注 :语言的某些特征可以进一步辅助标注过程。这类特征是先验已知的,例如专有名词始终为大写。这些特征可能变得相当复杂,长期以来一直是研究人员的研究主题。特征有助于为标注过程提供上下文。例如,单词“Citibank”会提供上下文信息,表明当前文档可能与金融相关。
标注方法有助于自然语言处理从业者获取当前文档的相关信息。元数据可包括作者姓名、主题、出版日期等。无论采用何种标注器(或其组合),词性标注都为自然语言处理从业者提供了重要价值。其中一个应用就是“标注”。
3.2.2.3 树库标注
简单来说,标注过程是对文本语料库中的文本附加元数据信息。多年来,已经开发出许多此类语料库。由布朗大学开发的布朗语料库经过了大量标注,其他许多语料库也是如此。传统的标注工作是手动完成的,但现在越来越多地采用计算方法。现在已有算法可以自动执行标注。回顾句法分析部分可知,文本必须符合特定的语法。尽管传统方法在解决这一问题上的效果有限,但词性标注和树库标注显著提高了语法准确性。
树库标注的关键前提是将句子视为一棵树。该树可以通过成分结构标注或依存关系标注构建(马库斯等人,1993年)。成分结构方法将句子划分为名词短语(NP)或动词短语(VP),如下所示(图3.1)。
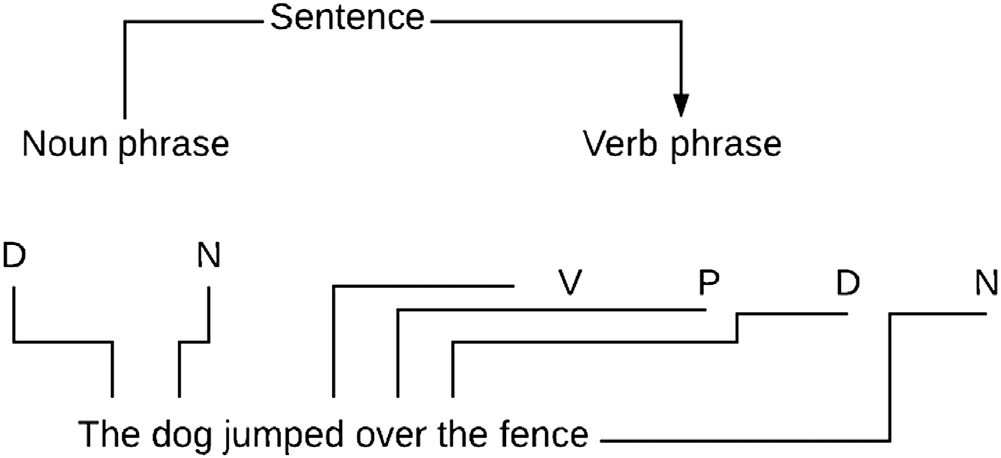
而基于依存关系的标注则侧重于动词,并围绕动词构建树结构。这种方法对于阿拉伯语等某些语言非常有帮助(图3.2)。
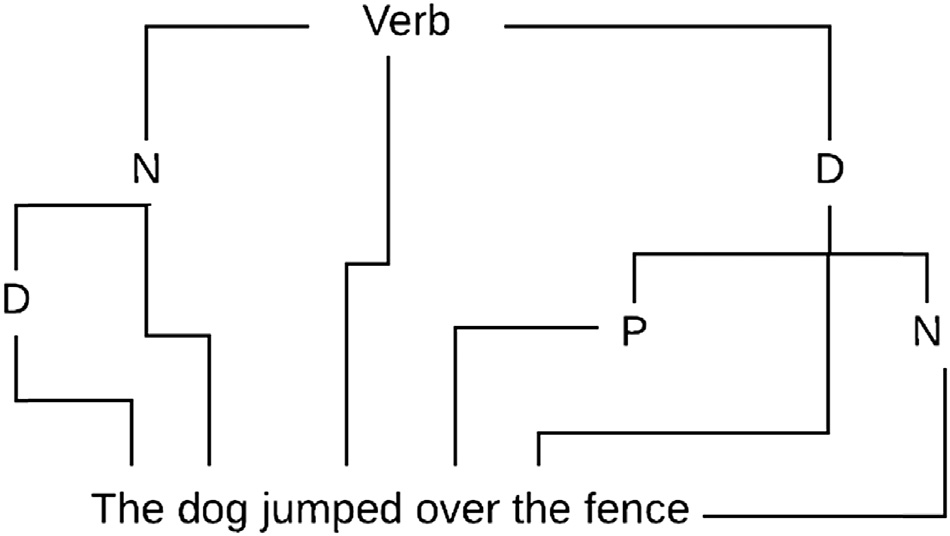
基于成分和依存关系的标注各有优缺点。虽然我们将把这一讨论留待未来其他工作来完成,但树库标注解决了我们在传统方法中遇到的许多语义分析问题。
3.3 应用
由兰德斯、布鲁索、卡瓦纳和科尔默斯(2016)开展的研究提供了一个有助于从网络中提取大数据的框架。作者特别提倡一种“理论驱动”的网络抓取方式,鼓励研究人员在从网络上搜集数据之前先提出问题并建立假设。这可能包括年龄和人口统计特征等各种标准。作者提出了一个案例研究,通过推断性别认同来验证关于女性行为的假设。最后,作者指出了网络爬虫工作的重要性以及应用程序编程接口(API)在大数据领域所起的作用。大多数(如果不是全部的话)社交媒体平台都提供有助于研究人员收集数据的应用程序编程接口(API)。
自然语言处理和情感分析已应用于市场营销等多个领域。然而,社会科学和医学领域才刚刚开始感受到其影响。研究人员最近开始探索如何将大数据技术应用于心理健康问题,例如抑郁症检测。在本节中,我们概述了情感分析以及心理健康问题检测方面的各种应用。
3.3.1 情感分析
情感分析的基本应用在于收集公众意见。这些意见是许多商业决策的前兆。与停用词类似,情感分析领域依赖于描述作者情感的词汇表。Nielsen (2011) 解释了如何使用 ANEW 词表将用户意见分类为负面、中性或正面。王、魏、刘、周和张(2011)将情感分析的概念应用于话题,而非实际意见,并揭示了讨论将如何跟随话题的情感走向。
庞和李(2008)还研究了用户评论以及在提供评分时数据录入过程中可能出现的错误。戈德堡、朱和赖特(2007)和霍普金斯和金(2007)研究了民主党选民的意见以及他们对总统选举的感受。班萨尔、卡迪和李(2008)研究了政治领域中情感分析的长期方面,选民可以据此长期了解政治家在任期内的行为表现。其他项目则以明确政治家立场为长期目标。
金、李、马和唐(2007)应用情感分析概念来检测不当广告。张和李(2011)研究了如何查找与恐怖主义相关的内容,该工作关注了平民的情绪以及如何通过采集推特数据来获取此类信息。在推特数据采集领域,阿加瓦尔、谢、沃夫沙、拉姆博和帕松诺(2011)、赛夫、何和阿拉尼(2012),以及罗森塔尔、法拉和纳科夫(2017)对此进行了更多研究。推特数据还被用来构建特定于推特的语料库,如帕克和帕鲁贝克(2010)所述。最后,科布、梅斯和格雷厄姆(2013)将情感分析应用于戒烟技术,基于某些药物选择。
3.3.2 自然语言处理在医学科学中的应用
游游、科辛斯基和斯蒂韦尔(2015)的研究聚焦于脸书平台,作者在该平台上将人类的感知与从社交媒体中获取的感知进行比较。具体而言,作者通过用户点击的“点赞”数量来判断用户的判断力。另一方面,他们建立了两个包含超过14,000名用户的样本,并要求这些用户的朋友对用户的判断力进行评分。结果显示,从脸书点赞中获取的结果更为准确。这一结果再次为研究人员提供了证据,表明从社交媒体中获取的信息既具有价值又具备准确性。但该结果并未反映用户在不同网站或项目上的评论,而这些评论可能使结果更加准确。此外,该过程未涉及任何语料库。在此方面,可借鉴拉朱等(2019b)的研究成果。
陈和沃伊契克(2016)的工作概述了大数据在心理学中的应用。作者重点关注了实现此类工作的四个必要步骤,即规划、获取、规划和分析。他们还为用户提供了三个教程。他们向用户介绍了近期备受关注的 MapReduce 框架。本文还解释了如上所述的监督学习和无监督学习的概念。尽管这项工作提供了出色的概述,但确实忽略了一些用户可能需要的细节。特别是,他们只是简要提及了数据处理中的预处理部分以及许多底层细节,例如文本归一化。
韩、库克和鲍德温(2013)的研究集中在未登录词的文本归一化上。具体而言,用户针对“smokin”等词语,并找到一种机制将其转换为“smoking”。该研究主要关注短信,同时也深入探讨了推特上的较大样本量。作者提出的方法与来自纽约时报的语料库相比,取得了非常令人鼓舞的结果。未登录词首先通过基于词典的匹配进行归一化,然后根据结果,作者进一步在上下文环境中进行测试。拉朱等(2019b)展示了心理学/精神病学背景下的研究成果——特别是抑郁症。作者未探究的问题之一是将未登录词的同义词转换为实际的基于词典的词语——例如将“imo”转换为“in my humble opinion”。戈登等人(2009)也采用了类似的归一化方法,其中作者为网络日志构建了一个归一化词典。这项工作为博客预处理提供了极佳的方法——博客是另一种社交媒体平台。该工作并非特定领域,因此其思想可应用于更具领域针对性的上下文环境。
斯坦福大学(科辛斯基、王、拉卡尔朱和莱斯科维奇,2016)开展的研究着眼于用户的数字足迹以及两种分析数据的数学方法。该研究基于 R 语言(而非 Python),有助于预测现实生活结果。该研究属于无监督学习领域,并以脸书数据作为案例研究。尽管这项工作并未专注于医学/社会科学领域,但它对用户的数字足迹提供了出色的介绍,并可在检测各种病症的特定症状时发挥重要作用。
德乔杜里等人在检测精神疾病方面做了一些工作。作者们最初的研究重点是检测产后抑郁症。他们选择 Reddit 作为研究平台,分析了新晋母亲的语言变化。他们展示了某些情况下负面情绪的普遍存在等结果。这项工作是该领域的出色初步探索,随后由德乔杜里(2013)、德乔杜里、康茨和霍尔维茨(2013)以及德乔杜里、加蒙、康茨和霍尔维茨(2013)继续推进,这些研究预测推特用户中的抑郁症情况。他们工作的先决条件之一是用户自认为抑郁并同意允许追踪其推特账号。该领域下一步应是从随机推文集合中检测抑郁症症状。此外,《精神障碍诊断与统计手册》第五版的指南也应被采纳并与社交媒体文本相匹配。
德乔杜里、夏尔马和基奇曼(2016)还研究了社交媒体的匿名性及其伴随而来的去抑制现象。具体而言,他们关注了用户用于表达观点的“一次性”账户。作者还将更多大数据和机器学习技术应用于营养学领域,利用社交媒体了解社交媒体用户的饮食选择(帕瓦拉纳坦和德乔杜里,2015)。尽管这项工作不直接关联精神疾病,但在诸如进食障碍与抑郁症或双相情感障碍共病等情况中可被广泛应用。拉朱特和艾哈迈德(2019a, 2019b)对大数据在心理健康领域应用的研究现状进行了简要综述。此外,拉朱特和艾哈迈德(2019a, 2019b)提出应建立一个针对心理健康问题的语料库。
萨哈和德乔杜里(2017)在校园枪击事件发生后,对一群大学生的压力状况进行了建模。作者使用 Reddit 校园社区,通过分析学生发布的帖子的语言风格,以检测此类创伤性事件后是否存在高度压力。他们研究了5年内发生的12起枪支暴力事件,并分析了相关帖子的时间和语言维度。这项工作为后续研究提供了良好的基础,可用于探索基于此类数据是否能够进行临床推断。
值得一提的是奥卡拉汉、哈里根、卡西和坎宁安(2012)的研究,该研究选择了 YouTube 平台,并专注于检测评论区中的垃圾信息。作者使用图论与网络理论来分析机器人程序(自动程序)的行为。此类工作可以与其他研究相结合,帮助研究人员对各种来自各种维度的视频。一旦完成此类分类,研究人员就可以查看嵌入的评论,并将内容与用户的心理状态及其表达方式联系起来。
尽管上述研究是从心理学角度进行分析的(也适用于精神病学的临床部分),蒙特思、格伦、盖德斯和鲍尔(2015年)提出了一份正在进行的精神病学领域项目清单。作者从医学科学的角度审视大数据领域,并强调大数据在临床环境中如何提供益处,例如精确定位罕见事件。该领域的研究工作范围广泛,从精神类药物的使用到比较特定年龄组的痴呆风险。
3.4 结论
情感分析和自然语言处理为心理健康从业者提供了绝佳的机会,使其能够从网络上挖掘文本数据,并检测可能预示各种心理健康问题的症状。在本章中,我们详细概述了自然语言处理和情感分析。此外,我们简要综述了 Python 语言和 NLTK 工具包的优势。最后,我们介绍了情感分析领域的多种应用以及自然语言处理在医学领域的应用。未来,作者希望将情感分析应用于心理健康疾病(如网络欺凌和抑郁症)的检测。
3.4.1 未来研究方向
首先,社交媒体(阿尔卡马什, 尤西拉, 利特拉斯, & 维斯维齐, 2019年)为心理健康从业者提供了最佳的数据来源。这些数据由真实用户生成,而互联网提供的匿名性使从业者能够收集到真实数据,从而获得关于患有精神疾病患者的心理状态的有价值的见解。
社交媒体允许患者使用其首选语言发布评论。此类数据应进行分类和比较,以查看不同文化背景的患者之间是否存在共性。例如,一个有趣的研究问题是:美国和阿拉伯语国家中患有抑郁症的用户所报告的抑郁症潜在驱动因素是否相同?
此外,尽管英语仍是互联网上大多数用户的首选语言,但人们撰写评论的方式存在细微差异。因此,一个有趣的研究方向是探讨如何根据英语使用者的文化和地理背景对其进行区分,并揭示其中的差异。例如,来自印度和巴基斯坦的用户与来自英国的用户表现出的症状是否相同?
最后,另一个值得研究的方向是能够从社交媒体发帖用户中获取其社会经济地位(SES)。SES 是医疗保健从业者用于预测各种疾病发生的重要信息。SES 的一个方面是发帖用户的教育水平。智慧医疗的干预措施和应用需要与智慧城市战略相匹配,并深入理解用户群体(利特拉斯, 维斯维齐, & 萨里雷特, 2019年)
3.4.2 教学任务
- 对网络欺凌相关研究进行文献综述,并分析情感分析和自然语言处理技术如何提供帮助。
- 对可用于评估不同用户写作风格的各种技术进行文献调研。
- 研究谷歌提供的二元语法和三元语法数据,以及其在医疗保健分析领域的应用价值。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









