




 介绍了一种适用于永磁电机驱动的纯电动大巴车的坡道起步防溜策略,该策略通过控制永磁电机输出力矩实现车辆防溜,无需改变车辆结构或增加额外硬件。
介绍了一种适用于永磁电机驱动的纯电动大巴车的坡道起步防溜策略,该策略通过控制永磁电机输出力矩实现车辆防溜,无需改变车辆结构或增加额外硬件。
文本:
'永磁电机驱动的纯电动大巴车坡道起步防溜策略 本发明公开了一种永磁电机驱动的纯电动大巴车坡道起步防溜策略,即本策略当制动踏板已踩下、永磁电机转速小于设定值并持续一定时间,整车控制单元产生一个刹车触发信号,当油门踏板开度小于设定值,且档位装置为非空档时,电机控制单元产生一个防溜功能使能信号并自动进入防溜控制使永磁电机进入转速闭环控制于某个目标转速,若整车控制单元检测到制动踏板仍然踩下,则限制永磁电机输出力矩,否则,恢复永磁电机输出力矩;当整车控制单元检测到油门踏板开度大于设置值、档位装置为空档或手刹装置处于驻车位置,则退出防溜控制,同时切换到力矩控制。本策略无需更改现有车辆结构或添加辅助传感器等硬件设备,实现车辆防溜目的。',
'机动车辆车门的肘靠 一种溃缩结构是作为内部支撑件而被提供在机动车辆的车门衬板上的肘靠中,所述溃缩结构具有多个以交叉形方式设计的凹陷,其中被一个装饰层覆盖的一个泡沫元件安排在所述溃缩结构上方。该溃缩结构特别用于吸收侧面碰撞事件中的负荷,以便防止车辆乘车者免受增加的力峰值。',
'仪表板支撑结构 本发明公开了一种支撑结构,其配置用于在车辆的乘客车厢内定位仪表板。所述支撑结构包括支撑支架和端部支架。所述支撑支架附接到所述车辆的车身面板。所述支撑支架包括横向偏压导引件。所述端部支架附接到所述仪表板的一端。所述端部支架具有第一侧面。所述第一侧面邻接所述支撑支架的横向偏压导引件,以使得所述横向偏压导引件沿横向方向偏压所述仪表板,直到所述端部支架邻接所述第一车身面板的横向基准表面。',
'铰接的头枕总成 一种车辆座椅总成,包括座椅靠背、头枕和支承结构,支承结构在头枕和座椅靠背之间延伸。支承结构包括主要构件、次要构件和包围主要和次要构件的装饰件。主要构件与头枕和座椅靠背枢转地联接。次要构件具有上端和下端。上端围绕着横轴线与头枕枢转地联接并且与主要构件间隔开。第一驱动器在主要构件和座椅靠背之间与二者联接,以在后部位置和前部位置之间旋转头枕。第二驱动器联接在次要构件的下端和座椅靠背之间,以在第一角度和第二角度之间移动头枕。',
'用于评估和控制电池系统的系统和方法 本发明涉及用于评估和控制电池系统的系统和方法。介绍了用于估计电池系统中的各独立电池分部的相对容量的系统和方法。在一些实施例中,系统可包括构造成分析电参数的计算系统,以产生在一段时间期间的参数的导数值。计算系统还可基于导数值计算与独立的电池分部相关联的总和值。电池控制系统可利用总和值,以产生构造成利用总和值控制电池组的操作的一个方面的一个或多个命令。根据一些实施例,与电池分部相关联的总和值可用于确定用于存储电能的相对容量。相对容量的确定可由控制系统使用,以防止具有最低储能容量的电池分部的过放电。',
'侧气囊装置 本发明公开了一种侧气囊装置,其中,横向分隔件由一对结构织物部形成,各结构织物部具有第一周边部和第二周边部。结构织物部的第一周边部各自与主体织物部之一结合。由沿第二周边部设置的结合部,使结构织物部的第二周边部互相结合。内管延伸越过上膨胀室和下膨胀室,同时与横向分隔件相交。由周边结合部的一部分,使内管一部分的后周边部与主体织物部结合,以及,由结合部使该部分的前周边部与结构织物部结合。',
'制造气囊的方法 本发明公开了以下方式制造气囊。在第一结合步骤中,使各结构织物部中安装时被引到更靠近于主体织物部的周边部与摊开状态下的主体织物部结合。在第二结合步骤中,使没有重叠到结构织物部上的部分与主体织物部结合,以及,使重叠到结构织物部上的部分只与结构织物部结合。在第三结合步骤中,使结构织物部中在安装时远离主体织物部的周边部互相结合。',
'上部椅背枢轴系统 一种车辆座椅总成,其包括第一和第二侧支承部,该第一和第二侧支承部限定了椅背结构,该椅背结构在竖直和斜倚位置之间可操作。一机动化的驱动总成被设置在第一和第二侧支承部之间并可操作地耦接至枢轴杆,该枢轴杆与椅背结构可旋转地耦接。一上部椅背悬挂组件被耦接至枢轴杆。当椅背结构处在竖直位置时,该上部椅背悬挂组件相对于枢轴杆自动地向后部向位置枢转,且当该椅背结构处在斜倚位置时,该上部椅背悬挂组件相对于枢轴杆自动地向前部向位置枢转。一种外周间隙被限定在上部椅背悬挂组件和椅背结构之间。',
'用于在机动车的行驶过程中关闭和启动内燃机的方法 本发明描述了一种用于在具有手动变速器的机动车的行驶过程中关闭和开启内燃机的方法,该方法具有以下方法步骤:首先在机动车速度> 0且满足在手动变速器中的空挡条件时开始所述方法。随后关闭机动车的内燃机。之后在内燃机停转状态下的无驱动运行模式下继续行驶。在内燃机的停转状态下监测启动发生器,并在启动信号发生器被操作时开始重启内燃机。',
'半倾斜货箱卸载系统 本发明涉及半倾斜货箱卸载系统。一变型可包括一种产品,包括:运输工具,其包括具有倾斜部分和非倾斜部分的货箱,该运输工具具有第一纵向侧和相对的第二纵向侧,倾斜部分被构造和布置成使其最靠近第二纵向侧的一侧可相对于其最靠近第一纵向侧的相对侧降低。一变型可包括一种方法,包括:提供包括具有倾斜部分和非倾斜部分的货箱的运输工具,该运输工具具有第一纵向侧和相对的第二纵向侧,倾斜部分被构造和布置成使其最靠近第二纵向侧的一侧可相对于其最靠近第一纵向侧的相对侧降低,货箱具有前部和后部,倾斜部分最靠近货箱的前部,非倾斜部分邻近倾斜部分;将货物从货箱的后部装载到货箱上;以及将货物从货箱卸载,包括使货箱的倾斜部分倾斜。'结果图:
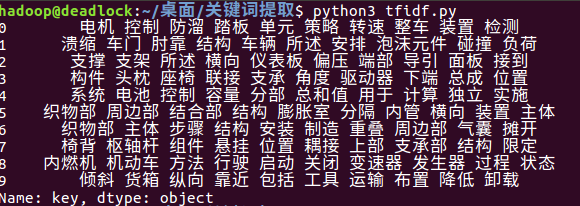
分词工具:ltp,另外自己封装了LtpLanguageAnalysis()用于分词且得到词的词性
from ltp import LtpLanguageAnalysis
import pandas as pd
import codecs
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
import numpy as np
data_path = 'sample_data.csv'
def PrepareData(text,stopword):
ltp = LtpLanguageAnalysis()
result = []
pos = ['a','i','j','n','nh','ni','nl','ns','nt','nz','v']
words = ltp.analyze(text)
for word,tag in words:
if word not in stopword and tag in pos:
result.append(word)
return result
def TfIdf(data,stopword,topK):
id_list,title_list,abstract_list = data['id'],data['title'],data['abstract']
corpus = []
for i in range(len(id_list)):
text = '%s。%s' % (title_list[i],abstract_list[i]) #拼接
text = PrepareData(text,stopword) #分词去停词和词性
text = ' '.join(text) #连接成字符串
corpus.append(text) #导入语料库
vectorizer = CountVectorizer() #定义类
tf = vectorizer.fit_transform(corpus) #构建词频矩阵, a[i][j],表示j词在i文档中的词频
tranfromer = TfidfTransformer() #定义类
tfidf = tranfromer.fit_transform(tf) #统计每个词的tf-idf权值
word = vectorizer.get_feature_names() #获取词袋模型中的关键词
weight = tfidf.toarray() #获得tf-idf权值矩阵,a[i][j]表示词j在i篇文本中的tfidf权重
keys = [] #用于保存关键字,以输出
for i in range(len(weight)): #文档个数
df_word = pd.DataFrame(word,columns=['word'])
df_weight = pd.DataFrame(weight[i],columns=['weight'])
word_weight = pd.concat([df_word,df_weight],axis=1) #获取词与权重对应关系
word_weight = word_weight.sort_values(by='weight',ascending=False) #根据权重进行排序
keyword = np.array(word_weight['word']) #转换成关键词矩阵
word_split = [keyword[x] for x in range(0,topK)] #取得topK个词
word_split = ' '.join(word_split)
keys.append(word_split)
result = pd.DataFrame({"id": id_list, "title": title_list, "key": keys},columns=['id','title','key'])
return result
if __name__ == '__main__':
data_set = pd.read_csv(data_path) #读入数据
stop_word = [w.strip() for w in codecs.open('stopword.txt','r').readlines()] #读入停用词
result = TfIdf(data_set,stop_word,10) #关键词个数
print(result['key'])
result.to_csv('result_idtif.csv')
















 1558
1558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









