




现在我们每天都要收发很多电子邮件。有的是朋友发来的问候,有的是工作伙伴的沟通,还有的可能是那些我们不想要的广告或垃圾邮件。这么多邮件,怎么看过来呀?其实,有一个好工具叫“邮件过滤”,它就像你的私人助手,帮你把邮件分分类,让你只看你想看的。而邮箱过滤到底是什么?怎么设置邮箱过滤呢?小编将为您详细解释。
一、邮件过滤是什么?
简单来说,电子邮件就是在你的电子邮件中安装一个“聪明的大脑”。这一大脑会根据你告知它规范自动将电子邮件分为不同的类型。邮件过滤可以帮助我们在工作中自动分类工作邮件,在生活中也能帮我们屏蔽掉购物广告等。
1、垃圾信息屏蔽
垃圾信息屏蔽是邮件过滤最基础也最实用的功能之一。你是否曾经因为注册了某个网站的会员,而频繁收到其推送的营销信息?
这时,通过邮件过滤功能,我们只需设定相关的关键词或域名,就能轻松将这些信息屏蔽掉,让邮箱重回清净之地。
2、重点信息的分类
对于工作中我们常进行交流的合作伙伴,我们可以根据他们的企业邮箱域名,也就是他们邮箱的后缀,来设置下,将他们公司域名的邮件都自动归档到重点文件夹或者是直接命名为客户文件夹。
这样之后,邮箱系统都将会为我们自动分类,以便我们在处理工作时优先处理重要的信息。
3、邮件信息自动共享
邮件过滤可以让我们根据发件人或者关键词来将这类邮件直接转发给其他的处理人。比如客户的重要信息,如果我们需要及时共享给自己团队里的同事,那么我们除了采用共享文件夹的形式外,还能够通过邮件过滤的形式直接转发。
这种方式不仅便捷高效,还能确保信息在团队内部得到及时、准确的传递。
二、如何设置邮件过滤?
上面我们说了邮件过滤是什么?以及给我们工作带来的几大功能,那么我们如何进行邮件过滤呢?接下来我们就以Zoho Mail企业邮箱为例来具体展示下如何进行邮件过滤设置。
1、垃圾信息的屏蔽
a.进入到个人主页后,点击右边的设置,进入到我们的邮件设置页面
b.在左侧找到并选择“过滤器”,进入到过滤器设置页面
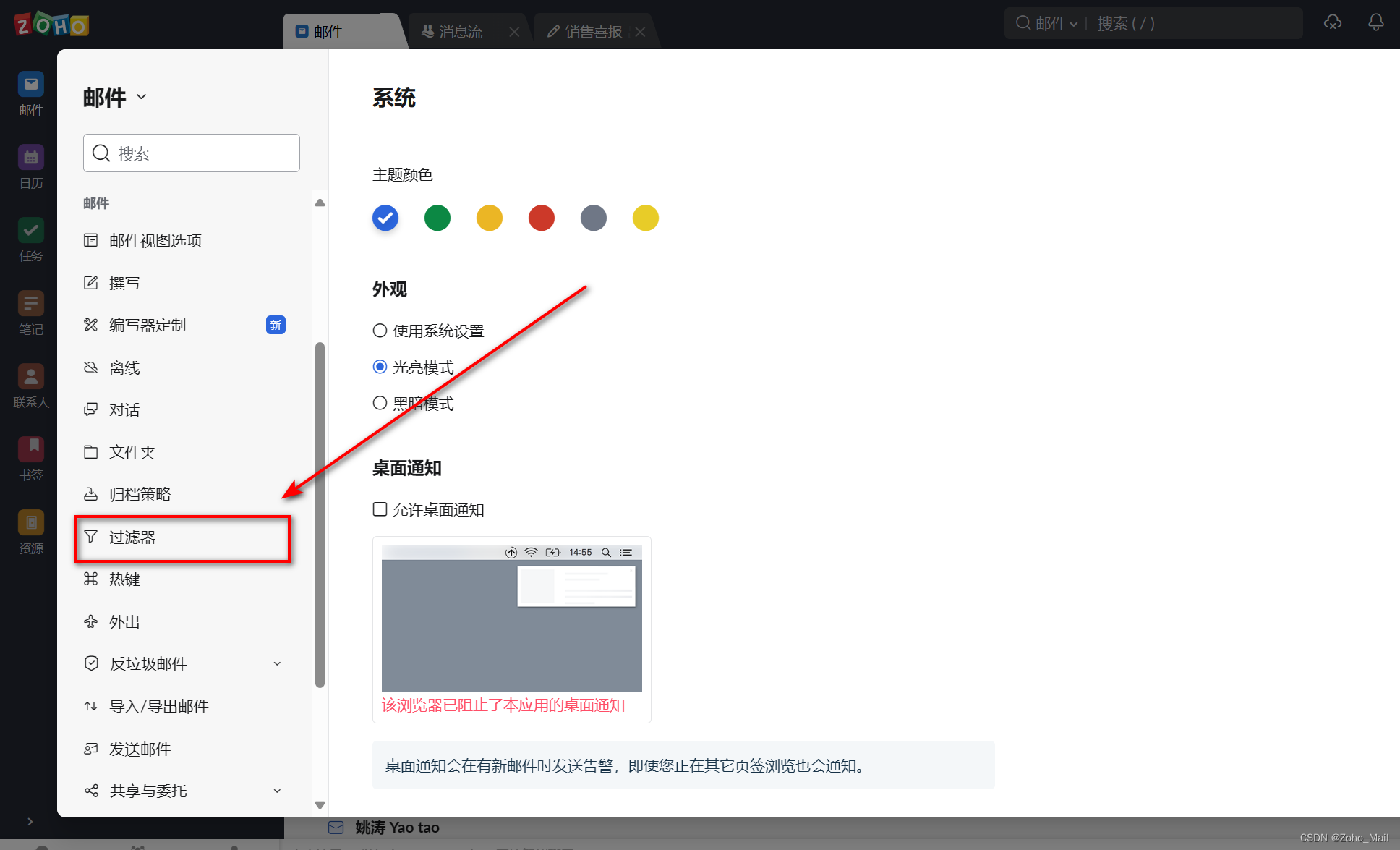
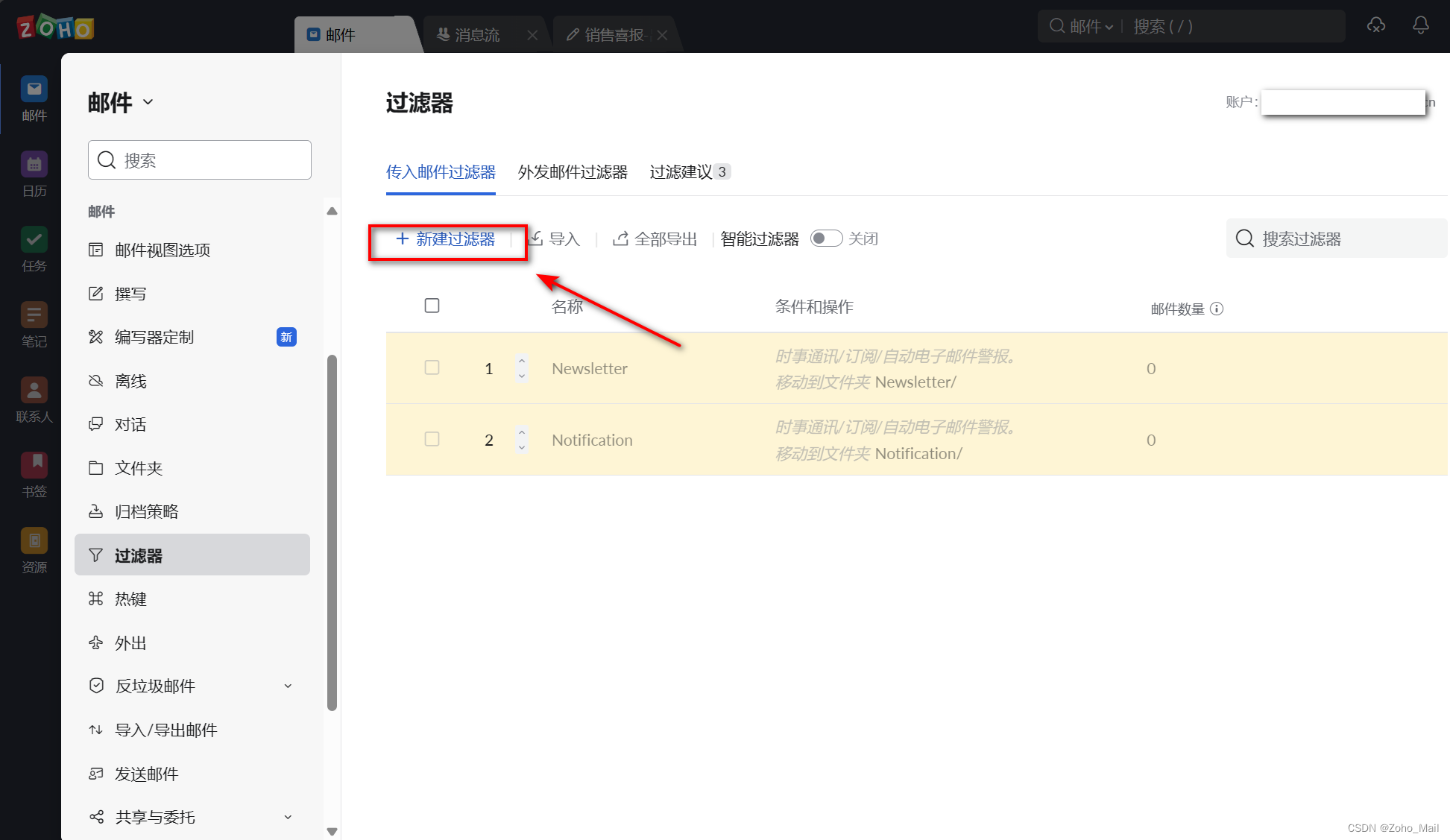
c.点击“新建过滤器”,我们可以根据自己的需求来命名,比如“垃圾信息过滤”
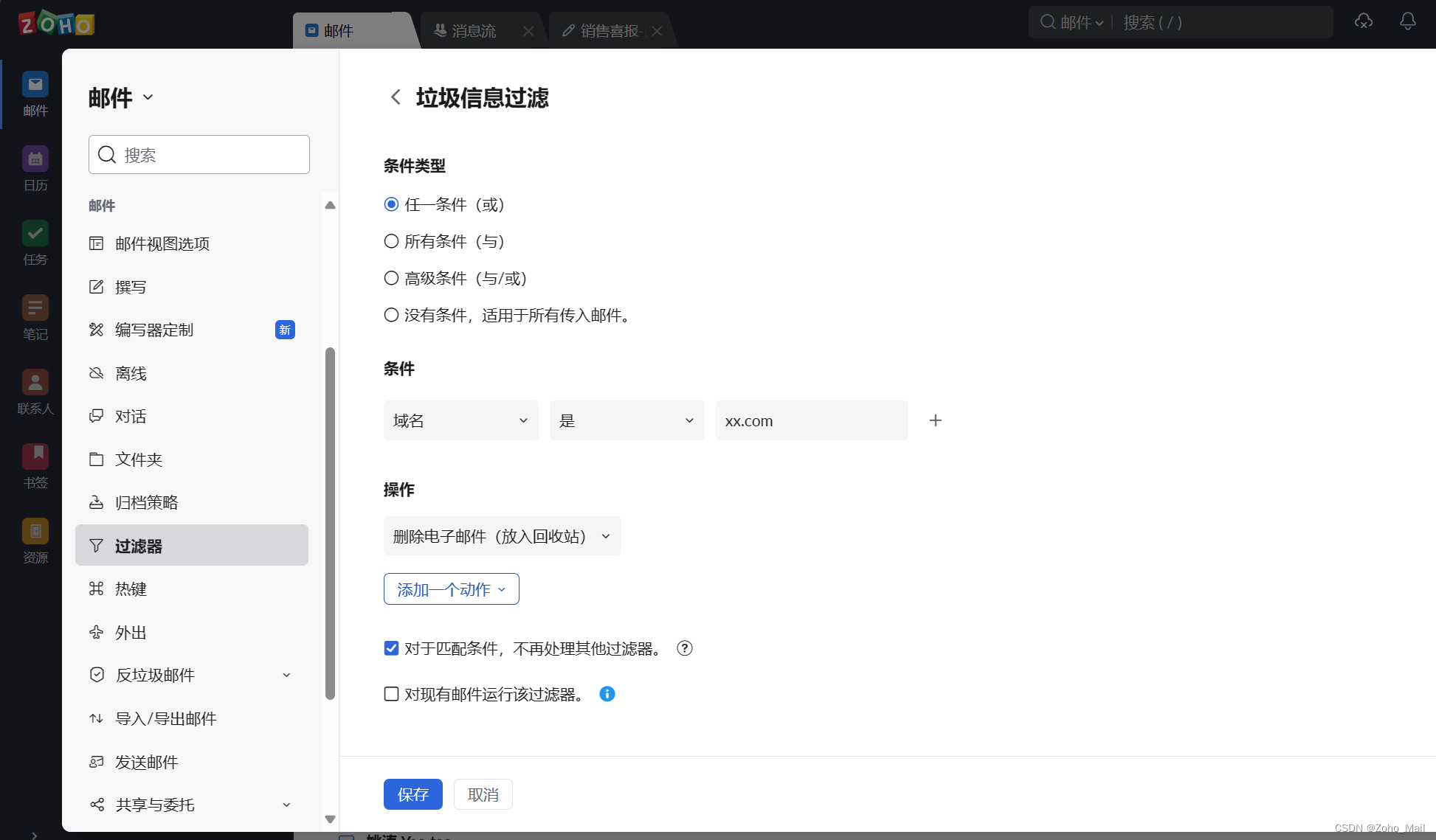
d.选择“域名”过滤,再后方填写上我们要过滤的域名地址
e.接着,在操作那栏,我们选择自己想要的操作内容,比如删除电子邮件(放入垃圾邮件中)
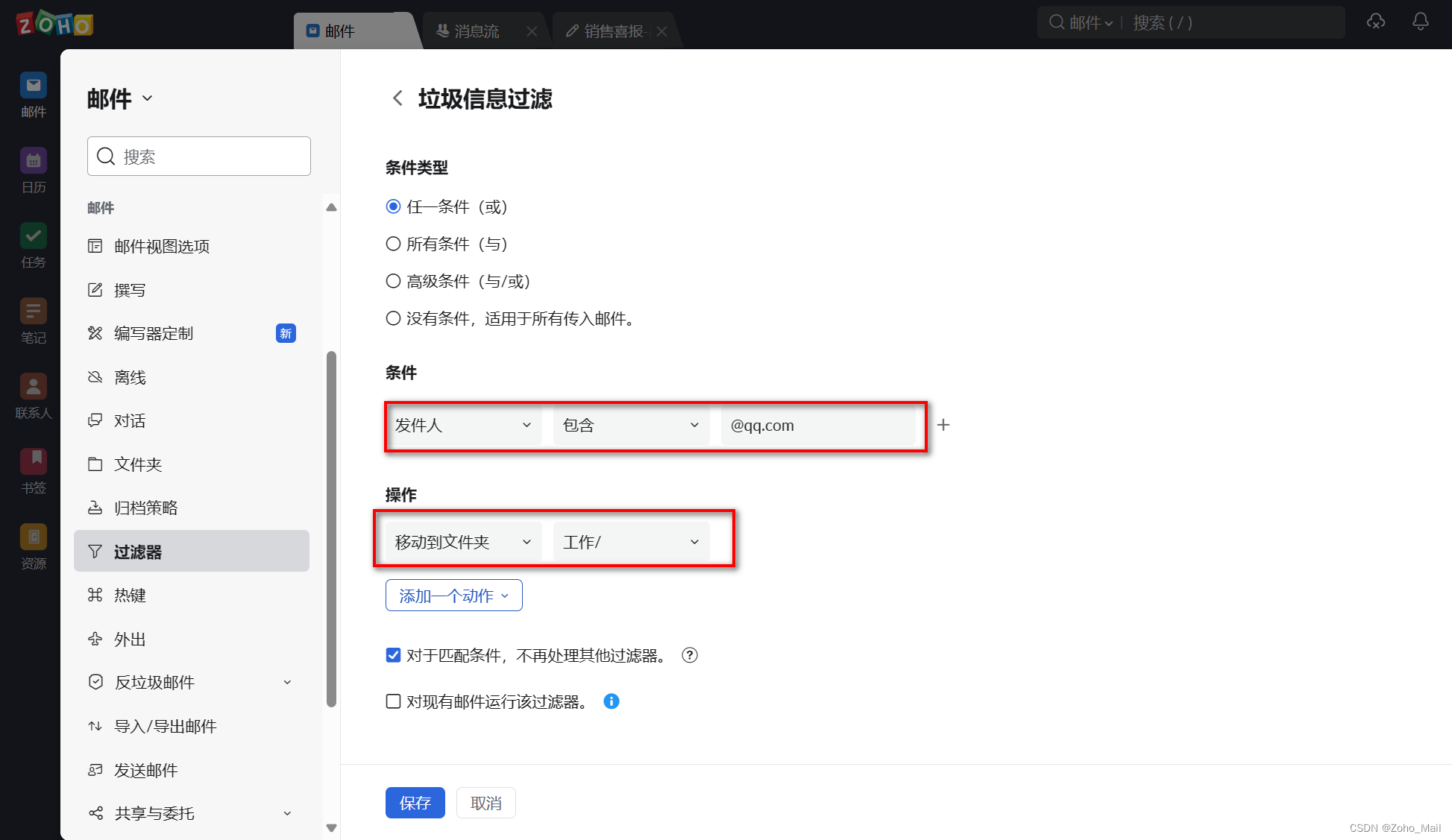
2、重点信息的分类
我们先重复上面步骤的a和b,然后在新建过滤器中重新进行操作
a.可以根据发件人来筛选,选择发件人后在后方的邮件地址里可以具体得选择发件人对象,可以添加多个发件人。
b.在操作那栏,选择“移动到文件夹”,接着选择指定的文件夹即可,若是没有对应的文件夹,我们可以先去进行创建。
3、邮件信息自动转发
同理,我们可以选择好发件人或者是填写好相应的邮件主题后,
在操作栏那里,我们选择“将电子邮件转发给”,然后选择对应的收件人即可。

邮件过滤作为现代电子邮件管理的有效途径,不仅可以帮助大家屏蔽无用的垃圾信息,还能够筛选和自动转发重要电子邮件,大大提升了大家工作效率。
通过本文的介绍,相信大家对邮件过滤有了更全面的了解。Zoho Mail企业邮箱不仅有强大且易用的邮件过滤功能,还有域名管理和消息流等功能。
常见问题
1、邮件过滤会误删我的重要邮件吗?
电子邮件过滤作用是基于用户设定标准。只需规范设定恰当,重要电子邮件就不会被误删。建议用户定期查看过滤标准,并根据需要作出调整,以保证邮件过滤的准确性。
2、我可以设置多个邮件过滤规则吗?
是的,你可以根据自己的需求在Zoho Mail企业邮箱中设置多个邮件过滤规则。这些规则会按照你设定的顺序进行执行,以便更好地满足你的邮件管理需求。
3、如果我更换了邮箱服务商,之前的邮件过滤规则还能用吗?
不同的邮箱服务商可能有不同的邮件过滤规则设置方式,因此更换邮箱服务商后,之前的规则可能无法直接迁移。不过,你可以根据新的服务商提供的设置选项,重新创建和调整邮件过滤规则。


















 1904
1904

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









