







希尔排序
希尔排序这个名字,来源于它的发明者希尔,也称作“缩小增量排序”,是插入排序的一种更高效的改进版本。
我们知道,插入排序对于大规模的乱序数组的时候效率是比较慢的,因为它每次只能将数据移动一位,希尔排序为了加快插入的速度,让数据移动的时候可以实现跳跃移动,节省了一部分的时间开支。

希尔排序动画演示
图解希尔排序
待排序数组 10 个数据:
希尔排序1
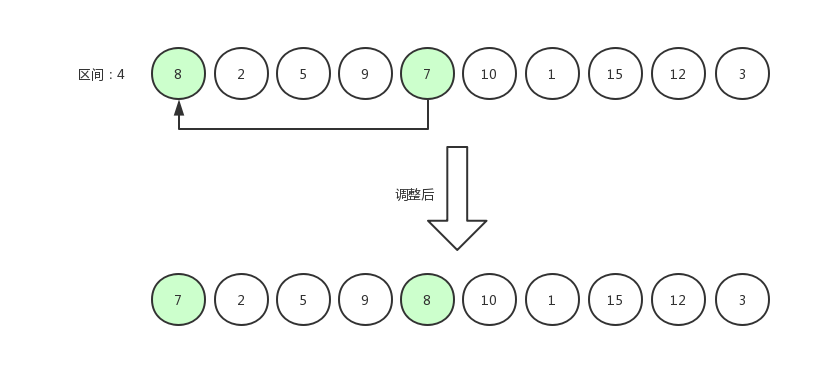
假设计算出的排序区间为 4 ,那么我们第一次比较应该是用第 5 个数据与第 1 个数据相比较。
希尔排序2
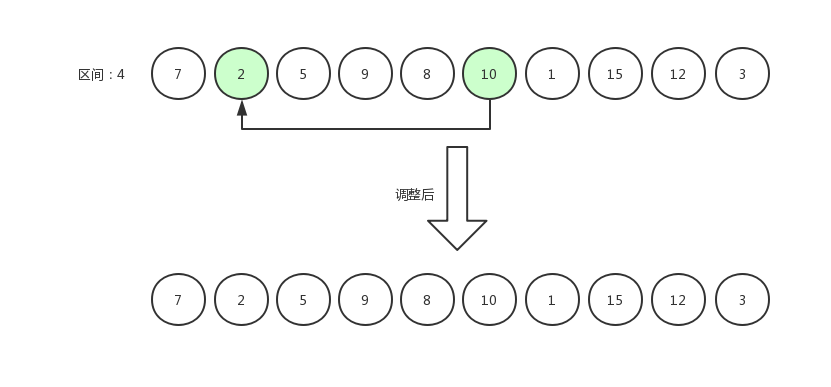
调换后的数据为[ 7,2,5,9,8,10,1,15,12,3 ],然后指针右移,第 6 个数据与第 2 个数据相比较。
希尔排序3
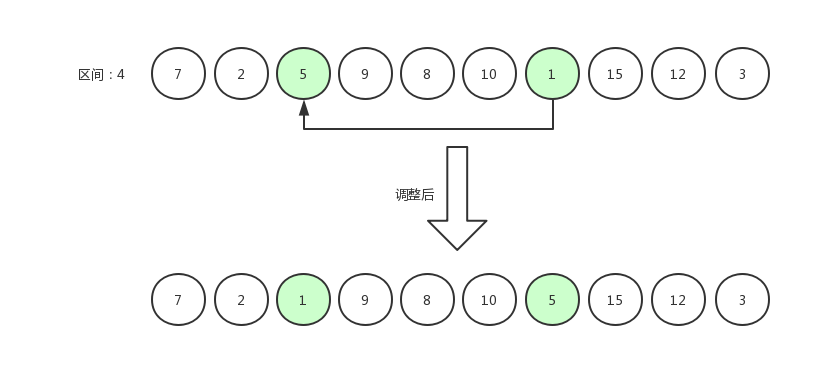
指针右移,继续比较。
希尔排序4
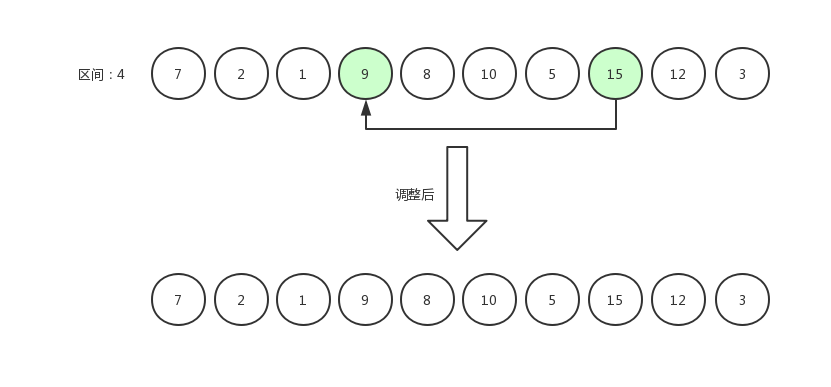
希尔排序5
如果交换数据后,发现减去区间得到的位置还存在数据,那么继续比较,比如下面这张图,12 和 8 相比较,原地不动后,指针从 12 跳到 8 身上,继续减去区间发现前面还有一个下标为 0 的数据 7 ,那么 8 和 7 相比较。
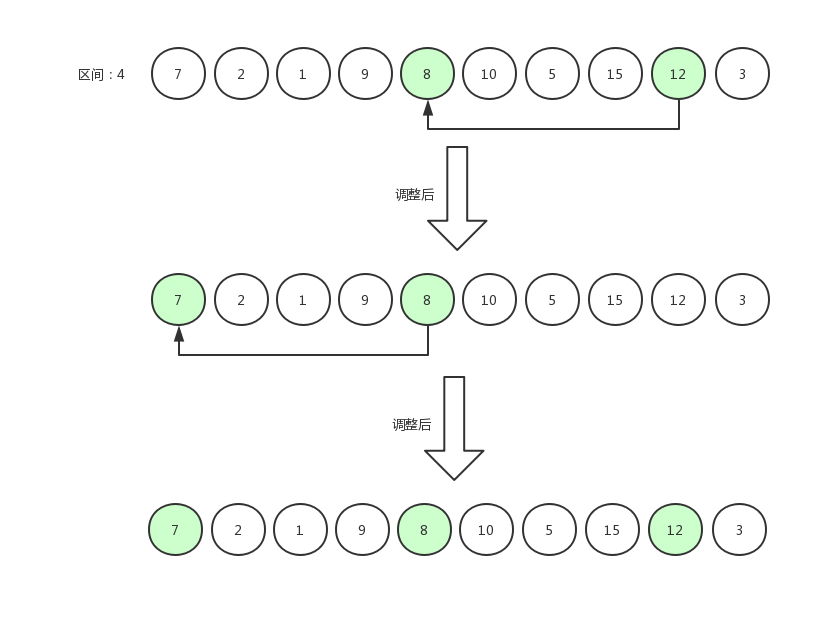
希尔排序6
比较完之后的效果是 7,8,12 三个数为有序排列。
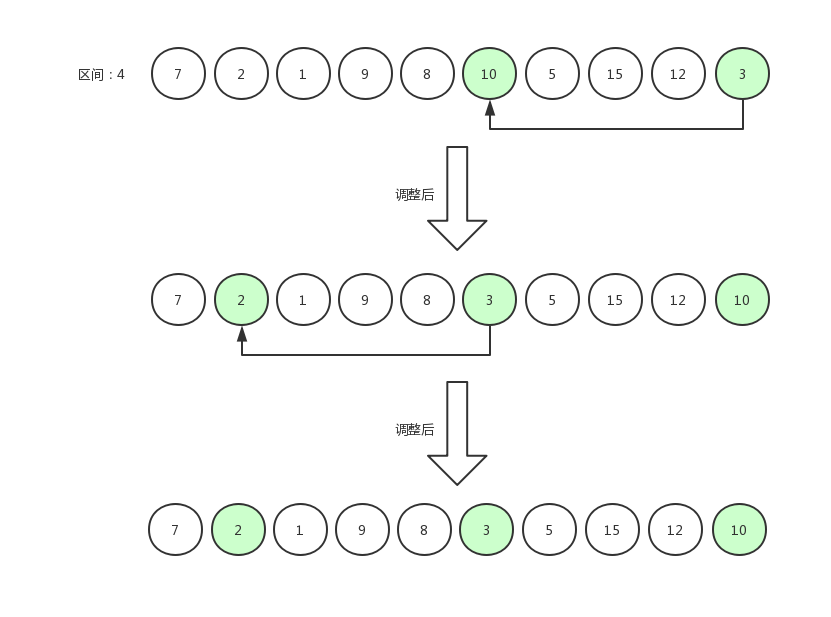
希尔排序7
当最后一个元素比较完之后,我们会发现大部分值比较大的数据都似乎调整到数组的中后部分了。
假设整个数组比较长的话,比如有 100 个数据,那么我们的区间肯定是四五十,调整后区间再缩小成一二十还会重新调整一轮,直到最后区间缩小为 1,就是真正的排序来了。
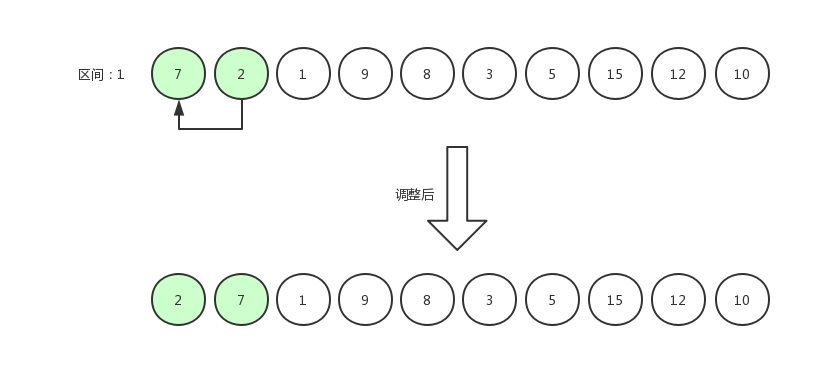
希尔排序8
指针右移,继续比较:
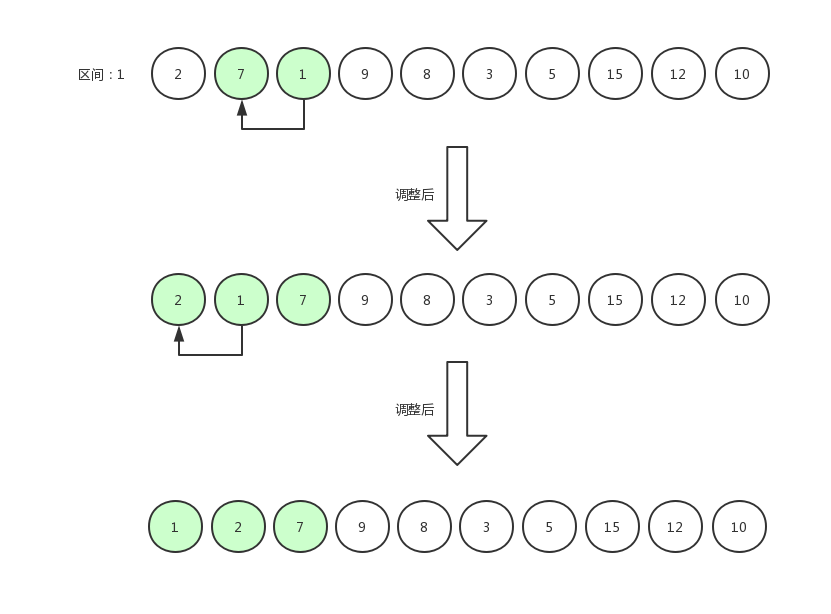
希尔排序9
重复步骤,即可完成排序,重复的图就不多画了。
我们可以发现,当区间为 1 的时候,它使用的排序方式就是插入排序。
代码实现
public static void sort(int[] arr) {
int length = arr.length;
//区间
int gap = 1;
while (gap < length) {
gap = gap * 3 + 1;
}
while (gap > 0) {
for (int i = gap; i < length; i++) {
int tmp = arr[i];
int j = i - gap;
//跨区间排序
while (j >= 0 && arr[j] > tmp) {
arr[j + gap] = arr[j];
j -= gap;
}
arr[j + gap] = tmp;
}
gap = gap / 3;
}
}
可能你会问为什么区间要以 gap = gap*3 + 1 去计算,其实最优的区间计算方法是没有答案的,这是一个长期未解决的问题,不过差不多都会取在二分之一到三分之一附近。
作者:不该相遇在秋天

















 605
605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









