



对齐值 alignas alignof
为了保证计算机系统检索速度,在数据存储时需要按照一定的“对齐值”来存放数据。
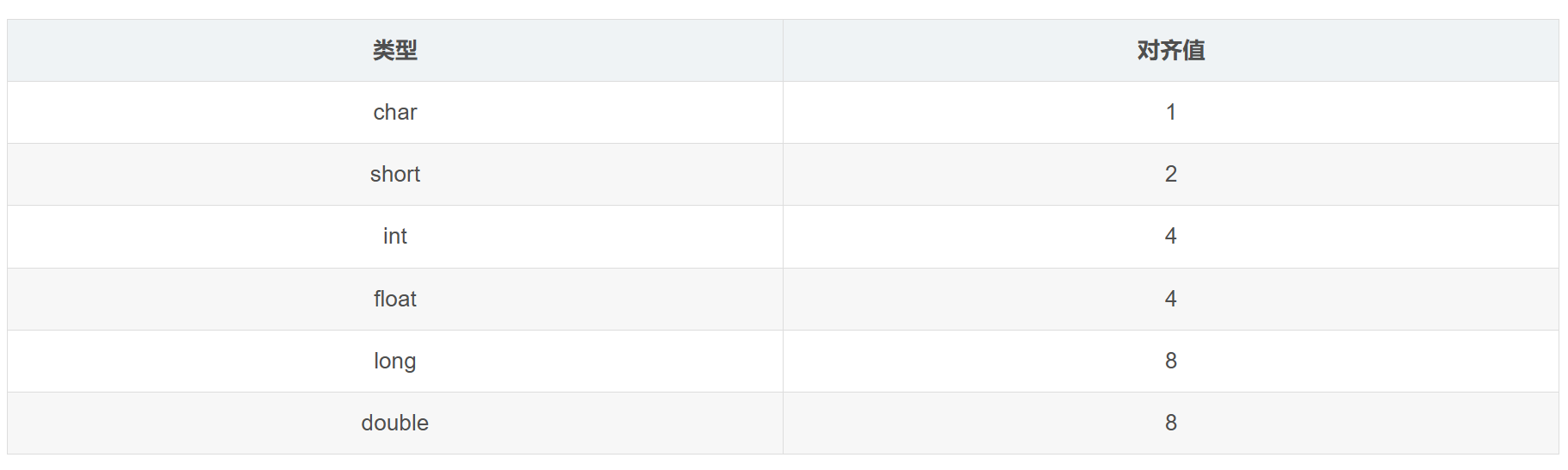
结构体中,对齐值默认是根据结构体中最大的数据类型来决定的。
但是在结构体中,如果内部有多个数据类型,几个数据类型加起来也占不满一个对齐格,那么就会共同占据该对齐格。
可以用这种方式指定对齐值
#pragma pack(1)
struct testPackOne
{
char data;
int len;
} testPackOneData;
std::cout << "alignof(struct):" << alignof(struct testPackOne) << std::endl;
#pragma pack()
struct alignas(8) testAlignas
{
char data;
int len;
} testAlignasData;
std::cout << "alignof(struct testAlignas):" << alignof(struct testAlignas) << std::endl;
对齐良好的数据兼顾了查询速度与内存消耗,过度对齐会导致空间浪费,紧凑对齐(对齐值为1)导致查询效率降低。
引用 指针
在把一个类作为传参时,优先使用引用,值传递会触发拷贝构造,效率低下,引用传递避免了拷贝开销,而且无需显示的解引用。
引用不允许空值,因为他的本质就是对于其他数据类型的一种同名指代;指针可以是空指针。
指针?
64位下指针占据八个字符,32位占据四个字符。
堆 栈
堆是需要在程序中自己显式的申请,而栈是OS自己分配的。
堆自己分配,是不连续的地址区域,用链表来存储(动态分区分配),因此内存空间受限于虚拟内存,所以比较灵活,但查找慢,会有难以利用的碎片。
栈是一块空间受限,但连续存储的区域,速度快,无碎片。一般存放传参、局部变量,这些数据在函数调用结束后会由程序自动清理。
数组名与指针
对于数组int a[10]和指针int *b,a是数组首元素地址,a+1就是第二个元素地址,b同理。
数组名跟指针的不同之处在于,数组名本身就是首元素地址,对数组名取地址也是首元素地址,而指针变量是指向首元素地址,对指针变量取地址就是另一个值了。
const static
static
- 局部变量:会被加载到内存的静态区,生命周期也将延续到程序的整个生命周期,也就是只会初始化一次。
- 类:程序中只会存在同一个类实例。
- 函数:函数作用域局限于文件内部,可以避免命名冲突。
- 全局变量:作用域局限于文件内部。
const - 变量:表示该变量是一个常量。
- 指针:有两种
const int* ptr = &x;//const修饰的是int*,这说明不可变的是指针,即:该指针无法指向其他地址。
int* const ptr = &x;//const修饰的是ptr,这说明不可变的是ptr,即:该指针指向了一个常量ptr,ptr无法修改,但指针可以指向其他地址。
- 成员函数:表示该成员函数不可修改成员变量
class MyClass {
public:
int x;
void print() const {//不可修改成员变量
std::cout<<x<<std:endl;
}
}
virtual
- 虚函数:在函数名前添加virtual关键字,表示该函数可以被orveride
- 虚析构函数:可以重写析构函数,否则只会调用基类函数的析构函数,这可能导致派生类资源清理不彻底。
- 纯虚函数:即抽象的虚函数,对函数体没有任何初始化。包含纯虚函数的类是抽象类,无法被实例化。
class AbstractClass {
public:
virtual void doSomething() = 0; // 纯虚函数
virtual ~AbstractClass() {}
};
class Implementation : public AbstractClass {
public:
void doSomething() override {
std::cout << "Implementation of doSomething." << std::endl;
}
- 虚基类:由于派生类继承基类时,其构造函数会默认调用基类的无参构造函数。但如果存在多重继承,那么最年轻的子类可能会调用很多次最年长的父类。可以在继承基类时使用virtual来表示继承虚基类从而避免这个问题。
#include <iostream>
class A {
public:
A() {
std::cout << "A constructor called.\n";
}
};
class B : public virtual A {
public:
B() {
std::cout << "B constructor called.\n";
}
};
class C : public virtual A {
public:
C() {
std::cout << "C constructor called.\n";
}
};
class D : public B, public C {
public:
D() {
std::cout << "D constructor called.\n";
}
};
int main() {
D d;
return 0;
}
值传递 指针传递 引用传递
- 值传递:传递效率较差,传的值不会更改。
- 指针传递:在该函数的栈区产生了一个指针指向该地址,效率较快。
- 引用传递:只是为该地址起了一个别名,效率较快。
野指针 悬空指针
- 野指针是在声明期并未初始化。
- 悬空指针是在初始化后所指地址被清理掉了。
inline define typedef
- typedef:给已经存在的数据类型起一个新名字。
- define:本质上就是一个在预处理阶段就完成的一个文本替换,并没有数据检查等。可以用于定义常量、定义函数、定义表达式等等。缺点就在于,单纯的文本替换可能导致:运算优先级导致的运算错误、无数据检查导致的编译错误等。
- inline:作用是通过内联函数的方式来代替函数调用,从而减少函数调用的开销。相比于#define,会有类型检查,也支持函数重载,因此更加灵活安全。
拷贝构造函数
- 拷贝构造函数的参数列表中,第一个一定是同类的引用,后续参数也需要默认值。
- 每个类会有默认的拷贝构造函数,会逐个复制非静态的变量到当前实例中。
- 对于普通变量会直接复制
- 对于指针类型会浅拷贝(但是很危险,建议深拷贝)
- 对于类数据会调用其拷贝构造函数
UML六种关系
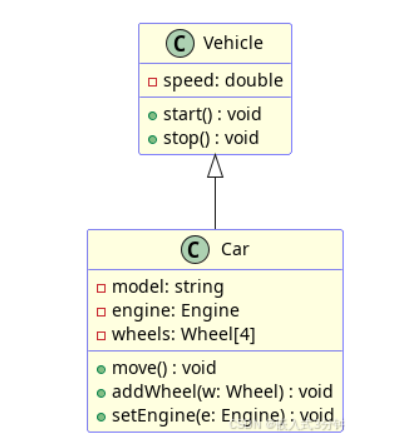
继承(泛化)
派生类继承了基类的成员变量与方法,也可以对方法进行重写或重载。
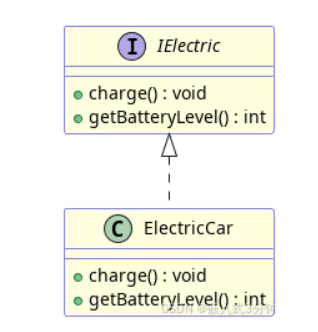
实现
派生类实现了接口(抽象类)中的纯虚函数。
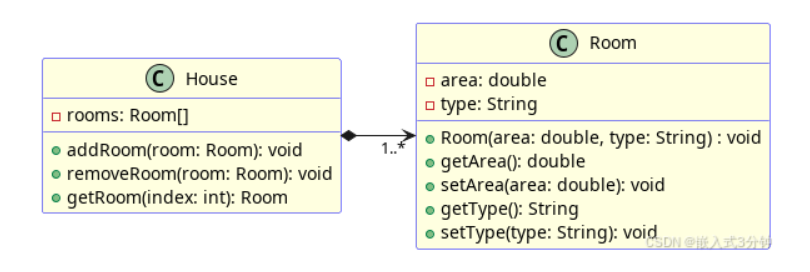
组合
侧重于整体与部分不可或缺,这是一种很强的关系。
1…*表示一个House可以有多个Room。
聚合
侧重于整体与部分独立存在,这是一种较弱关系。
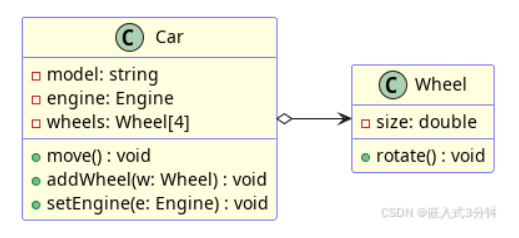
关联
常态下两个类是相关联的。一个类作为成员变量存在于另一个类。这是一种弱关系。
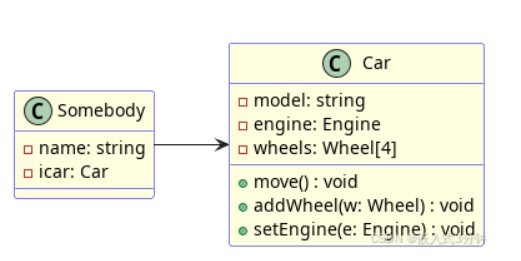
依赖
运行时临时有关。常常作为其中一个方法的参数存在,这是最弱的关系。
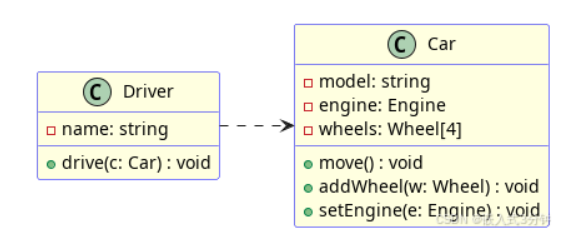
对象复用
为了节省创建对象带来的资源开销,可以采用享元模式(flyweight)。即有一个抽象的基类,若干派生类实现了基类的功能,有一个享元工厂类可以控制这些派生类的实例,当用户请求一个实例,工厂类就会从享元池中返回一个实例,如果请求的实例不存在,那么就会创建一个。比如数据库连接池。
零拷贝(没有理解好,不知道具体例子)
零拷⻉就是⼀种避免 CPU 将数据从⼀块存储拷⻉到另外⼀块存储的技术,可以减少数据拷⻉和共享总线操作的次数。
初始化列表
在构造函数体执行之前初始化成员变量,对于const常量和&引用,必须在初始化列表中初始化,在构造函数中无法赋值。
这种机制的核心优势在于它直接在构造函数的初始化阶段完成成员变量的初始化,而不是在构造函数体内进行赋值。(这个初始化阶段,跟调用该函数的阶段,差的很远吗?在两个阶段赋值有区别吗?)
ClassName::ClassName(parameters) : member1(value1), member2(value2) {
// 构造函数体
}
左值 右值 移动构造函数
赋值运算符左右的就是左值与右值。
在拷贝构造函数中,传入的指针类型默认是浅拷贝,但最好是能够深拷贝,这样就没有了悬空指针的风险,但这会占用更多资源。
拷贝构造函数的实参是左值,但倘若传入的实参是一个右值,或者将亡值,那么此时更加适合使用移动构造函数。或者此时传入的仍然是左值,但我们不希望深拷贝,不希望重新创建一个实例,那么我们可以std::move()将左值转换成右值并将其作为实参。
构造函数与析构函数能否是虚函数
构造函数不能是虚函数,因为虚函数需要类的实例的虚表指针得到虚函数表,从而调用虚函数,但如果没有经过构造函数就不会有实例,所以不能。
析构函数应该是虚函数,如果不是,那么派生类的析构函数只能清除基类的资源,这样是不合理的。


















 1378
1378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









